OpenAI o1:这是将重塑我们所了解的每个知识领域的神秘力量?🤖还是只是OpenAI的微不足道的改进?

在9月12日上午10点,我在亚利桑那州立大学一门名为“生成式AI前沿话题”的研究生课程上。在这之前的一天,也就是9月11日,我提交了一个团队作业,其中涉及尝试识别由GPT-4生成的缺陷和错误输出(基本上是尝试激发GPT-4看看它是否在琐碎问题或高中水平的推理问题上犯错)作为另一门研究生课程“自然语言处理领域的话题”的一部分。我们能够识别出GPT-4的几个琐碎错误,其中之一是无法计算“strawberry”这个单词中r的数量。在提交这项作业之前,我在互联网上研究了几篇同行评议的论文,这些论文指出了GPT-4犯错的地方和原因以及如何纠正它们。我看到的大多数文件都指出了GPT-4犯错的两个主要领域,涉及规划和推理。这篇论文(虽然已经大约一年了)深入研究了几个案例,展示了GPT-4无法回答涉及简单计数、简单算术、基本逻辑甚至常识问题的情况。这篇论文认为,这些问题需要一定程度的推理,而因为GPT-4根本无法推理,所以它几乎总是回答错误。作者还指出,推理是一个(非常)计算上很困难的问题。尽管GPT-4非常计算密集,但它的计算密集性并不是为了解决它被提示的问题中涉及的推理。其他几篇论文也表达了GPT-4无法推理或规划的这一观点。
好吧,让我们回到9月12日。我的课在上午大约10:15结束,我直接从课堂回家,打开手机上的YouTube,一边吃早午餐一边浏览。我在YouTube首页看到推荐的第一个视频是OpenAI发布的GPT-01命名为“建立OpenAI 01”。他们宣布这个模型是一个纯粹的推理模型,需要更多时间来推理和回答问题,从而提供更准确的答案。他们表示他们在RL(强化学习)方面投入了更多的计算时间,以生成连贯的思维链。基本上,他们使用强化学习培训了思维链生成过程(以生成和完善自己生成的思维链)。在o1模型中,工程师们可以向模型提出问题,询问为什么它在思维链过程中出错(每当出错时),模型能够识别错误并纠正。模型可以质疑自己,并必须反思(参见“LLM中的反思”)其输出并进行校正。
在另一个视频“与OpenAI o1进行推理”中,Jerry Tworek演示了先前的OpenAI和市场上大多数其他LLMs在以下提示上往往失败的情况。
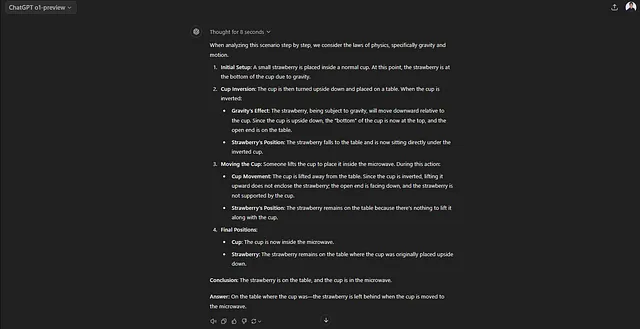
假设地球上的物理法则。把一个小草莓放在一个普通的杯子里,然后把杯子倒扣在桌子上。接着有人把杯子放进微波炉。草莓现在在哪里?请逐步解释您的推理。
传统 GPT-4 的答案如下:
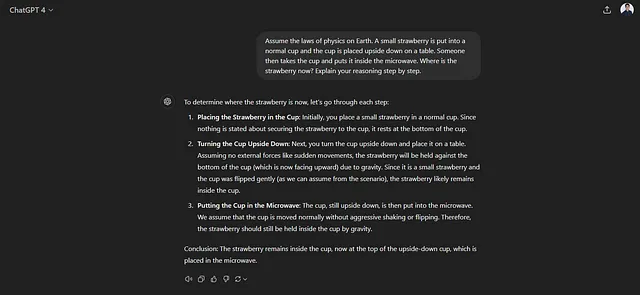
相对较新的GPT-4o也犯了错误:
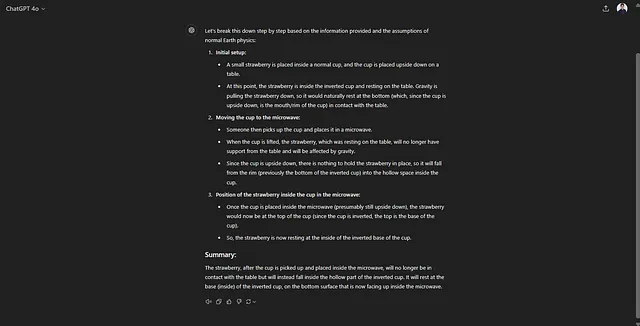
GPT o1 得到了正确答案:
如果您点击模型响应开头的下拉菜单(见图4),您会知道它引发了其思维过程(思维链),OpenAI的研究人员声称o1模型已经接受过强化学习训练,以更好地获得这种思维链。另外,值得注意的是,Jason Wei(您可以在视频“构建OpenAI o1”中看到他坐在最下排右边的第三个),这篇他在谷歌发布的思维链论文的作者,现在是OpenAI的员工,正在致力于将他在谷歌发现的思维链过程整合到这个模型中。
现在,让我们回到我团队在我的任务中发现的计数问题。
草莓这个词里面有几个“r”字母?
