演化的GPT模型,从GPT 1到GPT 4
解码器仅变压器(GPT 1,GPT 2,GPT 3和GPT 4)
开放AI的生成式预训练变压器(GPT)模型已经彻底改变了自然语言处理(NLP)领域。GPT模型通过执行文本生成、问答、摘要等各种任务,创造了NLP领域变化多样的新标准,而无需进行特定任务的监督训练。
GPT模型真正突出的地方在于它们能够在很少的输入数据的情况下表现出色,通常只需要很少的示例甚至没有。这种品质被称为少样学习甚至是零样学习,使得GPT模型能够在训练过程中从未遇到的任务上进行泛化。

在这篇文章中,我们将探讨GPT模型的发展,讨论它们如何推动了自然语言处理领域的发展。
- 引入了GPT-1的开创性概念,奠定了大规模预训练语言模型的基础。
- GPT-2所取得的一大飞跃展示了无监督多任务学习的潜力。
- GPT-3 的显著改进通过其少样本学习能力设立新的标准。
- 最新的里程碑 GPT-4 扩展了更多的功能,进一步提高了安全性、可控性、多语言理解能力,以及处理和推理复杂数据的能力。
- 最后,我们将了解GPT模型的每个组成部分,并根据《从零开始构建一个大型语言模型》这本书的启发来构建一个。
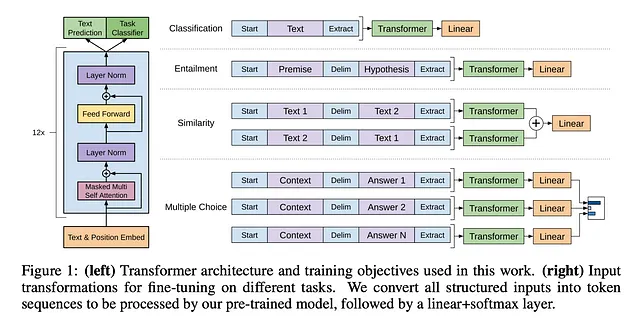
1. GPT-1:为生成式预训练打下基础
在2018年,OpenAI推出了生成式预训练变压器1(GPT-1),在论文《通过生成式预训练改善语言理解》中描述。这个模型标志着自然语言处理(NLP)的一个重要转变,通过展示大规模、无监督的预训练,然后针对特定任务的NLP应用进行微调的潜力。在GPT-1之前,大多数最先进的模型都是以监督方式训练的,这需要大量有注释的数据,用于每个特定任务,比如情感分类、问题回答和文本蕴涵。 GPT-1通过展示一个生成式语言模型,在未标记的数据上进行预训练,可以在最小任务特定监督的情况下横跨各种NLP任务。
关键概念
GPT-1引入了半监督学习方法,包括两个阶段:
- 无监督预训练:该模型首先在大规模文本语料库上作为语言模型进行训练,以学习自然语言的结构和模式。这个阶段涉及在序列中预测下一个单词,并把握单词关系和句法规则的深刻理解。
- 监督微调:在预训练后,模型在特定的NLP任务上使用较少的标记数据集进行微调。这个阶段最大化了在输入序列给定目标标签(例如情感或分类标签)的可能性。这里的关键区别在于,模型不是从零开始训练,而是利用了在预训练期间获得的通用语言知识。
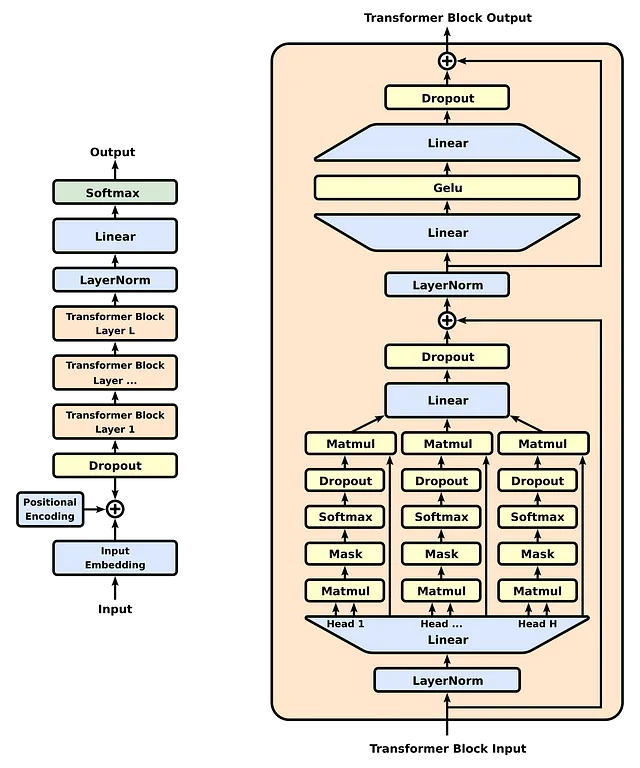
模型架构和数据集:
GPT-1具有12层仅解码器的transformer架构,具有掩码自注意力,直接构建在Vaswani等人首次引入的transformer模型上。掩码确保模型只能关注序列中的先前标记,使其能够基于先前的上下文生成文本。
关键的建筑特色:
- 每个层中有12个注意力头的12个变换器层。
- 一个768维的状态用于标记嵌入和位置编码。
- 在前馈层中有3072维的隐藏状态。
- 字节对编码(BPE)字汇,使用40,000次融合。
- 正则化技术,如0.1的dropout和修改后的L2正则化。
- 使用Adam优化器进行训练,学习率为2.5e-4,在64大小的小批量数据上进行100个时期的训练,序列长度为512个标记。
