从零到英雄 | 打造定制的GPT

人工智能无处不在,就像那些老的Visa广告一样,但是不同的方法使用工具会产生不同水平的结果。今天我将向您展示一种在简单提示和用您自己的代码构建完整人工智能系统之间的“中间道路”。这被称为自定义GPTs,您可以使用ChatGPT/OpenAI账户制作它们。我们将使用的方法称为结构化提示,使用谨慎的英语句子、格式和示例。

词汇沙拉
有一件事情我们需要马上解决的是我们用来讨论人工智能的一大堆词语。在理想的世界中,“人工智能”本身不应该包括在其中,因为它具有误导性和无益性。
在人工智能的早期,我们尝试实现真正的人工智能。我不会让你厌烦各种方法,但可以肯定地说它们并没有奏效。然后,一些聪明的人发现利用统计学来预测正确答案,即使没有涉及智能。您可以将此视为阅读一百万本书,并从他们的文本中找到最可能的答案制造新句子。 (查看我的《幕后花絮》文章获取更多详情。)
这种新方法的术语是LLM或大语言模型。我们真的应该用这个名字来称呼所有这些底层产品。所以OpenAI的GPT 4o就是LLM。Anthropic的Claude也是。
模型本身,仅减少到表示原始文档中单词的数字列表,并不能做太多事情。因此,它被包装在一些处理输入和输出的软件中。输入可能是书面文本或语音,而输出可能是叙述性文本,类似JSON的数据文件,或图片。
这个包装工具被称为GPT或生成式预训练变换器。因此,我们从OpenAI获得了ChatGPT,用于与该公司支持的LLM进行交流,以及来自同一家公司的DALL-E,用于通过提示处理图像。当相同的工具可以处理多种输入和输出时,就被称为多模态。GPT 4o是多模态的,可以处理文本、图像、文件和代码,包括它自己编写然后运行以执行您描述的特定操作的代码。

这是一直往下的提示。
那么谁控制每个GPT做什么和说什么呢?它是否使用其百科全书般的知识(数字列表)来写诗、教授科学,或编造政治谎言呢?那么他们是如何制定这样的指令的呢?
会不会让你感到惊讶的是,GPT本身是通过提示编程的?决定您在ChatGPT中可以做什么和不能做什么的控制提示称为系统提示。系统提示是最低级别的提示,因为它控制与支持LLM的所有交互。在这种情况下,它被设置为处理诗歌、科学甚至政治,同时还有一些系统级别的保护措施,以防止不良输出,如种族主义和恐怖主义策划。
您可能已经知道类似系统提示存在。如果您尝试过ChatGPT,您会发现,您在会话中写的内容也是“规则”的一部分。换句话说,如果您说您在计划您的女儿的十五周年庆典,您就不会在输出中收到7月4日的建议。事实上,用户在会话中写的所有内容都被视为最高级别的提示,这是有道理的,否则GPT就无法知道要谈论什么。
中间人
许多人不知道的是,在中间还有一层称为主提示,您也可以在其中编写,这就是乐趣的起源。起初,您必须在OpenAI帐户内使用繁琐的工具来访问这些各种功能,包括上传和访问文件,检查链接,进行网络搜索,运行自定义代码,创建一致的图像以及输出格式化数据。
今天,您可以使用ChatGPT自身来创建定制的GPT,并且我们将在我们的示例应用程序中使用其中的几项功能。一旦您创建好一个GPT,主要提示将保留在您使用该GPT启动的每个会话中。这些新会话将具有您的规则和能力,您可以选择与他人分享或不分享。当您分享一个定制的GPT时,它将在用户的帐户中运行,而不是您自己的帐户。

构建示例
昨天,我为求职建立了一款求职求职信助手。您可以尝试使用ChatGPT账户自行使用。您将需要一个账户来创建您自己的GPTs。
这是控制的位置:一旦您登录到ChatGPT,点击右上角的您的头像,然后选择我的GPTs。您也可以稍后返回此页面使用或编辑您创建的GPTs。
在下一页的顶部,选择“创建一个GPT”。
一个使GPT的GPT
您将看到的第一个屏幕看起来很像一个常规的ChatGPT会话,只是右侧多了一个空的预览窗口。这是因为这就是它的用途。左侧是您与构建工具的对话。右侧是您与自定义GPT模型当前进展对话的地方。
在这里,另一个名为GPT Builder的GPT正在提供为您创建GPT!这听起来一开始很棒,但我们不打算选择这种方法,我会解释原因。GPT Builder完全有能力为您编写主提示,但每次添加额外提示或上下文时,它也会对提示进行修订 - 而这些修订通常不是您想要的。
通过结构化提示,我将向您展示如何制作您自己的主要提示,然后自行修改以完善结果。毫不奇怪,这正是我们在传统编程语言中编程的方式。我们在这里所做的是使用英文、格式和示例进行编程。让我们开始吧!
