关于OpenAI的“o1-preview”的洞察
在之前的一篇帖子中,我总结了一期Lex Fridman播客节目,特邀嘉宾为Yann LeCun,主题是Yann LeCun: LLM的局限性,AGI和人工智能的未来。在节目中,LeCun讨论了大型语言模型(LLMs)的四个关键限制之一是它们无法进行层次规划。这是理解并与不同复杂程度的世界进行交互的关键技能。
LeCun指出,当前的LLM,如GPT-4,使用相同数量的计算,无论他们处理易或困难问题。另一方面,人类往往会在困难问题上花费更多时间。他预测未来的人工智能系统将在生成文本之前更谨慎地“思考”和策划他们的回应。他的愿景是让人工智能在推断过程中进行优化,而不仅仅是在训练过程中。
嗯,看起來OpenAI已經邁出了那方面的一步。上週,他們推出了他們的新o1-preview模型,旨在“在回答前花更多時間思考”。這一進步旨在改進人工智能推理和應對複雜任務的能力。讓我們深入了解o1-preview是如何工作的,以及為什麼這是一個如此重要的問題。
1. 人工智能训练的新方式:从简单回答到更好的推理
OpenAI的o1-preview模型引入了一种新的思考方式,即关注改进推理而不仅仅是给出正确答案的方式来训练AI。
- 范式 1:较旧的模型,例如 GPT-3,被训练成预测句子中的下一个词。它们可以生成流畅、自然的语言,但它们的推理能力有限。
- 范式2:通过ChatGPT(基于GPT-3.5),OpenAI引入了基于人类反馈的强化学习(RLHF),使模型更擅长提供帮助并避免有害或偏见的回应。
- 范式3:o1-preview模型将焦点转移到模型如何得出答案。它教导AI将问题分解成逻辑步骤,评估每一步,并完善其过程。这种方法特别适用于数学、编码和科学等学科,其中通向答案的步骤和答案本身同样重要。
举例: 如果您向像 GPT-3 这样的早期模型提问“32和58的和是多少?”,它可能会根据学习到的模式进行猜测。然而,o1-preview 模型会逐步解决这个问题:
- 步骤1:加上单位(2 + 8 = 10)。
- 步骤2: 加上十位数(30 + 50 = 80)。
- 步骤三:组合结果(80 + 10 = 90)。
这种方法能够更高概率地获得正确的结果,特别是对于更加复杂的问题。
2. 强化学习: 逐步教授人工智能思考
o1-preview 的一个突出特点是其使用强化学习(RL),帮助模型改善推理能力。该模型被训练为将问题分解成更小、更易管理的步骤,评估每一步,并验证其是否正确。这样,AI不仅仅生成一个可能的答案 - 它完全通过推理得出答案。
早期的模型如GPT-3依赖于庞大的数据集来学习。它们不断提升是因为看到了更多的例子。然而,o1-preview模型注重质量而非数量。它并不是不断地输入大量数据给模型,而是更多地教导它如何通过推理找到正确的解决方案。
使用强化学习,当模型做对事情时会得到奖励,当犯错时会受到惩罚。经过一段时间,这教导模型认真考虑其推理的每一步。这就好像训练AI更加谨慎和有条理。
例如: 想象一下,你让人工智能写代码。过去,该模型可能会一次性生成整个解决方案,然后希望一切顺利。现在,有了o1-preview,模型在进行下一步之前会仔细检查每一步。这减少了错误的几率,使人工智能更可靠。
3. "Aha"时刻:人工智能如何在推理方面变得更好
起初,OpenAI 的研究人员认为改善模型推理的最佳方式是向其提供人类撰写的推理步骤。这个想法是展示给人工智能如何通过问题思考,以便它可以从这些例子中学习。
但后来他们突破了。他们意识到,在训练过程中,当模型生成自己的推理步骤,并在这些步骤上进行强化学习微调时,实际上表现比在人类示例上训练得更好。这是他们的“啊哈”时刻:AI可以通过从自己的过程学习来教自己更好地推理。
