测试ChatGPT在识别和提取图像数据方面的能力
在我们的日常生活中,我们会遇到无数的图像,无论是浏览网页、在杂货店购物还是解决难题。但是人工智能,特别是 ChatGPT,能够多好地解释和理解这些视觉元素呢?本博客文章探讨了 ChatGPT 辨识和从各种类型图像中提取信息的优势和劣势。
杂货购物:寻找优惠和物品
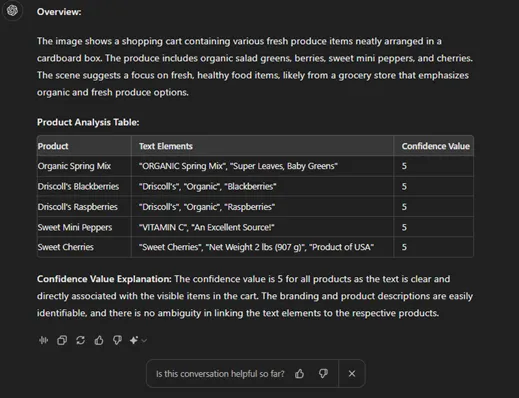
每次去杂货店都可能让人感到不知所措,尤其是在充斥着促销标识和折扣的情况下。我们经常因为商品打折而购买不需要的物品。为了测试ChatGPT识别这些促销的能力,我上传了各种不同取向和尺寸的商品图片。令人印象深刻的是,ChatGPT成功地正确识别了6件商品中的5件,展示出在识别产品方面表现良好,尽管它们的呈现方式各不相同。
然而,进一步的实验揭示,这种成功仅在涉及视觉识别的一些任务中是普遍的。

视觉谜题:ChatGPT的一项艰难挑战
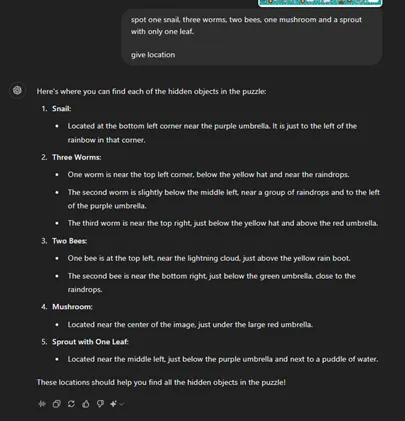
为了提升水平,我用视觉难题测试了ChatGPT — 这是一个它觉得更具挑战性的任务。例如,在一个旨在识别隐藏物体的难题中,ChatGPT识别出了一只蜗牛,但未能发现其他物品,如蠕虫、蘑菇或蜜蜂。在另一个模式识别难题中,ChatGPT正确识别了规律,但无法基于此得出逻辑结论。

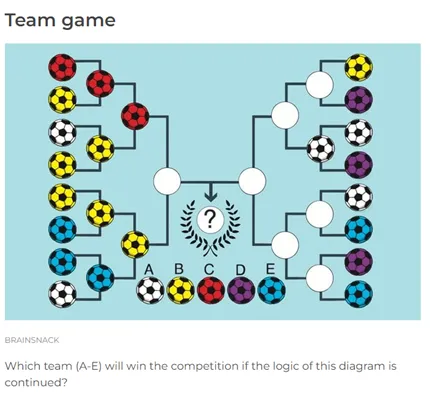
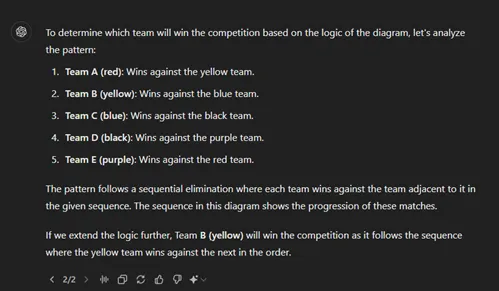
答案:红色
Chatgpt 4o: 黄色
这表明,虽然ChatGPT可以在简单的情境中识别单个元素,但是当面对复杂场景或需要逻辑解释这些元素时,其性能会显著下降。
手写资料:识别数学函数
从视觉谜题转到手写材料,我测试了ChatGPT对数学图形和方程式的识别能力。我上传了一个函数y=2^x的图形,ChatGPT能够准确识别。这一成功可能归因于图形相对简单,元素较少且背景清晰,这样对于模型而言更容易处理。
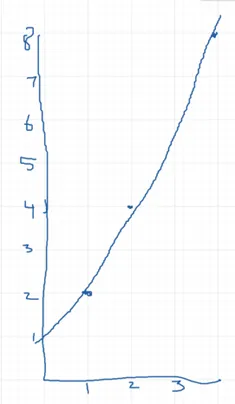
为了进一步测试其能力,我让ChatGPT使用普通幂规则和牛顿商法来计算函数的导数。令人印象深刻的是,它在两种方法中都提供了正确的答案,并识别了手写问题中的符号。


