AI模型在检索增强生成(RAG)中产生幻觉的频率是多少?
大型语言模型(LLMs)经常面临“幻觉”问题,即它们生成的文本并非基于事实信息。加利略的一项研究对22个AI模型进行了测试,以查看它们在检索增强生成(RAG)环境中从给定文件中检索信息时多频繁出现幻觉。结果显示,模型的表现因文件长度而异,Claude 3.5 Sonnet 总体表现最佳,而Gemini 1.5 Flash 提供了最佳的性价比组合。您可以在此处获取完整报告,也可以继续阅读我的摘要(或两者都可以)。
什么是检索增强生成(RAG),我为什么要关心?
如果您知道这是什么,请跳转到下一节。
Elasticsearch 定义了检索-增强生成为:
检索增强生成(RAG)是一种技术,它通过来自私人或专有数据源的信息来补充文本生成。它将检索模型与生成模型(如大型语言模型LLM)结合在一起,检索模型专门设计用于搜索大型数据集或知识库,而生成模型则接收该信息并生成可读的文本响应。
因此,它在两种情况下都是有用的。
当LLM需要回答有关个人数据的问题时:您很可能不希望在您的公司私人数据上训练一个LLM。但是,为您的员工或客户拥有一个ChatGPT是很不错的,这样他们可以在不阅读成千上万页的手册的情况下找到解决方案。
当LLM被训练在旧数据上时:ChatGPT 4的训练数据在2021年9月被截止。其他LLMs也有类似的时间表,所以,如果你希望它们回答你问题的最新信息,你需要以某种方式提供给它们。
引入了检索增强生成(RAG)来为LLMs提供最新或私密数据。它有两个部分 - 检索器和生成器。检索器通常是一个数据库(如PostgreSQL)或搜索引擎(如Elasticsearch),其中包含您的私密数据。当用户(例如,您的客户)输入一个查询时,首先您使用检索器找到相关的私密信息。然后,您将查询和检索到的信息传递给生成器,它通常是一个LLM。
幻觉是什么?LLM不可以使用药物,对吗?
(如果你知道是什么,请跳到下一节)
是的,没错。但是,他们仍然可以产生幻觉。亚马逊网络服务为此提供了一个很好的类比。
你可以把大型语言模型想象为一个热情过头的新员工,他拒绝时刻跟进当前事件,但总是以绝对的自信来回答每个问题。
现在,当员工面对一个问题而又毫无头绪时,他们会凭空捏造一个答案。换句话说,他们在幻想。
现在,如果我们通过RAG向新员工(或LLM)提供正确的信息,他们应该不再产生幻觉了,对吗?好吧,这取决于信息的数量。回到我们那位过于热情的新员工的例子——如果我们提供一整本书作为支持信息,他们会阅读但也会忘记,并产生幻觉得到答案。
因此,LLM是否会产生幻觉取决于支持文件的大小,或者如在AI世界中所知——背景。这就是这个实验的目的。
在检索-增强生成(RAG)中,AI模型多频繁出现幻觉?
科学家测试了 22 个 AI 模型,每个模型都有三种不同的上下文长度。
- 短文背景:不到5k令牌,相当于RAG在几页上
- 中等背景: 5千至2万5千个标记,相当于一本书的章节上的RAG
- 长文本:40k到100k个标记,相当于书上的RAG
然后,他们向那些模型提出了不同问题,提供了各种不同大小的上下文信息,并测量了答案与情境的一致性。以下是他们实验的高层摘要。
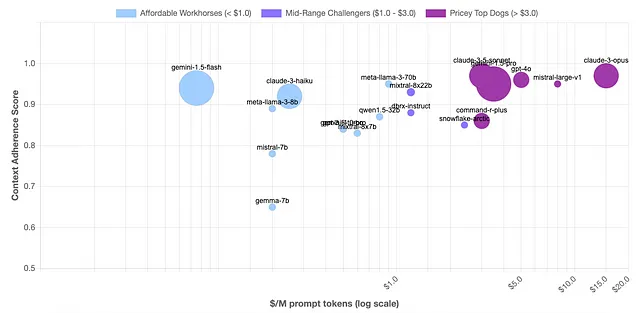
- 开源正在缩小差距:尽管封闭源模型仍然提供最佳性能,但开源模型如Gemini、Llama和Qwen在幻觉表现上继续提高,而没有封闭竞争对手的成本障碍。也许这就是OpenAI不断降低价格的原因之一。
- 中等上下文长度是关键:大多数这些模型在提供了5k至25k个标记的上下文时表现最佳。
- 大小并不总是更好:AI研究中提到的最有影响力的论文之一——机器学习研究中的“痛苦教训”认为,总体方法可以利用额外计算的情况最终胜出于依赖人类专业知识的方法。但是,在某些情况下,较小的模型表现出色胜过较大的模型。具体来说,谷歌的Gemini 1.5 Flash表现出乎意料的良好。
- 人类智胜OpenAI:人类智最新的克劳德3.5颂和克劳德3奥普斯 consistently score接近完美分数,击败了GPT-4o和GPT-3.5。
在这些模型中,来自人类起源的克劳德3.5 Sonnet一直表现比大多数其他模型更好。但是,请记住它也是目前市面上价格最昂贵的模型之一。另一方面,1.5 Flash Gemini提供了性能和成本的很好平衡。据说,它的价格可能比克劳德3.5 Sonnet低15倍,同时提供非常接近的性能。因此,除非你在一个非常大的公司工作,在那里AI模型的一个简单错误可能造成数千美元的损失,否则Flash可能是你的不二选择。在开源模型中,来自Meta的Llama在较短的上下文中表现最佳,而阿里巴巴的Qwen则在更大的上下文中胜出。
近年来,全球对人工智能(AI)感到惊叹,但自2017年以来,模型架构方面实际创新严重不足。因此,开源模型迅速赶上了封闭源竞争对手,即使没有重大投资也是如此。换句话说,封闭源模型并未像带有创新模型架构的模型那样前进。尽管如此,我们确实有一些有潜力能在下一个十年引领潮流的架构。我希望下周能写一篇关于它们的文章。从那时起,请保持好奇心!