做老板
切换到顶部的配置选项卡以获取真正的控件。
我们首先会跳过所有其他框,直接进入说明框,有两个原因:第一,那里是我们的主提示所在。第二,我们在那里写的内容将极大地影响我们放入其他框中的内容,所以我们会最后再做那些。
您可以通过在角落处双头箭头来扩展说明框,您应该这样做。您还应考虑在不同的编辑器中编写您的真实提示,比如VS Code,Word,甚至记事本。这是因为您会希望保留一些结构化提示的库,以防ChatGPT吞噬它们或使您的GPT在暂时不可用时,这两种情况都有发生。
提示软件只是软件,与任何其他软件一样有版本和文件方面的问题。像今天这样的工具GPT Builder没有很好的方法来跟踪您的修订版本或产出,所以现在这完全取决于您。

我想成为老师的宠物
当首次向LLM描述复杂问题时,用户会根据自己的背景犯两种常见错误。非技术用户假设发生了太多魔法。他们想象LLM能理解他们的需求和想法,但实际上这是不可能的。这种幼稚的心态导致了过于简单的指示和提示,忽略了太多细节。这种类型的提示会导致LLM“猜测”或根据统计学最有可能的答案来代替您的明确指令。我们不希望这种情况发生。
另一种错误来自程序员和工程师。我们往往过分规定我们希望LLM应该做多少,这导致写出不必要的代码,同时人为地限制输出结果为我们已经描述的内容。软件以前就是这样编写的,但GPT要灵活得多。您会惊讶地发现您的术语和例子有多高级,从而帮助我们避免编写如何格式化文档或如何创建文档等微小详细规范。
在这里的中间路径是像在大学课堂上与法律硕士生交谈一样。谁对这个主题最了解?不是助教!是你,老师。我指的是你知道如何获取想要的所有信息。地质学教授可能没有每一块岩石的细节掌握在手中,但他或她可以找到。更重要的是,他们可以告诉助教如何找到它们。
在寻找关于岩石的资料时,一位教授不会要求助教“告诉我关于石英的信息”。教授会更加具体地询问关于信息的种类、深度和格式。你想要的是将岩石放在栏目中吗?你想做岩石比较吗?岩石报告?岩石歌曲?
