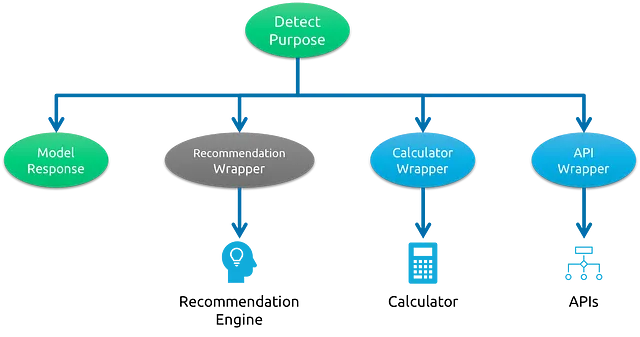
RAG
RAG或检索增强生成是一个长句,如果你把它拆分开来,就容易理解了,至少这是我理解它的方式。RAG有三个部分,检索,增强和生成。
首先让我们讨论一代或生成部分,它是LLM(大型语言模型)众所周知的例子包括ChatGPT,Llama等。为了理解生成部分,我们需要退一步了解这些LLM是在大量公开可用的数据上训练的,自从不像ChatGPT 3.5 turbo自2023年12月以来就没更新过了。仍然存在更多私人信息,LLM还没有看到,一个例子可能是您工作场所的人力资源政策或您公司的收入生成,因为这种信息是适合我们需求或足够敏感而不应在公开论坛上共享的。这导致LLM数据过时或记忆不足的问题,也缺乏信息的来源。当出现这种问题时,LLM会尝试创建一个看起来合适的答案,并让用户走进一个没有来源且过时,甚至与现实毫无关系的领域,这种自己创造的看起来真实的答案被称为幻觉。
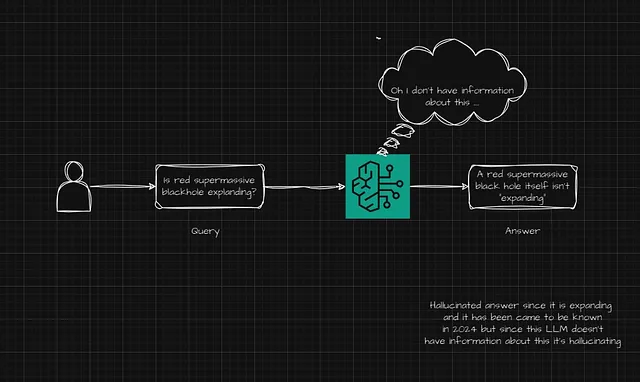
为了克服LLM的缺陷,有一种称为检索的方法,利用数据存储,如SQL数据库、NO-SQL数据库、向量数据库、pdf文件、音视频文件等数据,帮助改善LLM的上下文。
增强,检索到的文件被用作上下文或输入来增强生成模型。这些文件充当指南,提供事实、结构化或详细信息,模型在训练过程中可能没有学到。
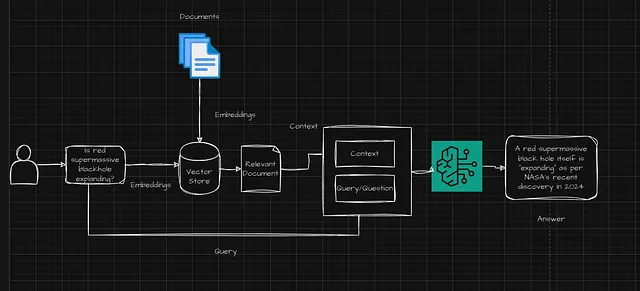
现在,如果我们结合RAG的三个部分,我们有了这种方法,我们协助LLMs产生答案,利用数据来源为LLMs提供上下文,并提供更新和事实信息,帮助LLMs产生更加真实和相关的答案。
希望这让你了解RAG,我将在未来深入探讨。若主愿。