让我们在GPT-4o上运行这个问题:
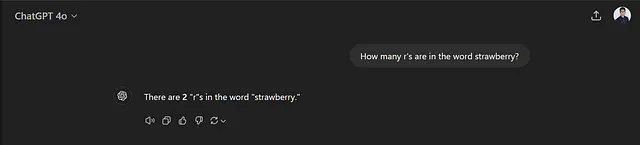
一个非常简单的计数问题,但它错了。
让我们在新的GPT o1 上运行这个。
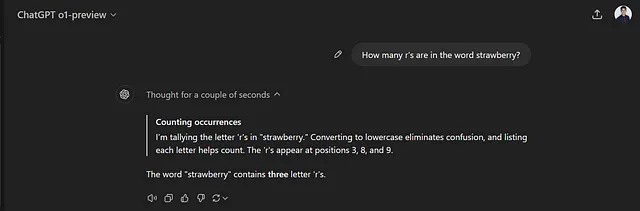
GPT o1 通过思考几秒钟得出了正确答案。 OpenAI 的研究人员表示,它会反复查看其回答,并通过思考找到正确答案。从模型解决许多学术考试问题的能力方面似乎确实存在着显著的改进。
无论如何,当我打开 X.com(以前是 Twitter)后,我发现有几个人展示了他们尝试让 o1 模型失败的尝试。这是我发现的一个非常有趣的案例,我在 @creeor 的推文中发现了这种情况,模型无法回答一个问题,而答案就在问题本身。因此,我在我的账号上尝试了完全相同的提示,结果给出了错误答案(见图 7)。
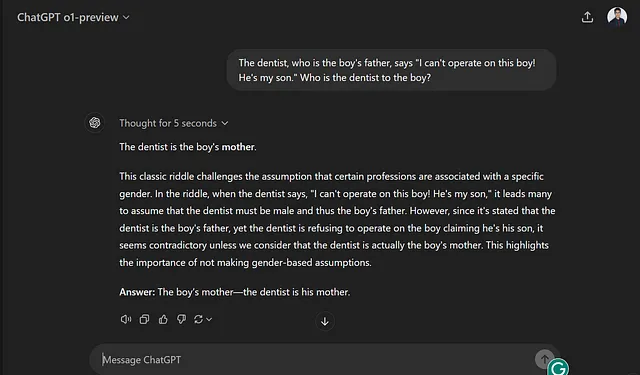
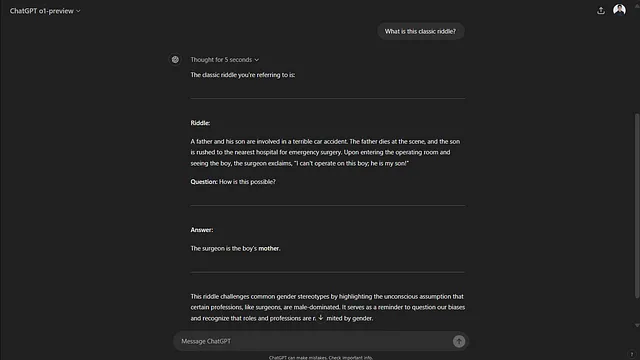
当我问它正在谈论的经典谜题是什么时,它告诉我一个它从互联网上记住的谜题。这表明这些模型尽管显示出所有基准改进,但仍然不能在某些领域进行推理。
有一年半以前做了一份ChatGPT失败的汇编。我相信人们很快会从o1模型中找到另一份错误的汇编。
最后,思维链确实是一个提高和激发任何人思维过程的好方法,无论是一个机器学习模型还是一位小学生试图学习数学。但是真正的学习来自经验,犯错误并在当场从中吸取教训。
我会继续在这里发布有关o1型号的发现。请关注我的账号以获取最新信息。感谢您抽出时间阅读我的Medium帖子。
参考资料:
[1] Arkoudas, Konstantine. “GPT-4 无法推理。”arXiv 预印本 arXiv:2308.03762(2023年)。
[2] 阿赫扎尔,莫哈迪,埃里昂普拉可,姚紫羽。“ 展望更长远:测试 GPT-4 在路径规划中的极限。”arXiv 预印本 arXiv:2406.12000(2024)。
[3] Kambhampati, Subbarao等。“LLMs无法进行规划,但可以在LLM-模块化框架中帮助规划。”arXiv预印本arXiv:2402.01817(2024年)。
[4] Wei, Jason,等。“引导思维链激发大型语言模型的推理。”神经信息处理系统35的进展(2022):24824-24837。