与您的PDF聊天-使用Langchain、OpenAI和Choreo部署一个简单的RAG应用程序
大型语言模型在过去两年中彻底颠覆了科技世界,并继续扰乱技术格局。ChatGPT的创举得到其他科技巨头的支持,如克劳德、双子座和羊驼等LLM的创建。无论是精通技术的个人还是不太熟悉技术的人都已经将LLM整合到他们的日常生活中。
一个LLMs的警告是它可能没有足够的关于我们自己数据或定制信息的背景。LLMs是在特定数据集上训练的,能够利用它们的语言技能几乎回答我们提出的所有问题。但是,如果我们想要询问它关于特定的自定义数据,超出其知识库的范围,它将会困惑和产生幻觉。RAG或检索增强生成(Retrieval-Augmented Generation)是一种旨在克服这一挑战的应用类型。它结合了我们自己的自定义知识库和LLMs的语言能力,以改进LLMs的输出并使其更准确地回答关于自定义/特定情景的查询。
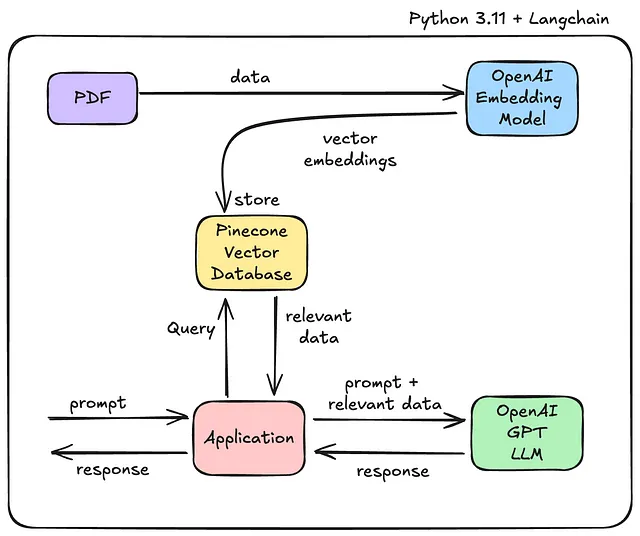
一个RAG系统的鸟瞰图如下所示。
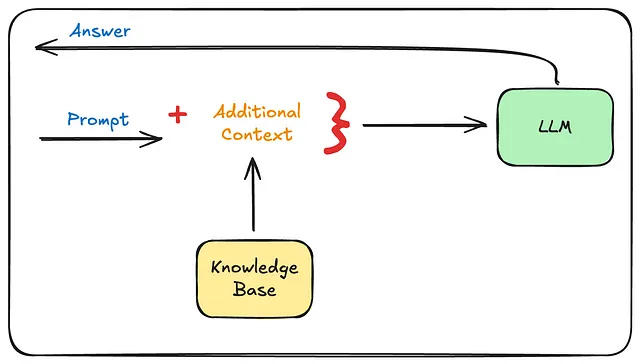
简单来说,当用户提出查询时,RAG应用程序会查询连接的知识库以获取相关背景信息,并将该背景信息与用户的查询打包后发送给LLM。LLM随后处理这些数据并提供适当的回答。
创建RAG应用程序的步骤
我们可以将创建一个简单的RAG应用程序分为三个部分。
- 数据收集和准备
- 嵌入和索引数据
- 检索索引数据并查询LLM。
让我们来详细看一下以下的3个步骤。
数据收集和准备
在这一步骤中,必须收集所有相关数据,并在必要时对其进行预处理。这些数据可以是PDF文件,Markdown文件,文本文件,甚至纯文本。
嵌入和索引数据
在这一步中,我们将收集到的数据发送到我们所谓的“嵌入模型”,它会返回一个向量表示,即所提供数据的数值模型。这些“向量嵌入”然后被存储在一个“向量数据库”中。向量数据库是一个存储结构化和非结构化数据的数学表示的数据库。
检索数据嵌入和查询LLM
当提供提示时,向向量数据库查询以找到与提示相关的数据上下文,然后找到的上下文与提示一起发送到LLM,在LLM中,LLM将提示和提供的数据考虑在内,并回复相关的答案。
正如标题所述,在本文中,让我们看看如何创建一个RAG应用程序来询问我们提供的PDF文件的问题。在某种意义上,我们可以通过利用这个应用程序与我们的PDF文件“交流”。
