AI检测器:偏向以英语为母语者的偏见的伦理困境
因此,学术界面临着有史以来最大的挑战!
生成语言模型的兴起,如ChatGPT,展示了它可达到的无限可能。对于抄袭,我们建立了工具来匹配其他内容中的单词,但是有了AI,机器人已经包含了重新排列单词以克服检测的能力。基本上,人类也遵循这种方法,并经常复制粘贴和改写。因此,AI机器人正在做人类在写作文章中所做的事情,但它们实际上非常擅长以逻辑方式陈述答案。
面对非英语母语的写作人
在一篇新的论文[1]中,研究团队调查了母语英语和非母语英语写手的写作样本,发现AI检测器经常将非母语英语写手的作品分类为由AI生成的。

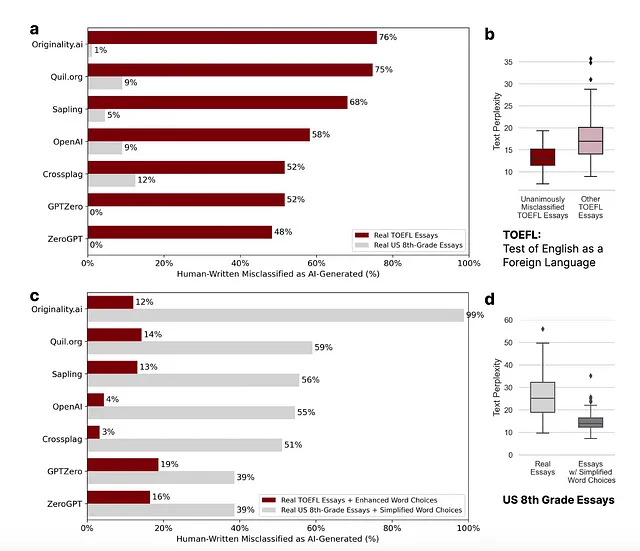
本地英语写手通常被准确判定为非AI生成的。我们可以看到在图1中,研究者使用了Orginality.ai、Qull.org、Sapling和OpenAI等工具来识别人类写作的作品。从(a)中可以看出,超过一半的非本地作者的托福(外语考试)被错误地识别为“AI生成的”,但对于美国8年级的文章来说错误率较低。Orginality.ai对非本地英语使用者的误分类率为76%,而对于本地英语使用者仅为1%。
克服偏见
在图1(c)中,选择了“增强单词选择以更像母语人士” 的ChatGPT提示,我们看到它减少了AI生成文本的误分类(红条),但是“增强单词选择以更像母语人士”显着增加了误分类(灰条)。
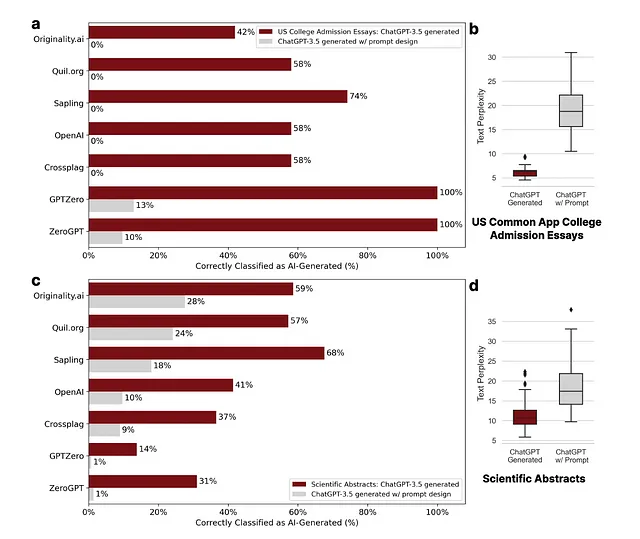
研究团队随后查看了美国大学入学论文和科学摘要(图2)。再次,红色条显示在没有ChatGPT提示的情况下,存在高水平的误报,但是当使用“通过使用文学语言提高提供的文本”的提示时,这种情况显著减少。通过(c),我们发现“通过使用高级技术语言提高提供的文本”的提示会导致检测率下降。
结论
这是一个变革时代。使用AI工具检测AI生成在当前时间内并不是一个明确定义的科学。对于学者来说,“你只是欺骗了你自己”并不是回答我们在评估学生作品时面临问题的重要性的答案。
参考资料
[1] Liang,W.,Yuksekgonul,M.,Mao,Y.,Wu,E.,& Zou,J.(2023)。GPT探测器对非英语母语写作人有偏见。arXiv预印本arXiv:2304.02819。
订阅:https://billatnapier.medium.com/membership