数据集:该模型在BooksCorpus数据集上进行了预训练,该数据集包含7,000本未发表的书籍。这个数据集提供了长段连续文本,使得模型能够学习长距离依赖关系——这是比更小、更分散的数据集更具优势的地方。对于监督微调,GPT-1仅需要很少的纪元数(通常只需三个纪元)就能在各种自然语言处理任务上实现高性能。这种高效性突显了无监督预训练阶段的力量,模型在那里已经学习到了一般的语言模式,仅需要进行一些少量调整以实现特定任务的目标。
表现和成就
GPT-1 的性能超出了预期,在 GLUE 基准测试的 12 项任务中,其中 9 项的表现超过了许多任务特定的监督模型。值得注意的是,这个模型在诸如问答、情感分析和结构解析等任务上展示出了令人印象深刻的零-shot 表现,而无需任何任务特定的微调 — 这是对该模型后来定义的 GPT-2 和 GPT-3 的强大泛化能力的早期迹象。
- 跨越多项任务的概括:GPT-1证明了一个预先训练的生成式语言模型可以通过最小的额外训练进行微调,用于各种下游任务。
- Few-shot 和 zero-shot 能力:虽然 GPT-1 需要微调,但其架构为后续模型奠定了基础,使其在特定任务训练期间表现更好,即使只有更少或没有示例。
- 效率: 该模型表明,无监督的预训练可以使模型更具数据效率,减少在每个任务中对大型注释数据集的需求。
2. GPT-2:无监督多任务学习和规模的力量
在GPT-1取得成功之后,OpenAI于2019年发布了GPT-2,该论文描述了“语言模型是无监督多任务学习者”。GPT-2在其前身的基础上进行了扩展,通过增加模型的尺寸和数据规模。
主要概念
- 任务调节和多任务学习:GPT-2引入了无监督多任务学习的概念,通过将模型调整为处理具有相同架构的多个任务。与要求为每个任务分别建立模型不同,GPT-2的训练目标基于一般形式P(输出|输入,任务),使模型能够根据手头的任务生成不同的输出。这为零次学习任务转移奠定了基础,使模型能够执行任务而无需特定的微调。
- 零样本学习和任务迁移:GPT-2的一个突出特点是其零样本学习能力。该模型能够解释自然语言中的任务说明,并生成翻译、总结和问答等任务的答案,而无需查看这些任务的明确训练示例。这一突破使得GPT-2具有高度的多功能性,并展示了无监督语言模型对多任务学习的潜力。
模型结构和数据集:(稍后我们将实现GPT-2的最小版本)
GPT-2 的模型大小和复杂性都显著增加:
- 它有1.5亿个参数,比GPT-1的1.17亿个参数大大增加。
- 该架构使用48层,1600维嵌入,并且有一个更大的词汇表,包含50,257个标记。
- 上下文窗口增加到1024个标记,使模型能够处理更长的文本序列。
这些升级导致在各种任务中获得更优越的性能,特别是在零样本设置中。此外,架构更改,如层归一化和权重缩放,提高了模型的稳定性和训练效率。
- 层归一化被移动到每个子块的输入,在最终的自注意力块之后添加了额外的层归一化。
- 权重缩放:剩余权重通过1/√N进行缩放,其中N为剩余层数的数量,从而改善模型的稳定性。
- 该模型是使用字节对编码(BPE)进行训练的,这有助于更有效地处理罕见和词汇外的单词。