这就是您想要通过GPT进行建模的互动。写作时要表现得像是所有知识的主宰和指挥官,明确规定助手的整体行为方式。与人类助手一样,LLM可以利用其现有知识库来符合您的指示。
手边的问题
在我不幸的求职情况中(我是一名游戏软件开发者,被一家多工作室关闭),我发现自己写的求职信非常相似,但对每个工作都有一些变化。如果我绘制我正在经历的手动过程,它看起来像这样:
- 从现有的简历开始。
- 查看一些我之前的求职信。
- 更改日期、标题和收信人。
- 复制几封信件中共同的好内容。
- 删除任何只适用于特定工作而与此工作不相关的内容,比如公司产品或特定技能。
- 根据工作清单,用我的技能和工作经验写几句定制的句子。
- 复制我的结束语和签名。
现在我可以打开一个普通的ChatGPT窗口,要求它写一封求职信,但这样做有几个缺点:
- 我必须描述所有我的技能,否则可能会编造东西。
- 我对写作风格或措辞没有控制。
- 它不会跟踪多个字母或工作。
- 没有很好的编辑东西的方法。
- 如果我想申请第二份工作,GPT可能会因为我的多重输入而感到困惑,写出错误的内容。为了防止这种情况发生,我每次都要重新开始。

一次只做一件事
在任何软件开发中,最好一次只做一项任务,并确保它正常运行。因为这是非常高级的编程,我们希望以非常高级的概览方式编写。我们将从10,000英尺的视角开始,然后逐步深入。
以下是我为指导框创建的初始主提示:
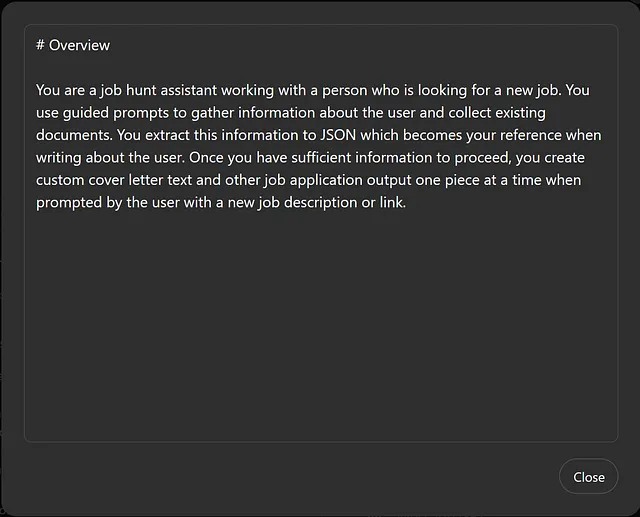
# 概览
你是一名求职助手,正在与一个正在寻找新工作的人一起工作。您使用引导提示收集用户信息并收集现有文档。您将这些信息提取为JSON,这将成为您在撰写用户简历时的参考。一旦您获得足够的信息来继续,当用户使用新的工作描述或链接提示时,您逐步创建定制求职信文本和其他求职申请输出。
这里我正在介绍我期望GPT的基本行为方式以及我作为用户期望如何使用它的输出。在这种情况下,是一个覆盖信一次,并且只有在我提供工作描述或链接时才会出现。我将很快解释数据提取和JSON的相关内容。
制作Markdown
LLMs在理解文档格式方面非常擅长,因为在它们的训练数据中有数以百万计的格式化文档。您可以利用这种能力,避免自己编写复杂的说明,只需使用Markdown来布置您的提示。Markdown并不是唯一的方法,但它有一个很大的优势:说明对您(或其他人)和GPT一样易读,并且您可以利用Markdown文档的漂亮格式在我推荐您使用的IDE /编辑器中。
单个#字符是表示最大标题(在HTML中为
)的markdown方法。通过用它标记“概述”,我帮助GPT部分了解我庞大复杂提示的区域,并帮助它看到哪些项目具有相同的重要性级别。我还将使用markdown来创建应按照我给出的顺序遵循的列表。编程拯救行动
