冰川网络在人工智能领域
▪ ️人工智能的兴起和衰落
“人工智能的诞生”始于1940年代的控制论运动,源于一种机器和人类可能基本相似的想法。
在他的论文《计算机机器和智能》中提出的一个问题,“机器能思考吗?”,由艾伦·图灵引发了人工智能领域的探索。在这项工作中,图灵引入了“模拟游戏”的概念,科学家们试图根据思考能力区分机器和人类。自那个关键时刻以来,研究人员一直在致力于推动人工智能领域的发展。
20世纪40年代至90年代期间,早期象征性人工智能、自然语言处理和金融医学专家系统崛起。然而,人工智能发展经历了多次繁荣和低迷周期,受到过度乐观、资金挑战和技术限制的驱动。
这些早期十年为现代人工智能奠定了基础。 20世纪90年代的互联网繁荣,加上大数据的激增和计算能力的进步,引发了人工智能革命。 这种融合推动了人工神经网络实现了开创性的突破,将人工智能推向了前所未有的高度。
在2017年,谷歌推出了具有影响力的论文《Attention is All You Need》,提出了Transformer——一种简单而革命性的架构,使用自注意力来高效处理文本序列。这一创新引领了生成式人工智能的新纪元的出现。
当我们进入2024年,我们正见证着人工智能和加密货币的前所未有的融合,这些技术以动态的方式交叉,正在重塑行业并创造新的机遇。
▪ 技术发展
机器学习(ML)是人工智能的一个子集,它使机器能够从数据中学习,并随着时间的推移改善性能,而无需明确的编程。在ML出现之前,更简单的方法如模式匹配被用来根据预定义的标准搜索数据。术语“机器学习”最早由IBM的Arthur Samuel于1959年提出,标志着向更具适应性、数据驱动方法的重要转变。
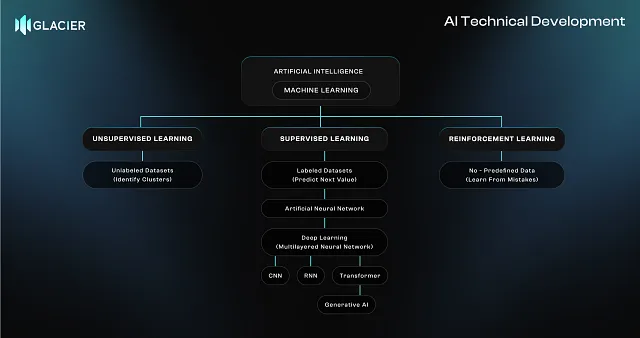
监督学习
监督学习是机器学习中最常用的形式,模型从带标签的数据集中学习。
人工神经元接收输入参数和相应的输出标签(正确答案)。然后通过调整权重和偏置来学习映射,以预测新的、未见的数据的结果。a(1)=(Wa(0)+b)
无监督学习
与从一个严格的“老师”那里接收带有标签的答案不同,无监督学习更像是一个宝宝通过观察和模仿来学习世界。这使得系统能够利用互联网上大量免费可获得的数据。
在无监督学习中,对世界建模的最基本方式是假设它由具有相似属性的不同对象组成。我们可以设计算法来对数据集进行聚类,并发现隐藏的模式、趋势和关系。
强化学习
强化学习对于获得我们自己无法完全理解的技能非常有用,特别是在未知环境中。我们向人工智能提供反馈,告诉它成功还是失败(奖励和惩罚范式),然后要求它解释它是如何取得结果以及所遵循的路径。
人工神经网络
正如其名所示,人工神经网络受到大脑的启发。每个网络由输入层的神经元、隐藏层和输出层组成。神经网络的核心功能是将激活从一层传递到下一层。
整个网络可以被描述为一个接受大输入的功能,处理它们,并产生一个输出。这个过程涉及大量的参数(以权重和偏差的形式)以及进行多个矩阵-向量乘法和其他计算。一旦函数经过精细调整以获得准确性,它就变成了一个强大的模型。
Transformer 变压器
变压器是一种特定类型的神经网络,是当前ChatGPT繁荣背后的核心发明。它最初在2017年由谷歌在论文“注意力就是一切”中引入。
当聊天机器人需要生成一个单词时,输入内容被分解成称为标记的小块。每个标记与一个向量(一组数字的列表)相关联,编码该部分的含义。然后,标记通过一个注意力块以理解上下文,并通过多层感知器进行处理。这个过程重复进行直到最后,产生一个概率分布,覆盖所有可能接下来出现的单词。
▪️AI x 加密技术堆栈
2024年标志着人工智能和加密技术融合的关键时刻,这一革命的爆发受到了Vitalik Buterin的《加密+人工智能应用的承诺和挑战》论文的深刻启示的显著催化。
在AI-Crypto技术堆栈中,架构建立在四个关键层面之上:应用层、算法层、计算层和数据层。这些层面中的每一个在人工智能和区块链技术之间无缝交互中都发挥着至关重要的作用,为去中心化、智能系统打下坚实的基础。
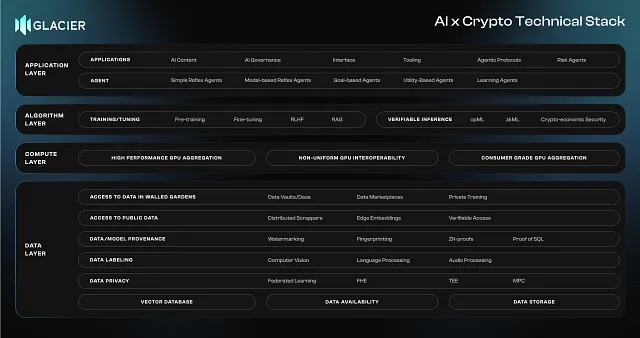
应用层作为用户界面组件,使用户能与AI驱动的分散应用和代理进行交互。算法层支撑智能,其中AI模型和区块链共识机制合作以提高效率、扩展性和安全性。计算层提供执行动力,为支持AI模型和处理区块链交易提供必要的处理能力。最后,我们认为数据层充当支撑,确保安全、分散和不可变数据存储,这对于训练AI模型和维护区块链完整性至关重要。
数据在人工智能中的关键作用