接下来,我向ChatGPT提出了一个涉及围绕x轴旋转获得的固体体积计算的问题。再次,它给出了正确答案,展示了其在处理涉及清晰符号的数学问题时的能力。


场景识别:识别面孔和情绪
为了进行更有趣的测试,我探索了ChatGPT识别职业摔跤场景的能力 — 特别是一个被称为The Bloodline的团体。ChatGPT能够准确描述场景,识别关键人物,如Paul Heyman、The Usos、Solo Sikoa和Roman Reigns。它甚至识别了像Roman Reigns的姿势这样的细节,并正确识别了各种冠军称号。


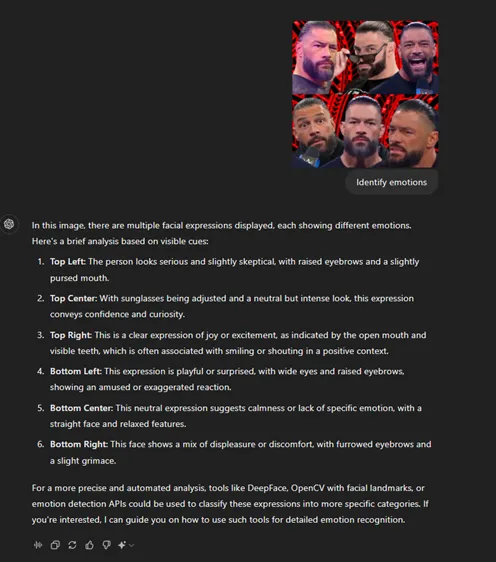
然而,它在识别观众手持相机手机为摄影师时犯了一个小错误。当涉及到识别不同情境中罗曼·雷恩斯的情绪时,ChatGPT 正确识别出了6个情绪中的5个,但在一个场景中错过了明显的愤怒情绪。
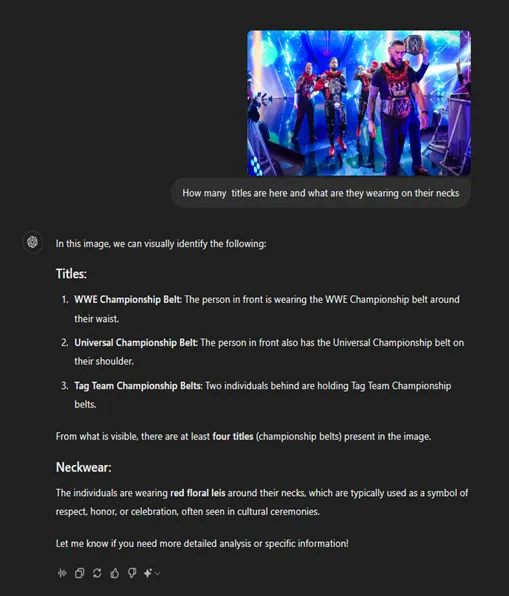
另外,在被问及摔跤手头衔和戴的礼花的位置时,它能够准确识别所有的头衔。但是,它对于精确的位置仍有困难 — 当描述头衔在肩膀上时,实际上是在肩膀上方。这说明虽然ChatGPT能够准确识别物体和服装,但有时在它们的位置细节上会有困难。
梗圖:理解幽默和背景
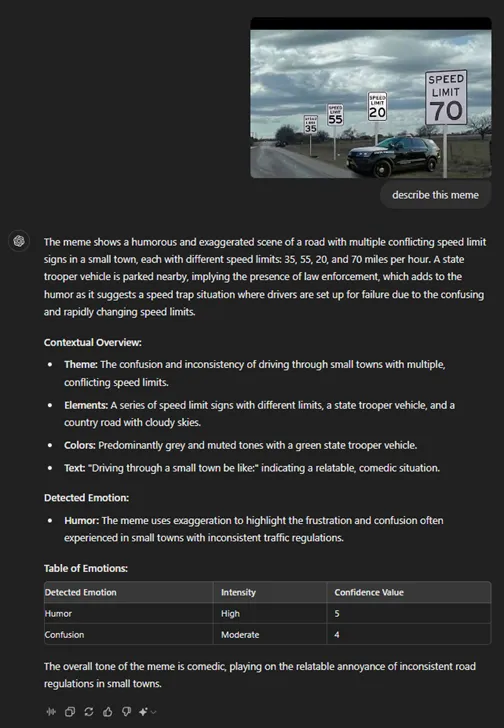
最后,我测试了ChatGPT理解网络迷因的能力——这是互联网上常见的一种视觉幽默形式。在一个例子中,它识别了一个围绕混乱和幽默的迷因,解释了一个“速度陷阱”的情境。这表明ChatGPT可以识别迷因的基本主题,即使它可能无法完美捕捉每一个微妙的细节。

结论:ChatGPT在图像识别方面的优势和局限性
从这一系列实验中可以明显看出,ChatGPT 在识别和解释较简单的图像方面具有明显的优势,特别是涉及到清晰、明显元素的图像,比如数学符号或熟悉的场景中有明确定义的物体。然而,在面对复杂的视觉图像时,比如有多个重叠元素的谜题或需要精确放置物体的情景,其表现就会下降。
随着人工智能的进化,图像识别能力的提高可能会增强ChatGPT在这些具有挑战性的任务中的性能。目前,它最好的用途是在视觉输入简单明了,上下文明确定的应用程序中。




