使用LangGraph构建代理应用程序:第1部分 - 表格OCR代理
使用LangGraph和Tesseract OCR提取结构化格式的表格文本。
🦜🕸️语言图
LangGraph是一个设计用于构建具有大型语言模型(LLMs)的有状态多代理应用程序的功能强大库。与其他LLM框架不同,LangGraph提供独特的优势,如循环、可控性和持久性,使其成为基于代理的架构的理想选择。它允许开发人员创建具有循环和条件的工作流程,提供对应用程序流程和状态的精细控制。
LangGraph 证明是 LangChain 套件的一个强大补充,通过少量代码提供对代理应用程序非常精确的控制。我个人发现 LangGraph 是构建多代理应用程序的最适合的框架,其中一个主要原因是它为开发人员提供的控制级别,这是市场上其他框架(Autogen,crewAI)所没有的。但选择因人而异,我建议您尝试不同的框架,然后决定什么最适合您,现在,让我们开始使用 LangGraph 构建一个基本的代理应用程序。
范围
在本文中,我们将使用LangGraph构建一个基本的功能调用代理,这将帮助我们与包含表格数据的图像进行交互。我们将使用OCR(光学字符识别)从图像中提取文本,并构建自己的定制工具,然后我们的代理将使用该工具来回答用户的查询。
LangGraph — 关键概念
在其核心,LangGraph将代理工作流程建模为图形。您可以使用三个关键组件定义代理的行为:
- 状态:一个共享的数据结构,代表了应用程序的当前快照。它可以是任何Python类型,但通常是TypedDict或Pydantic基本模型。
- 节点:编码您的代理逻辑的Python函数。它们以当前状态作为输入,执行一些计算或副作用,并返回更新后的状态。
- 边缘:Python 函数根据当前状态确定要执行的节点。它们可以是条件分支或固定转换。
通过组合节点和边,您可以创建复杂的循环工作流程,随时间演变状态。然而,真正的力量来自LangGraph管理该状态的方式。需要强调的是:节点和边只不过是Python函数 - 它们可以包含一个LLM或者只是Python代码。
让我们一起做饭
首先,让我们安装所需的Python包。
%pip install --quiet -U langgraph langchain \
langchain_openai langchainhub langchain-community opencv-python pytesseract
一旦所有依赖项都安装好了,让我们继续初始化我们的OpenAI API密钥,因为我们将在这个示例中使用OpenAI llm。您也可以使用自托管的LLMs,但这不在本文的范围内,我们将在将来的文章中介绍。
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass("OpenAI API Key:")
自定义OCR工具
请注意:在继续之前,您需要安装tesseract,请使用以下安装指南:windows,mac
在该代理中的关键元素是OCR功能,我们将使用pytesseract创建自己的工具。
import pytesseract
import requests
from io import BytesIO
from PIL import Image
import cv2
import numpy as np
from langchain.tools import tool
pytesseract.pytesseract.tesseract_cmd = r'/opt/homebrew/bin/tesseract'
@tool
def ocr(image_url: str) -> str:
"""
Extract text from images using optical character recognition
inputs:
image_url: str (URL of the image from which text is to be extracted)
outputs: str (extracted text)
"""
response = requests.get(image_url)
img_array = np.asarray(bytearray(response.content), dtype=np.uint8)
img = cv2.imdecode(img_array, cv2.IMREAD_COLOR)
gray = cv2.cvtColor(img, cv2.COLOR_BGR2GRAY)
img = Image.fromarray(gray)
custom_config = "--oem 3 --psm 4"
text = pytesseract.image_to_string(img, config=custom_config)
return text
tools = [ocr]
pytesseract.pytesseract.tesseract_cmd 指定了 Tesseract 可执行文件的位置。
OCR工具故障。
- 获取图像:使用requests.get()从给定的URL下载图像。
- 转换为数组:将下载的图像数据转换为NumPy数组。
- 解码图像: 使用OpenCV将NumPy数组解码为图像。
- 将图像转换为灰度。
- 转换为PIL图像:将灰度图像转换为PIL图像格式。
- OCR 配置: 为OCR设置自定义 Tesseract 配置。
- 提取文本:使用 pytesseract 从图像中提取文本。
- 返回文本:返回提取的文本。
设置功能调用代理
from langchain import hub
from langchain.agents import create_openai_functions_agent
from langchain_openai.chat_models import ChatOpenAI
prompt = hub.pull("hwchase17/openai-functions-agent")
llm = ChatOpenAI(model="gpt-3.5-turbo-1106")