这一发现使得OpenAI能在无需大量人工生成的推理数据的情况下扩大其推理改进规模,让模型变得更加强大。
4. 推理时间计算:让人工智能实时思考
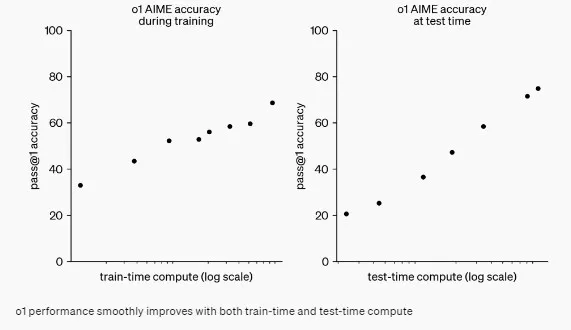
以下是事情变得非常有趣的地方。 o1-preview 模型可以实时调整其推理。 而早期模型会立即生成响应,o1-preview 需要稍作停顿,评估其思维过程,然后在做出响应之前加以改进。这种即兴思考的能力使其更加准确,尤其是在处理复杂问题时。只要它能够区分正确和错误的输出,性能就可以不断提高。
模型在任务上花费的时间越多,它的推理能力就越好。当然,这是有代价的 — 模型思考的时间越长,它就需要更多的计算力。因此,在准确性和效率之间存在一种权衡。
想象一下它就像是一个象棋引擎:它花费的时间越多来思考下一步棋,下棋的走步就很可能会更好。同样地,o1-preview模型可以通过花更多时间来思考多种推理路径来解决复杂任务。
5. 寻找平衡:为什么温度设定为1
OpenAI 将模型的温度设定为1。该参数控制模型回答的“创造性”程度。较高的温度会使人工智能更具创造力和更愿意冒险;较低的温度会使其更具可预测性和保守性。
在温度为1时,模型达到平衡。它探索多种解决方案,而不会固守第一个想法,但也足够专注丢弃错误答案。模型使用强化学习来完善正确推理步骤,确保其回答既有创意又准确。
6. 挑战:
即使有了这些进展,o1-preview模型仍然面临挑战。以下是两个关键领域它尚未克服的困难:
- 缺失信息: 如果模型被问及未经培训的内容,它可能会生成一个听起来自信但完全无关紧要的回答。这就好比向图书管理员要求一本不存在的书籍 — 他们会尽力帮助,但答案可能毫无意义。
- 模糊的领域:该模型在没有清晰的对与错答案的领域中也表现得很困难,比如个人写作或创意问题解决。由于它依赖于强化学习来验证正确性,它在“正确性”是主观的任务上遇到困难。
7. 保持优势:OpenAI 的竞争优势
OpenAI的o1-preview模型的一个关键优势是它保持思维链的私密性。在推断过程中,模型生成内部推理步骤,不与公众或竞争对手分享。这使OpenAI具有专有优势,因为它可以在保护基础过程的同时持续完善模型的推理。
此外,OpenAI 使用用户互动的数据来进一步调整模型的推理能力。随着更多用户使用该系统,它会学习和改进,创造出持续改进的循环。
8. 当前的局限性
尽管 o1 预览模型取得了进展,但仍然面临一些限制:
- 空间推理:该模型在需要理解物理空间或交互的任务上存在困难,比如预测物体移动的方式或描述机器中齿轮如何相互作用。
- 计算成本:推理时推理所需的计算增加了成本。这可能会限制模型的可扩展性,尤其是对于需要快速高效的实时应用来说。
9. 道德考虑: 我们能信任人工智能吗?
随着人工智能变得越来越自主和能够生成自己的推理步骤,这引发了关于透明度和问责制的问题。如果模型的思维过程变得过于复杂或模糊,那么很难理解它是如何得出某些结论的。
还有自主决策的问题。随着人工智能学会自行纠正错误,确保人类监督仍然存在以防止意外后果变得至关重要。在医疗或法律等领域,错误可能带来严重后果,保持人工智能推理的透明和控制至关重要。
10. 接下来是什么:o1模型的未来
展望未来,OpenAI 正在探索扩展 o1-preview 模型能力的方法。一个令人兴奋的研究领域是多模态推理,这将使 AI 能够将其推理技能应用于非文本数据,如图像或视频。
结论
OpenAI的 o1-preview 模型代表了人工智能推理方面的一大进步。通过改进模型处理问题的方式,利用强化学习,并实现实时推理,OpenAI已经树立了一个新的标准。虽然存在挑战,例如计算成本和特定领域的限制,但未来看起来很有希望。随着持续改进,o1-preview 可能会重新塑造人工智能如何应对许多行业中的复杂任务。