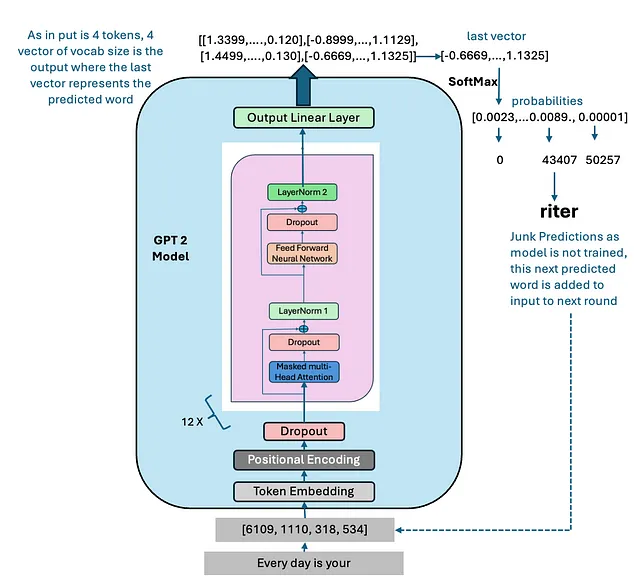
GPT-o1(GPT5)由OpenAI进行了详细审查
OpenAI的项目Strawberry拥有博士学历水平的智能。

所以,GPT-5又称为项目草莓,又称为GPT-o1,又称为OpenAI的博士水平LLM,现在发布了。自几个月以来一直有很多关注,鉴于其结果,它达到了预期。OpenAI-o1是一系列模型,旨在增强在科学、编码和数学等复杂领域的问题解决能力。
这里有一些要注意的关键特点:
增强推理能力
- 彻底的问题解决:o1模型被设计为在作出回应之前花费更多时间“思考”,从而模仿人类推理。这使得它们能够比之前的版本,如GPT-4,更有效地处理复杂任务。
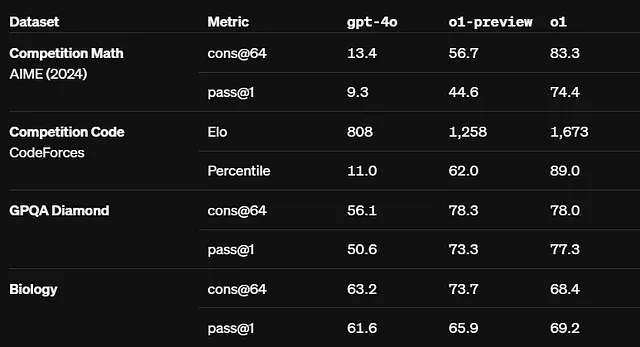
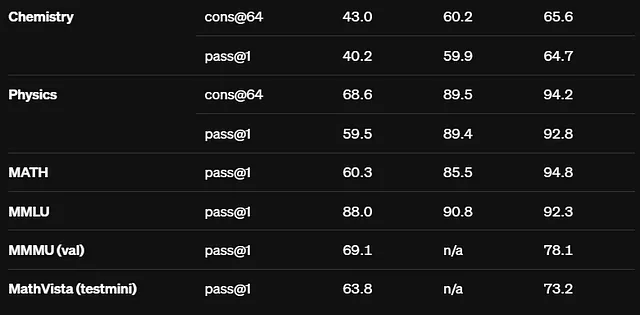
- 基准性能:在评估中,o1模型在具有挑战性的任务上表现出优异的性能,在物理、化学和生物等领域取得了与博士生可比较的成果。例如,
o1模型在国际数学奥林匹克资格考试中取得83%的分数,明显优于仅得到13%分数的GPT-4o。
安全与调整
- 提高安全培训:OpenAI已经开发了一种新的安全培训方法,利用模型的推理能力更有效地遵守安全和对齐准则。
o1模型在越狱测试中得分84分,表明其在压力下遵守安全规则的能力强大,而GPT-4o的得分为22分。
目标应用程序
- 特定使用情况:o1型号对需要复杂问题解决能力的专业人士特别有益,例如分析细胞测序数据的医疗研究人员和为量子光学开发复杂数学公式的物理学家。
模型变体 (o1-mini 和 o1-preview)
- OpenAI o1-mini:除了o1-preview模型之外,OpenAI还发布了o1-mini,这是一种更高效、更具成本效益的变体,专门为编码任务设计。它比o1-preview模型便宜80%,这使得它成为开发人员需要推理能力但不需要广泛世界知识的吸引人选择。
可访问性
- 用户访问: o1模型目前可供ChatGPT Plus和Team用户使用,未来将计划扩大对ChatGPT Enterprise用户的访问。开发人员可以通过API使用这些模型进行原型设计,尽管目前尚未包括某些功能,如函数调用和流式传输。
- 很快将提供o1-mini的免费访问。
在核心处的强化学习
他们的强化学习算法训练模型有效思考,通过增加训练和思考时间来提高性能。他们正在探索如何扩展这种方法,这与预先训练大型语言模型(LLMs)的扩展挑战有很大的不同。关于这个问题没有提供太多信息(OpenAI作为OpenAI)。
谈一些比较和度量标准
重要里程碑
- Codeforces(竞技编程):一个用于竞技编程的平台,参与者在定时比赛中解决算法问题。 o1在排名中位于89百分位,展示了其在时间限制下处理复杂算法的能力。
- 美国数学奥林匹克竞赛(AIME):这是一项针对美国高中学生的著名数学比赛,参与者通过美国邀请性数学考试(AIME)获得资格。o1在这一精英比赛中跻身前500名学生之列,展示了高级问题解决能力。
- GPQA基准:一个旨在评估模型在研究生水平物理、生物和化学问题上的基准。 o1超过人类博士水平的准确性,突显其对高级学术问题的深刻理解和解决能力。
- MMLU基准:大规模多任务语言理解(MMLU)基准测试模型在各种学术和专业领域的知识和推理能力。具有视觉能力,o1在57个类别中的54个中取得了78.2%的得分,并在54个类别中表现优异,表现出出色的多任务学习能力。
这太多了
结束前,
在GPT-01中如何使用思维链?
思维链是一种启发性工程技术,使LLM在输出之前思考。就像一个人在回答问题之前可能会花时间深思熟虑一样,o1在解决问题时遵循一条结构化的推理路径。以下是它的工作原理:
- 强化学习:o1通过从试错中学习来发展和改进推理能力。通过这一过程,模型随着时间的推移不断完善其思维策略。
- 错误识别和更正:当 o1 处理问题时,它变得更擅长识别自己的错误并进行更正,类似于人类重新考虑有缺陷的方法。
- 分解复杂问题:人们学会将具有挑战性的任务分解成更简单、更可管理的步骤,从而更容易找到正确的解决方案。
- 调整策略: 当模型当前的方法不起作用时,它可以切换策略,尝试不同的方法以更有效地解决问题。
但是,我们也有一些限制,这些限制我们在下面的帖子中详细介绍了。
我刚刚测试了这个模型,看起来强大无比。我希望所有这些数字都是真实的,而不是OpenAI先前的SORA或SearchGPT那样的阴谋论。