agent_runnable = create_openai_functions_agent(llm, tools, prompt)
现在,我们提取默认的openai函数提示,这非常好,并且在我们的使用情况下能很好地工作。您也可以编写自定义提示。
然后,我们定义了我们的llm,gpt-3.5-turbo在我们的使用案例中足够了,并最终使用langchain的内置模块初始化我们的代理可运行,并传入我们的工具数组,llm和提示。
定义图形状态
图形状态是一个包含必要信息(状态变量)的对象,在代理执行链中,它可以被比作数据传输对象,通过链的各个阶段传递,以便提供易于访问变量的便利。
import operator
from typing import Annotated, TypedDict, Union
from langchain_core.agents import AgentAction, AgentFinish
from langchain_core.messages import BaseMessage
class AgentState(TypedDict):
input: str
chat_history: list[BaseMessage]
agent_outcome: Union[AgentAction, AgentFinish, None]
intermediate_steps: Annotated[list[tuple[AgentAction, str]], operator.add]
- 这是代表用户的主要问题输入字符串,作为输入传递进来。
- 聊天记录:这是任何以前的对话消息,也作为输入传递进来。
- 中间步骤:这是代理人随时间采取的行动和相应的观察列表。这在每次代理迭代时更新。
- agent_outcome: 这是代理的响应,可以是AgentAction也可以是AgentFinish。当这是AgentFinish时,代理执行程序应该结束,否则应该调用请求的工具。
定义图节点
现在我们需要在图中定义几个不同的节点。在langgraph中,一个节点可以是一个函数或可运行的。我们需要的主要节点有两个:
- 代理商:负责决定要采取什么(如果有的话)行动。
- 一个调用工具的功能: 如果代理人决定采取行动,那么该节点将执行该行动。
from langchain_core.agents import AgentFinish
from langgraph.prebuilt.tool_executor import ToolExecutor
tool_executor = ToolExecutor(tools)
def run_agent(data):
agent_outcome = agent_runnable.invoke(data)
return {"agent_outcome": agent_outcome}
def execute_tools(data):
agent_action = data["agent_outcome"]
output = tool_executor.invoke(agent_action)
return {"intermediate_steps": [(agent_action, str(output))]}
# Define logic that will be used to determine which conditional edge to go down
def should_continue(data):
if isinstance(data["agent_outcome"], AgentFinish):
return "end"
else:
return "continue"
我们现在已经定义了组成我们图形的三个节点:1. run_agent:这基本上是对具有输入数据的LLM的调用。
2. execute_tools: 此函数使用langchain的工具执行器来调用我们的工具,并使用LLM提供的输入参数。
3. should_continue:此函数检查代理是否已返回完成的响应,然后相应地决定结束链条或继续.
放置图表
我们的应用程序的流程会是这样的:
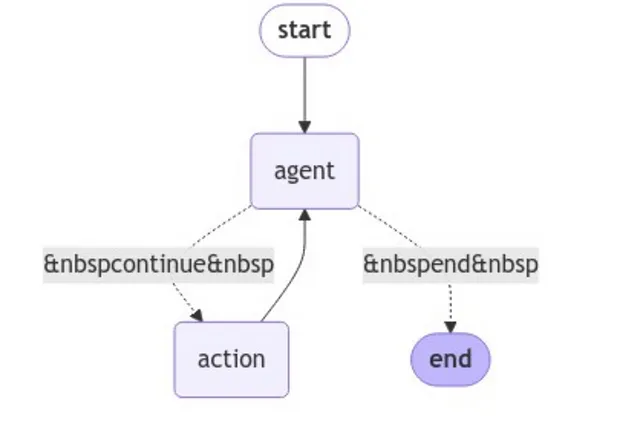
- 输入数据发送到代理节点。
- 代理人决定要采取的行动(调用/结束)
- 如果有一个工具调用,我们执行execute_tools函数,如果没有,我们结束循环。
- 直到代理返回完成的响应为止。
from langgraph.graph import END, StateGraph, START
# Define a new graph
workflow = StateGraph(AgentState)
# Define the two nodes we will cycle between
workflow.add_node("agent", run_agent)
workflow.add_node("action", execute_tools)
workflow.add_edge(START, "agent")
# We now add a conditional edge
workflow.add_conditional_edges(
"agent",
should_continue,
{
"continue": "action",
"end": END,
},
)
workflow.add_edge("action", "agent")
app = workflow.compile()
在上面的代码中,我们定义了一个条件边界,一个条件边界基本上是一个if-else条件,这种情况下,我们获取代理响应,将其通过should_continue函数,如果should_continue的响应是'继续',我们执行动作节点(即工具执行节点),否则我们结束循环。
让我们用一张图片来尝试一下。
在这个例子中,我们将使用一张显示NBA西部联盟排名的表格图片。这是一张基本的表格图片,将用于测试我们的应用程序。可以自由选择任何表格图片,可以是收据、记分卡等等。
现在我们将请我们的代理人将这个表格图像转换成结构化的json格式。让我们看看它的表现如何!