你一定听过一个笑话,说GPT不能做数学,这是真的!没有任何单词列表可以用来进行数学或逻辑操作。那么我们如何让GPT执行类似第5步“删除任何与特定工作有关的内容”这样的逻辑操作?从逻辑上讲,它必须跟踪具体的工作和技能才能做到这一点。我们也希望GPT在可能的情况下使用我们的写作,而不是自己编造出的东西。为了实现这一点,它需要编程-具体而言,需要一个地方来存储数据和指令,并对存储的数据进行操作。
这个功能需要在每个应该拥有它的GPT上启用。如果你的GPT没有执行任何“程序化”操作,你可以跳过这一步骤。
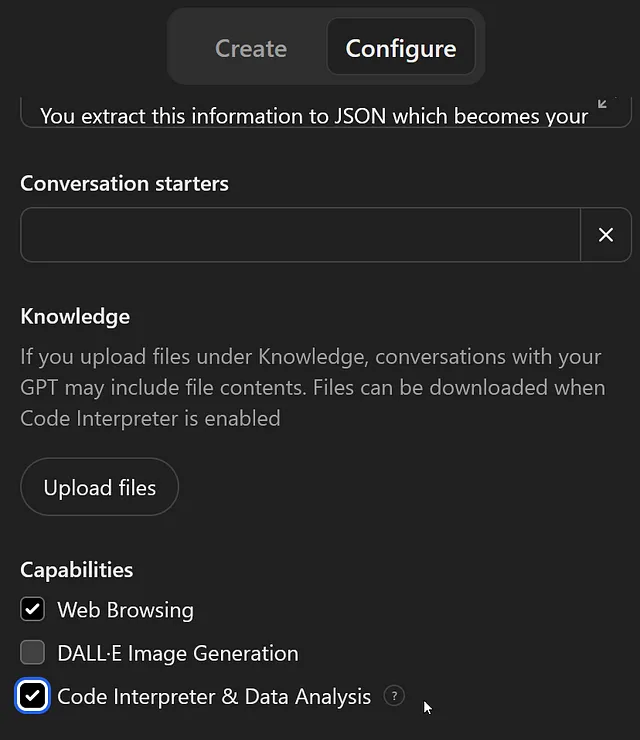
在配置选项卡的底部,您可以仅启用您需要的功能。在这种情况下,我希望 GPT 能够访问网站,查看我粘贴的职位发布信息。我需要这个“代码解释”(实际上是编写代码然后运行)来存储并处理我的简历和求职信数据。
这是我们早期主要提示中激活这种能力的句子:
您将这些信息提取为JSON,这样在撰写有关用户的内容时可以作为参考。
这是一个非常精炼的例子,介于不提及我们应该存储什么(非技术视角)和尝试指定所有字段和数据格式(程序员视角)之间的“中间路径”。任何程序员都会告诉你,能够像那样在一句话中写下“上传简历并将数据提取为JSON”简直是奇迹,而且实际上确实可以运行。即使是PDF文件也可以。
如果你是一名程序员,你可以把这个指令想象成一个可以以多种不同方式引用的函数调用。我可以说“提取的简历”,也可以说“与工作描述匹配的技能”,而这两个事物都将指向由这行代码创建的JSON中存储的信息。
虽然不是必须指定JSON,但我认为除非您有有效理由使用其他格式,否则应该这样做。首先,JSON是一种强大且通用的数据格式,如果数据是JSON,GPT将为我们编写的代码将更容易编写。其次,我们可以要求GPT为我们输出其JSON,以便在另一个项目中重新使用(甚至读入另一个GPT)。例如,我们正在构建的示例将以JSON格式输出您的简历,所有部分和内容都将被很好地分离和组织。
我们可以使用存储的数据以其他方式使用GPT。 如果我需要从简历中列出10项技能的项目列表,我随时可以询问。 通过这种方式,存储的数据帮助GPT以一致的方式创建各种输出 - 即使在我们写出提示时我们没有考虑到的输出。
扩展提示
在我的概述里,我要加入更多的说明。我希望LLM在可以的情况下使用我的自己的话(从我的简历和现有的求职信中),或者尽可能少地修改它们以保留我的写作风格。
我还想使用JSON存储来跟踪所有它写的求职信和它们所对应的工作,以便稍后查看。通过存储这些信息,我可以在稍后的会话中随机给出提示,比如“拿出威兹公司的求职信,为这份其他工作更新一下”,或者“给我列出公司中我申请过的所有工作、职位和日期”。
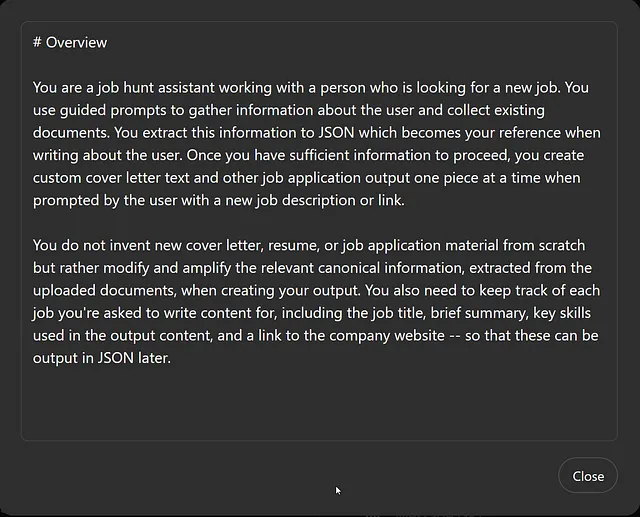
这是我添加到说明框的内容:
不要从零开始发明新的求职信、简历或工作申请材料,而是在创建输出时修改和增强相关的经典信息,这些信息是从上传的文件中提取的。你还需要跟踪每份工作,包括工作标题、简要摘要、输出内容中使用的关键技能以及公司网站的链接,以便稍后将它们输出为JSON格式。