为了测试缩放的影响,OpenAI训练了多个版本的GPT-2,包括具有117M(与GPT-1相同)、345M、762M和1.5B参数的模型。每个更大的模型表现出比较小的模型更低的困惑度(一种语言模型不确定性的度量),从而加强了通过扩大参数提高模型性能的想法。
数据集:WebText- 为支持GPT-2的训练,OpenAI引入了一个更大、更多样化的数据集,名为WebText,包含来自Reddit上高质量内容的800万篇文档共约40GB的文字。这个数据集提供了更广泛的语言结构范围,使GPT-2能够更深入地理解语言。值得注意的是,为避免与共同的测试集重叠,维基百科内容被删除了。
表现和成就
- 它在8个语言建模数据集中的7个上取得了最先进的结果,明显优于以前的模型,特别是在需要理解长距离依赖的任务中,比如LAMBADA数据集评估的任务。
- 在儿童图书数据集(CBT)中,GPT-2 提高了常见名词和命名实体识别的准确性,突显了其把握单词类别的能力。
- GPT-2在阅读理解任务和从法语到英语的零次翻译中表现良好,尽管它没有超越最先进的监督翻译模型。
最重要的是,GPT-2展示了模型大小和性能之间的对数线性关系:随着参数数量的增加,模型的困惑度(语言建模中不确定性的度量)持续减少。这一观点突显了比例放大的力量,并导致了诸如GPT-3之类的更大型号模型的发展,进一步拓展了语言理解的范围。
3. GPT-3:少样本学习及规模的力量
随着GPT-2的成功,OpenAI在2020年推出了GPT-3,其在论文“语言模型为少样本学习者”中有所描述。GPT-3将模型规模扩大到了1750亿个参数,使得该模型能够在零样本和少样本学习场景中执行复杂任务,而无需进行特定任务的微调。
关键概念
- 在上下文学习:GPT-3引入了强大的概念——上下文学习,在这种学习中,模型可以根据输入上下文中嵌入的指示或示例执行任务。在不改变模型参数的情况下,GPT-3可以在不同任务间推广其理解能力。当仅仅提供几个示例或指示时,该模型可以模仿其在训练中学到的类似数据的模式,从而使其能够执行以前从未明确遇到过的任务。
- 少样本学习、单样本学习和零样本学习:在GPT-3中,少样本学习指的是为模型提供一些任务示例以引导其响应,而单样本学习仅涉及一种示例,零样本学习意味着模型被期望在没有任何示例的情况下执行,仅依赖于任务说明。GPT-3的大量参数使其在这些设置中表现出色,使其在各种应用中具有多功能性。
模型架构和数据集:
GPT-3 在其前身 GPT-2 的基础上继续构建,但规模得到了显着扩大:
- 1750亿个参数分布在96层,每层有96个注意力头。
- 词嵌入向量的维度已经扩展到了12,888维,相较于GPT-2的1,600维。
- 上下文窗口的大小从1,024个token (在GPT-2中)增加到了2,048个token,在GPT-3中,这使得模型能够处理更长的输入序列。
- 模型使用具体超参数(β₁ = 0.9, β₂ = 0.95, ε = 10⁻⁸)的Adam优化器进行高效训练。
- GPT-3 还融合了交替的密集和局部带状稀疏注意力模式,优化了模型在输入的不同部分管理注意力的能力。