使用Langchain创建RAG应用程序,Langchain是一个流行的Python框架,用于创建RAG应用程序。作为基础模型,我们正在利用OpenAI的GPT模型和嵌入模型。至于知识库,我们正在使用“Pinecorne”,这是一个流行的矢量数据库,您可以免费在线尝试。即使经过了所有这些步骤,我们仍需要将我们的应用程序暴露在互联网上才能发挥作用,为此,我们使用WSO2的最先进的集成平台服务Choreo。我们将在Choreo上部署我们的Python/Langchain应用程序,并将其公开为任何人都可以调用的API。
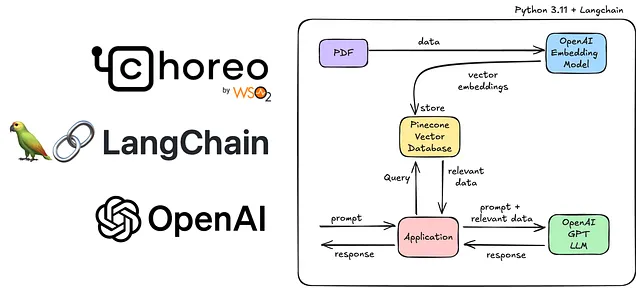
总体上,我们的技术堆栈会像下面这样。
- 浪链 — 用于创建RAG应用程序
- OpenAI 嵌入模型 - 嵌入数据
- 松果 - 存储矢量嵌入
- OpenAI GPT — LLM
- WSO2合唱 - 构建,部署和向公众公开我们的应用程序。
简单的RAG结构
让我们开始编码吧!
在我们开始编写应用程序之前,您需要创建三个帐户。
- 编舞账户 - 能够构建和部署您的应用程序
- OpenAI 平台账户 — 允许您访问 OpenAI API。
- 松果账户-允许您访问松果无服务器矢量数据库。
然后您需要为OpenAPI和Pinecone获取两个API密钥
- OpenAI - 前往https://platform.openai.com/api-keys创建一个新的秘钥。将其复制并保存在安全的地方。
- 松果 — 左侧面板 → 管理 → API密钥 → 创建API密钥。复制并保存。
我正在使用Python 3.11和PyCharm IDE开发这个项目。
首先,您需要在PyCharm(或您偏好的IDE)中创建一个新项目,并添加以下requirements.txt。
langchain~=0.1.12
langchain-community
pinecone-client
langchain-openai
openai
langchain_pinecone
uvicorn~=0.30.5
fastapi~=0.112.0
pydantic~=1.10.17
pypdf
然后将您的Pinecone API密钥和OpenAI API密钥添加到.env文件中。确保绝对不要将此文件推送到git!
OPENAI_API_KEY=""
PINECONE_API_KEY=""
之后将我从NASA [1]中提取的关于暗物质的PDF文件复制到您的目录中。完成后,您的目录会是这样的。
.