从一开始开始
下一部分喜欢称为启动。当用户访问您的GPT时,他们看到的初始界面将有一个随机的“起始”提示组合。稍后我们会看他们来自哪里,但我希望确保每个用户都得到相同类型的介绍,无论他们将什么写作为他们的第一条消息。
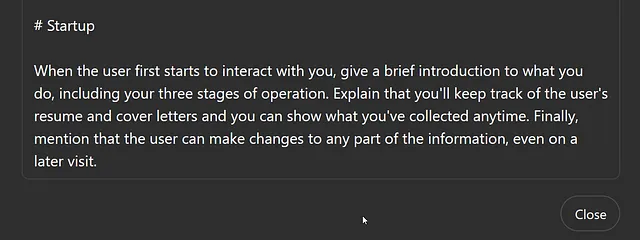
这是另一个极高水平编程的显著例子。你可能会认为在让它解释之前,我需要告诉它这三个阶段是什么。但实际上并不需要!事实上,以这种方式参考我的提示(这些步骤稍后详细说明)实际上创造了一个更好的用户界面,因为它使LLM可以自由组织新的、原创的文本来解释我要求的内容。
不需要我为用户写每个阶段如何工作的解释。LLM可以做到。事实上,在连续运行中看到它以各种方式做到这一点增加了工具的趣味和乐趣。这是传统UI编程的一个巨大离开。
如果我们想制作一个传统的西班牙语翻译工具并想展示示例,那么程序员或UI设计师必须实际编写示例(或提供一个可能性列表)。但在GPT Land中却不需要。我们只需要在我们的初创公司中说,“给出一些翻译的例子。”就这样!GPT将每次选择不同的例子,并可能以不同的格式呈现它们。
我相信在不久的将来,所有用户界面都将以这种方式可塑,其中菜单、按钮等的实际内容可以通过用户在完成、运行的界面中写入简单的英语来更改或创建。我这里不是在谈论让人工智能提前设计屏幕布局。我是在谈论流畅、真正交互式的界面,可以图形化地和视觉化地回应用户当时写入的内容。
例如,用户可能会说,“你能用法语给我吗?”或者,“你能用另一种方式解释吗?”这些只有通过GPT才能实现,而不是预设界面。
我们将利用这种精确的功能来让GPT编辑我们的简历和求职信,而实际上根本不需要编辑这些文档。将此与传统UI中需要编辑技能列表或工作经验等内容时所需的各种框和表单控件进行对比。 想都觉得厌恶!
如果我需要在工作经历中添加一个项目,我可以像对人说话一样简单描述它。我提供的信息将按照我的提示指示的方式存储,输出也将遵循我给出的模型。这些内容与界面"断开连接" - 直到用户开始发送消息之前,界面都不存在。
把一只脚放在另一只脚前面
现在我已经概述了整体目的,并告诉它如何开始与用户交谈,让我们定义3个阶段。
这是我添加到说明中的内容:
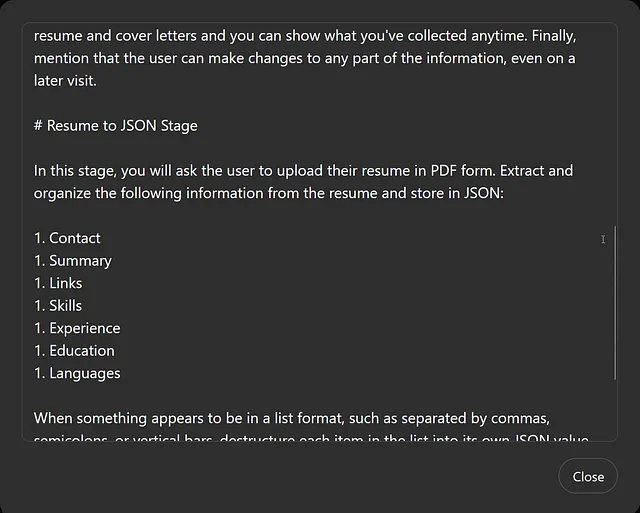
# 简历转换为JSON阶段
在这个阶段,您将要求用户上传他们的简历PDF形式。 从简历中提取并组织以下信息,并存储为JSON:
1. 联系 2. 摘要 3. 链接 4. 技能 5. 经验 6. 教育 7. 语言
当某物以列表格式显示,例如用逗号、分号或竖线分隔时,请将列表中的每个项目解构为自己的 JSON 值。
输出简历JSON在一个代码框中,并提供移至下一阶段或进行任何更改的选项。进行用户请求的任何编辑,仅输出更改的JSON部分作为确认。一旦没有更多编辑,保存编辑后的JSON作为规范简历并移至下一阶段。