数据集:多样化的语料库- GPT-3是在一个综合数据集上训练的,该数据集汇集了各种来源,以创建一个丰富多样的训练语料库:Common Crawl、WebText2、Books1、Books2和维基百科是使用的五个数据集。更高质量的数据集被更频繁地抽样,确保GPT-3接触到更有结构、连贯的文本。这些数据集包括了通用互联网内容、书籍和维基百科条目的混合,共计超过570GB的文本数据。
表现和成就
- GPT-3 在像 LAMBADA 和 Penn Treebank 这样的数据集上取得了出色的语言建模任务结果,通常在零样本或少样本设置中胜过当前技术水平。
- 在其他NLP任务中,如翻译、结构解析和闭卷问题回答,GPT-3展现出竞争力或更高的性能,特别是在少样本情况下,提供示例让它能更有效地学习。
此外,GPT-3 在合成任务中表现得很出色:
- 算术计算和拼字游戏。
- 编写SQL查询,生成代码片段,甚至解决逻辑谜题,如拼字或执行基于提示的基本推理任务。
GPT-3 的庞大参数数量使其能够处理各种各样的任务,从文本生成到翻译,而无需针对任务进行特定训练。该模型可以撰写文章,生成代码,总结文本,甚至生成创造性的文学作品,有时与人类创作的内容难以区分。
4. GPT-4:超越规模和通用智能的追求
在2023年,OpenAI推出了GPT-4,详细介绍在论文“GPT-4技术报告”中,代表了语言模型的新前沿。GPT-4建立在其前身的先进基础之上,提供了一个更强大和精致的模型,能够处理日益复杂的任务,涵盖更广泛的学科领域。
主要进展和概念
- 多模态功能:与以往主要基于文本的前身不同,GPT-4引入了多模态功能。这意味着GPT-4可以接受文本和图像作为输入,使其能够理解和解释自然语言旁边的视觉信息。这种多模态方法为结合文本和图像理解的任务打开了新的可能性,如图像描述、视觉问答等。
- 改进的推理和上下文理解:GPT-4显著改进了其处理复杂推理和长篇上下文理解的能力。其中一个关键的增强是扩大了上下文窗口,使得GPT-4能够处理和保留更多的信息。这种改进使得GPT-4特别擅长处理需要在长时间对话或文件中保留详细信息的任务,如法律文件分析、详细摘要和延长对话。
- 更少的幻觉和减少偏见:先前模型如GPT-3面临的关键挑战之一是幻觉的发生 - 即模型生成虚假或误导性信息的情况。GPT-4引入了更好的机制以减少幻觉,从而产生更可靠和准确的回答。此外,GPT-4经历了减少偏见的努力,以最小化有害刻板印象或偏见的放大,产生更公正和更符合道德的输出。
模型架构和训练
尽管OpenAI已将GPT-4的某些架构细节保密,但与GPT-3相比,有几项进展是显而易见的:
- GPT-4提高了参数效率,这意味着它在不增加参数数量的情况下取得了更好的性能。
- 它在其架构中引入了稀疏技术,使模型的某些部分根据特定任务的要求激活,而不是始终利用整个模型的计算资源。
- 多模态能力扩展了架构的范围,超越了纯文本模型,嵌入了文本和图像处理层。
GPT-4继续依赖大量数据集,但OpenAI应用了更多复杂的技术,以确保模型能够访问多样化和高质量的数据。 GPT-4的训练语料库不仅是以往数据集的延伸,还包括多模态数据集和更丰富的文本语料库。
表现和成就
GPT-4 在语言理解、零-shot 学习和多模态任务方面树立了新的基准,超越了许多领域的先前最先进技术。