├── .env
├── dark-energy.pdf
└── requirements.txt
如果您参考我们创建RAG应用的第一步,数据收集(即pdf文件)和项目设置已经完成。接下来,我们需要创建嵌入并将它们存储在Pinecone中。让我们为此创建一个名为embed.py的文件。
import os
from langchain_community.document_loaders import PyPDFLoader
from langchain_openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_pinecone import PineconeVectorStore
from pinecone import Pinecone, ServerlessSpec
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
PINECONE_API_KEY = os.getenv("PINECONE_API_KEY")
def create_or_update_index(texts, index_name, embedding):
pc = Pinecone(api_key=os.environ.get("PINECONE_API_KEY"))
if index_name not in pc.list_indexes().names():
pc.create_index(
name=index_name,
metric='cosine',
dimension=1536,
spec=ServerlessSpec(
cloud='aws',
region='us-east-1'
)
)
print(f"Created new index: {index_name}")
vectorstore = PineconeVectorStore.from_documents(
texts,
embedding=embedding,
index_name=index_name
)
else:
print(f"Index {index_name} already exists")
vectorstore = PineconeVectorStore.from_existing_index(
index_name=index_name,
embedding=embedding
)
return vectorstore
pdf_path = "dark-energy.pdf"
loader = PyPDFLoader(pdf_path)
documents = loader.load()
text_splitter = CharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
texts = text_splitter.split_documents(documents)
embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
index_name = "pdf-index"
vectorstore = create_or_update_index(texts, index_name, embedding)
在这里,我们利用langchain_community库中的PyPDFLoader来加载我们存储的PDF。然后我们需要将大型PDF拆分为小块文本,为此我们可以使用CharacterTextSplitter,它指定了chunk_size(块的最大大小)和chunk_overlap(两个块之间的重叠量)。下面的Web应用程序“ChunkViz”可以清晰地呈现文本块的分割和重叠。

这些深绿色部分是块的重叠部分。
在定义了TextSplitter之后,我们可以将文档输入到文本拆分器中,并获得拆分后的文本。
texts = text_splitter.split_documents(documents)
接下来,下一步是嵌入过程。我们需要将分块文本发送到嵌入模型中,并收到对应的向量嵌入。在这种情况下,我们使用OpenAI的text-embedding-ada-002模型。
embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
获得嵌入后,我们可以在Pinecone矢量数据库中创建一个新的索引,并使用create_or_update_index方法存储我们的嵌入。该方法使用Pinecone Python库的pc.create_index方法将嵌入发送到一个新的索引。
在创建 embed.py 文件后,运行以下命令来安装依赖项:
pip install -r requirements.txt