input_text = """Convert the table in the given image to a structured json format:
{image_url}"""
image_url = "https://qph.cf2.quoracdn.net/main-qimg-33cb892065ba986551e7532296f6ca5e"
inputs = {"input": input_text.format(image_url=image_url), "chat_history": []}
resp = app.invoke(inputs)
print(resp['agent_outcome'].return_values['output'])
这是输出结果:
{
"Western Conference": [
{
"W": 50,
"L": 11,
"PCT": 820,
"GB": "-"
},
{
"W": 46,
"L": 13,
"PCT": 780,
"GB": "3"
},
{
"W": 43,
"L": 19,
"PCT": 694,
"GB": "7.5"
},
{
"W": 37,
"L": 24,
"PCT": 607,
"GB": "13"
},
{
"W": 36,
"L": 24,
"PCT": 600,
"GB": "13.5"
},
{
"W": 36,
"L": 25,
"PCT": 590,
"GB": "14"
},
{
"W": 35,
"L": 26,
"PCT": 574,
"GB": "15"
},
{
"W": 28,
"L": 33,
"PCT": 459,
"GB": "22"
},
{
"W": 25,
"L": 35,
"PCT": 417,
"GB": "24.5"
},
{
"W": 25,
"L": 36,
"PCT": 410,
"GB": "25"
},
{
"W": 25,
"L": 36,
"PCT": 410,
"GB": "25"
},
{
"W": 24,
"L": 36,
"PCT": 400,
"GB": "25.5"
},
{
"W": 24,
"L": 37,
"PCT": 393,
"GB": "26"
},
{
"W": 19,
"L": 42,
"PCT": 311,
"GB": "31"
},
{
"W": 19,
"L": 42,
"PCT": 311,
"GB": "31"
}
]
}
这真是令人印象深刻!
我们得到了我们需要的结构化输出,尽管有一些错误,例如PCT列应该有小数值,但这是因为OCR工具,我们可以改善OCR准确性并增强这个代理。
结论
在我们LangGraph系列的第一部分中,我们建立了一个基本的代理工作流来从图像中提取和阅读表格文本。我们研究了LangGraph的关键概念,如节点、边、条件边和状态,并使用这些概念创建了一个函数调用代理。此外,我们还建立了一个自定义工具,使用tesseract OCR从图像中提取文本。
在未来的文章中,我将深入研究使用Langgraph的代理人工智能,并涵盖诸如多智能体工作流程、复杂的代理设计模式等概念。
在 LinkedIn 上与我联系,您的建议将非常受欢迎!
Primastat
如果您希望在您的公司实施Gen-AI应用程序,并正在寻找专业人士来构建复杂系统,请不要再继续寻找!
在Primastat,我们致力于为各个领域提供高质量的基于数据驱动的人工智能解决方案,从调整LLMs到Agentic AI应用。我们为市场营销、医疗保健、法律和金融科技等多个领域提供服务。
发邮件给我们 connect@primastat.in 或者通过我们的社交媒体联系我们:
- X
- 领英
参考资料
- LangGraph 文档