- 人类化的推理:GPT-4展示出卓越的推理能力,特别是在需要整合来自不同领域知识的任务中,如科学推理或跨语言翻译。
- Few-shot和zero-shot学习:该模型在Few-shot学习方面继续发挥GPT-3的优势,但在zero-shot设置中表现更好,能够处理只提供最少或没有示例的任务。
- 多模态任务:通过接受图像作为输入,GPT-4展示了独特能力来解决以前的模型无法处理的任务,比如生成图像的详细描述,分析图表,或执行视觉问答。
GPT模型的限制和道德考虑
- 资源密集性:大型GPT模型需要大量的计算资源来训练和部署。这引发了人们对大型LLM模型对环境影响的担忧。
- 伦理关注:在模型输出中存在偏见是由训练数据中存在的偏见导致的。对模型被误用生成误导性或有害内容的风险,同时进一步巩固人工智能系统中的偏见是一个持续的挑战。
- 泛化与专业知识:GPT-4在一般推理和模式识别方面表现出色,但并不总是能够与专门针对高度技术性或特定领域任务的专业模型相匹配。这突显了构建通用人工智能和针对特定应用进行细化调整的模型之间的权衡。
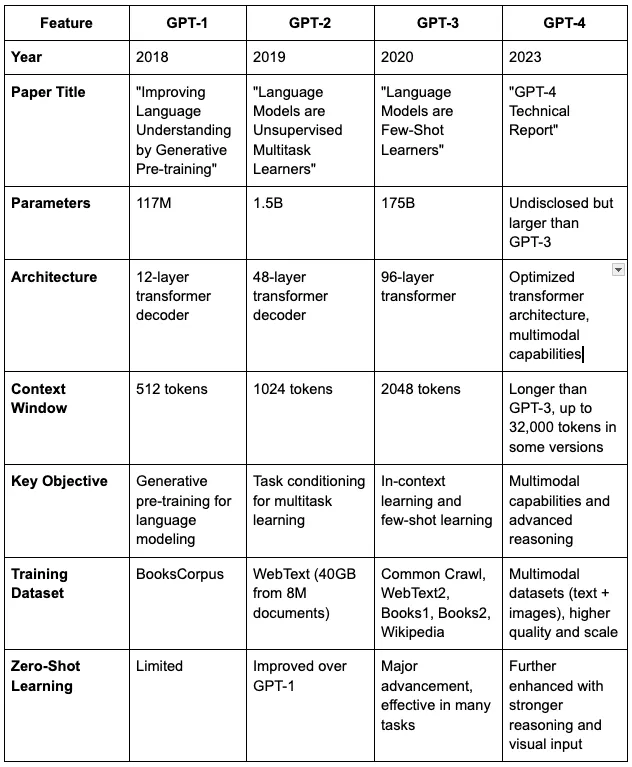
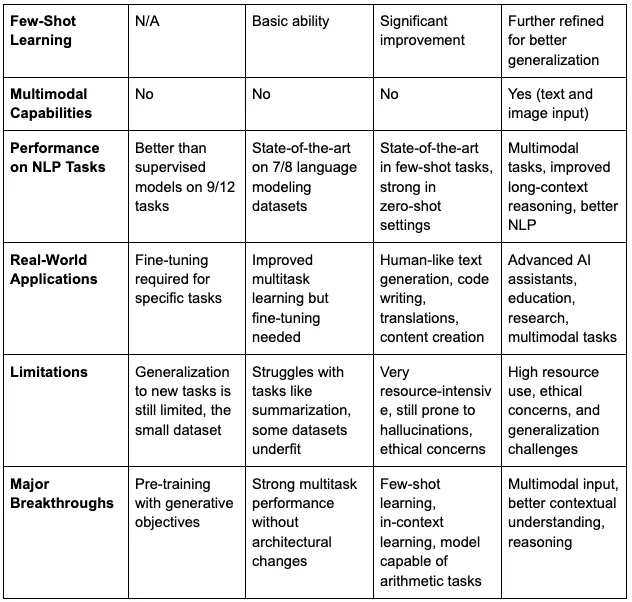
GPT 模型总结表-
5. 解码最小的GPT 2模型。
我想要详细讨论每个部分,所以我把这一部分移到了这里的一个新文章。请将这篇文章视为第一部分,另一篇文章视为第二部分。
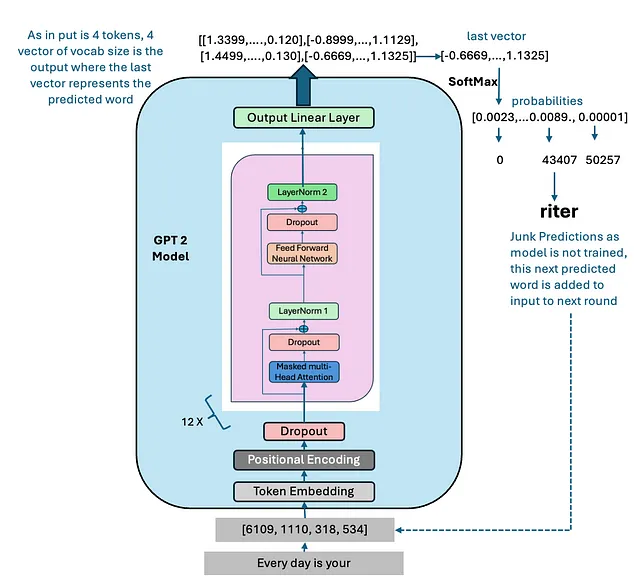
您也可以在这里找到代码。
感谢阅读!
谢谢阅读!现在你了解了OpenAI GPT模型的演变,想要从头开始编写一个GPT模型,请阅读这里的第二部分。
代码仓库
https://github.com/vipulkoti/BuildGPT2Model
参考资料【第一部分和第二部分】
[1] Radford, A., & Narasimhan, K. (2018). 通过生成式预训练来提高语言理解。
[2] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D., & Sutskever, I. (2019). 语言模型是无监督多任务学习者。
[3] Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020). 语言模型是少样本学习者. arXiv. https://arxiv.org/abs/2005.14165
[4] OpenAI. (2023). GPT-4 技术报告. arXiv. https://arxiv.org/abs/2303.08774
[5] 阿什什·瓦斯瓦尼,诺姆·沙吉尔,妮基·帕马尔,雅各布·乌斯科雷特,利昂·琼斯,艾丹·戈麦斯,卢卡什·凯撒,以及伊利亚·波洛苏欣。关注力就是你所需要的。NeurIPS,2017。
[6] Raschka, S. (2023). 从头开始构建一个大型语言模型. Manning出版社。https://www.manning.com/books/build-a-large-language-model-from-scratch.