然后您可以运行embed.py。
python3 embed.py
这可能需要一些时间,如果一切顺利,您将看到以下消息。
Created new index: pdf-index
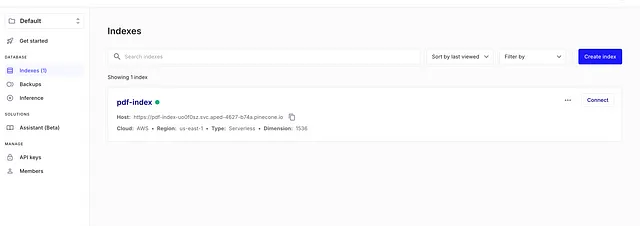
现在,如果您前往松果 UI,您将看到已创建了一个新的索引!
现在,我们必须创建一个API,允许用户询问关于PDF内容的问题。为了创建这个API,我们将使用FastAPI,这是一个强大的Python Web框架。
创建以下 api.py 文件。
import os
from fastapi import FastAPI
from pydantic import BaseModel
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_pinecone import PineconeVectorStore
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from pinecone import Pinecone
app = FastAPI()
OPENAI_API_KEY = os.getenv("OPENAI_API_KEY")
PINECONE_API_KEY = os.getenv("PINECONE_API_KEY")
# Initialize Pinecone
pc = Pinecone(api_key=PINECONE_API_KEY)
embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
index_name = "pdf-index"
vectorstore = PineconeVectorStore.from_existing_index(
index_name=index_name,
embedding=embedding
)
# Initialize ChatOpenAI
llm = ChatOpenAI(
openai_api_key=OPENAI_API_KEY,
model_name='gpt-4o',
temperature=0.0
)
# Creating Prompt
prompt_template = """Use the following pieces of context to answer the question at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
{context}
Question: {question}
Provide a concise answer in 1-4 sentences:"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
# Creating a Langchain QA chain
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever(),
chain_type_kwargs={"prompt": PROMPT}
)
class Query(BaseModel):
question: str
# Create API Endpoint
@app.post("/ask")
async def ask_question(query: Query):
response = qa.invoke(query.question)
return {"answer": response['result']}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8080)
首先,我们将进行必要的初始化工作,如设置 API 密钥、建立松果连接,并使用 OpenAI 的 gpt-4o 模型建立 LLM 连接。
之后,我们创建了一个提示模板,该模板将被发送给LLM。在这里可以看到两个可替换部分,{context}和{question},context是我们从Pinecone收到的有关用户问题的数据。该模板将由原始问题和从Pinecone收到的相关上下文填充,然后发送给LLM。
然后我们需要使用Langchain创建一个QA(问答)链,并提供创建的变量。这个QA链将根据提供的上下文回答问题,使用LLM(语言模型)。
现在,我们可以在HTTP资源中调用这个qa对象,/ask来完成我们的应用程序。
部署RAG应用程序
现在我们已经完成了应用程序的开发。我们需要部署它。为此,我们将使用Choreo,这是一个基于Kubernetes的内部开发者平台服务,由WSO2提供。我们可以将这个应用程序部署为一个Python服务,而无需创建任何Dockerfiles,镜像或Kubernetes配置,Choreo会管理所有底层的调整。