数据是人工智能模型的基石。它为学习提供了基础,让人工智能能够进行预测,识别模式,并解释世界。没有健壮的数据集,人工智能系统只会是复杂的算法,没有实际应用。就像人类从经验中学习一样,人工智能模型也是从数据中学习。这些数据经验的丰富性从根本上塑造了人工智能的能力。人工智能的训练阶段涉及处理大量数据集以检测模式并从中学习。
持续学习与数据质量
在现实世界的应用中,AI必须不断通过学习新数据来适应。这种持续的适应对系统随着时间的推移改进其效率和准确性至关重要。然而,数据的质量和数量同样重要。干净和结构良好的数据显著提高了AI的性能。数据科学家在准备数据上投入了大量工作,确保数据对训练AI模型是最佳的。
使用区块链解决数据安全和隐私问题
人工智能和机器学习(ML)模型需要大量的数据集进行训练,这引起了人们对数据泄露、篡改和隐私的担忧。区块链技术通过防篡改数据存储、增强数据隐私和安全数据共享解决了这些问题。区块链的固有透明性允许对数据来源和使用进行完全的追溯,这对于训练可靠的AI / ML模型至关重要。
此外,区块链有助于创建去中心化数据市场,允许数据提供者和消费者直接互动。这种数据访问的民主化推动了人工智能/机器学习领域的创新,并支持平台间无缝数据共享,增强协作研发并加速技术进步。
▪️ 冰川网络:AI的数据层
在与历史数据互动的过程中,我们发现人工智能公司对去中心化数据表现出了极大的兴趣。这使我们找到了现有数据基础设施的不足之处,以及数据生命周期管理过时的方法。我们与行业老将的讨论揭示了一种广泛需求,即确保数据透明度的工具。
冰川的使命和创新
作为Web3及其原则的支持者,我们认识到将这些价值观整合到传统数据管理中的潜力,旨在建立一个公正、可验证、透明、验证、公开的系统。
冰川通过提供符合AI模型广泛需求的主权AI数据基础设施来体现这一愿景。冰川网络正在为代理、模型和数据集构建可编程、模块化和可扩展的区块链基础设施,从而将规模化的AI推向新高度。
冰川VectorDB:
检索增强生成(RAG)的记忆
冰川提供数据中心网络,使用分散式矢量数据库来轻松处理数据集,该数据库基于Arweave、Filecoin和BNB Greenfield。人工智能训练过程涵盖了多种矩阵运算,从词嵌入和变压器QKV矩阵到softmax函数。作为构建检索增强生成(RAG)模型中的记忆的基础,矢量数据库在人工智能中扮演着重要角色。
冰川聊天机器人平台
利用人类智慧来训练机器智能
Chatbot-Bench是一个旨在以无需信任和去中心化的方式评估和比较大型语言模型(LLMs)性能的基准产品。参与者参与匿名化和随机化的LLMs对抗,为全面和公正的评级系统做出贡献,并获得激励奖励。商业合作伙伴被允许通过Glacier VectorDB构建并向LLMs提供数据集,确保性能评估的一致性和可靠性。
冰川通过EigenLayer确保一流的安全性,该层维护着您数据的本机以太坊级别保护。冰川使得数据生命周期的所有方面都能够保护隐私、无需许可、可核实和去中心化。这包括但不限于注释、数据集管理、定制和模型评估。通过营造一个数据可以在安全开放的环境中茁壮成长的生态系统,冰川正在为我们管理和利用AI数据树立新的标准。
参考资料:
请访问https://vitalik.eth.limo/general/2024/01/30/cryptoai.html
https://www.3blue1brown.com/
https://karpathy.github.io/
https://www.ibm.com/zh-cn/topics/artificial-intelligence
https://theconversation.com/weve-been-here-before-ai-promised-humanlike-machines-in-1958-222700 我们曾经在这里 - 人工智能在1958年承诺类似人的机器
https://medium.com/@amidzic.momir/crypto-x-ai-map-5fff39f02986
将AI引入加密货币
要了解更多信息,请查看这篇文章:将AI引入加密货币
https://arxiv.org/abs/1706.05394
https://arxiv.org/abs/1706.05394的HTML结构
请访问以下链接获取详细信息:https://www.theblock.co/post/311645/foresight-research-ai-x-crypto-report.
关于冰川
冰川网络正在构建可编程、模块化和可扩展的区块链基础设施,用于存储、索引和查询数据,从而实现规模化AI的大幅提升。
网站 | 推特 | 电报聊天 | 电报公告 | Discord | Medium | Youtube