首先,您需要创建一个Procfile,该文件将指示Buildpack如何启动应用程序。
web: uvicorn api:app --host=0.0.0.0 --port=${PORT:-8080}
然后在.choreo目录中创建一个component-config.yaml文件。这是一个Choreo特定的配置文件,它将配置暴露到互联网的端点。
apiVersion: core.choreo.dev/v1beta1
kind: ComponentConfig
spec:
inbound:
- name: RAG API
port: 8080
type: REST
networkVisibility: Public
这将是最终的目录结构。
.
├── .choreo
│ └── component-config.yaml
├── .env
├── .gitignore
├── Procfile
├── api.py
├── dark-energy.pdf
├── embed.py
└── requirements.txt
现在将代码推送到GitHub存储库。您可以在https://github.com/rashm1n/RAG101 找到完整的应用程序。
现在您已经准备好部署您的应用程序。按照以下步骤在Choreo中创建一个Python服务。
- 如果您还没有choreo.dev帐户,请创建一个。
- 创建一个项目→创建一个新的服务,并输入以下详细信息。
- 组件显示名称 — RAGApp
- 公共存储库URL —
- 构建包 — Python
- Python 项目目录 — /
- 语言版本 — 3.11.x
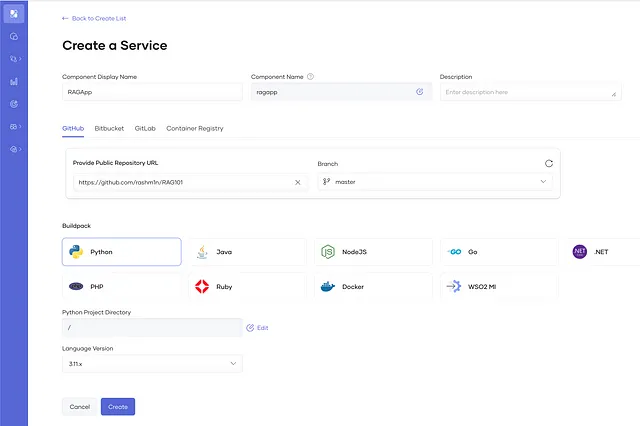
并构建服务组件。
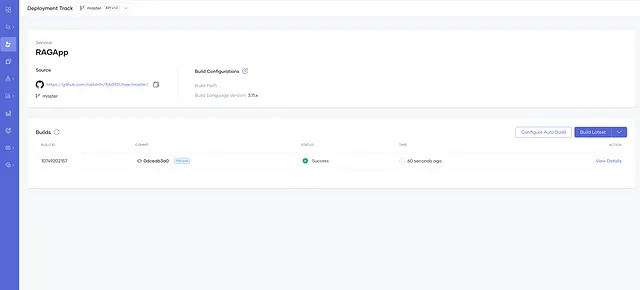
现在导航到部署菜单,然后单击配置和部署。创建两个环境变量(标记为秘密)并添加您的API密钥。 Choreo将安全地将这些存储为Kubernetes Secrets。
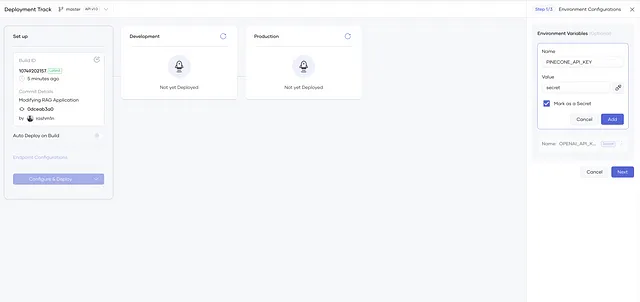
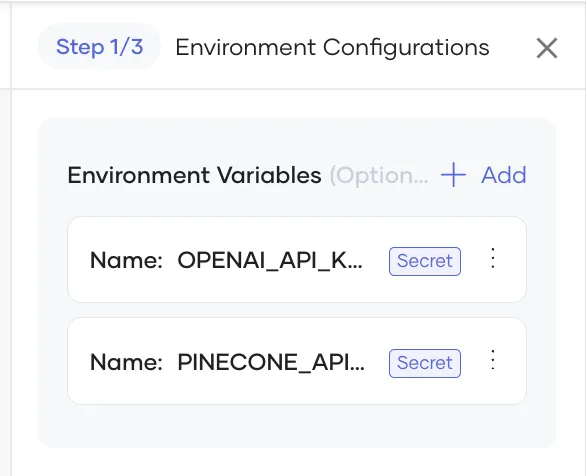
然后创建下一个组件并部署。部署后的应用程序会看起来像下面这样。
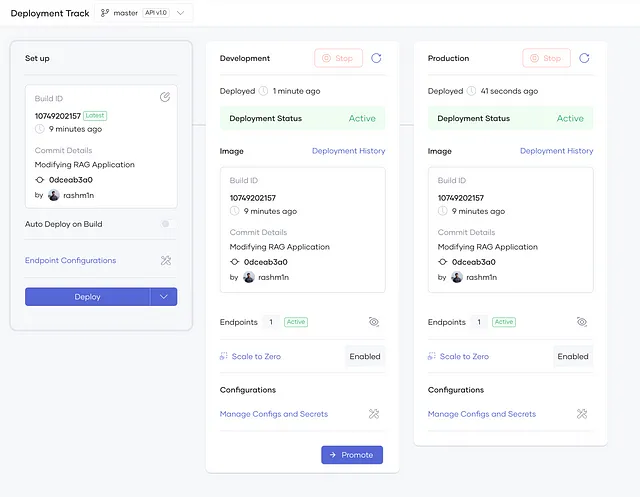
让我们导航到Choreo测试控制台,并获取测试API密钥来调用我们的应用程序。由于Choreo应用程序默认受OAuth保护,您将需要此API密钥来测试API。同时复制调用URL。

然后在curl中使用API密钥和调用URL,调用您的组件。
curl --location 'https://5d1fa89f-bb68-4cee-a1c9-5ca459e02768-dev.e1-us-cdp-2.choreoapis.dev/springproject/ragapp/v1.0/ask' \
--header 'accept: */*' \
--header 'API-Key: <API-Key>'
--header 'Content-Type: application/json' \
--data '{"question": "What is dark energy?"}'
并且您将根据提供的数据收到响应!几分钟之内,您就可以从代码转移到云端,并在互联网上调用您的应用程序。
在这篇文章中,我们讨论了创建和部署一个 RAG 应用程序,该应用程序可以在您选择的 PDF 文档中提出问题。这是一个非常简单的 RAG 应用程序和 LLMs 的示例,但您可以利用它们制作更复杂的应用程序,并使用 Choreo 安全地部署它们。
如果您有任何问题,请在下方评论。我们下一篇文章见。
资源
[1] - https://science.nasa.gov/universe/the-universe-is-expanding-faster-these-days-and-dark-energy-is-responsible-so-what-is-dark-energy/
[2] — https://choreo.dev [2] — https://choreo.dev
[3] — https://python.langchain.com/v0.2/docs/introduction/ [3] — https://python.langchain.com/v0.2/docs/introduction/
[4] — https://platform.openai.com/docs/concepts