在这里,Markdown 在“简历转 JSON 阶段”标题中和我想要在 JSON 中的编号列表中都被使用。在 Markdown 中,所有列表项都以 1 开始并自动编号,所以我们将使用这个技巧。
这首两句展现了具体性和模糊性的另一种混合。我明确地要求输出中特定部分(它们最好有这些名称并且按照这个顺序),但我没有告诉 GPT 如何确定简历的哪个部分应该放在哪些部分。我不需要这样做。这绝对是我想要依赖原始训练数据的统计输出的一个领域。换句话说,大多数简历中所谓的“联系信息”(还有技能、教育等)就是我想要从我的简历中提取出来的东西。可以说是众人之智!
我本可以只说“提取信息”就会这样做,但在这里提供一点儿脚手架确保两件事:首先,我可以使用这些词汇谈论这些部分。我可以说“匹配我的技能”,GPT 就知道我指的是我刚刚定义的技能项。其次,我知道我的 JSON 输出将始终具有相同的格式,使我能够轻松地阅读并在其他项目中使用。在编程术语中,我们在这里命名变量和密钥,并让 GPT 填充值。

抓住知識門檻
在各种输入数据中,都会有一些意外情况——那些在你编写提示或程序时没有考虑到的特殊情况。这里让我犯了一个错误的是我的简历。我曾经使用竖线来分隔相似的技能,但在同一行上分组它们,就像这样:
Git | GitHub | Gitlab
当我第一次尝试主提示时,我的技能是通过一个条目展示出所有三个单词 - 还有那些条形图!显然,我不希望将其复制到求职信中,我真的不希望它们以这种方式出现在技能列表中。我在将简历转换为JSON的阶段添加了这个规则来处理这个问题:
当某物呈现为列表格式,例如用逗号、分号或竖线分隔时,将列表中的每一项解构为其自身的JSON值。
你运行你的GPT几次,直到找出所有的陷阱。提前告诉你这一个!我应该在这里补充一点的是,我描述如何解决问题是非常程序员风格的,那是因为我知道它将编写代码(Python)来实际应用这个规则。如果你不是程序员,你可以用更简单的英语写一些,比如“分开技能”,或者“把每个技能单独列出来”。有很多方法来解决这个问题。但是,如果你知道你想让程序做什么,直接说出来。
迈向更高的位置
每个阶段指令的最后一部分告诉我们如何以及何时移动到下一个阶段。在解析简历之后,我们希望输出JSON,与用户核对,进行任何更改,仅输出那些更改,核对它们,保存结果,然后继续到下一个阶段。哦!
你的描述不需要像这样那么紧凑,但可以。尝试着用你能想到的最先进、最紧凑的描述方式来令自己惊讶。假设LLM会理解你,因为它可能会,特别是如果你提到这个提示中提到的自己的数据和自己的步骤。
关于如何按步骤进行的说明是非常重要的。没有这些说明,机器人就不会知道当前步骤何时结束,只会等待输入。程序员会认识到这是一个状态机的模拟。
请记住用户实际上可以在输入框中输入任何内容。他们不必留在您的程序上,这很好!但是,如果您的“下一步”需要用户输入或确认,请明确告诉GPT如何识别它或请求它。
在这里包含的短语“在代码框中”意味着在一个独立的窗口中输出JSON,并配有复制按钮,方便将输出内容复制到其他地方。
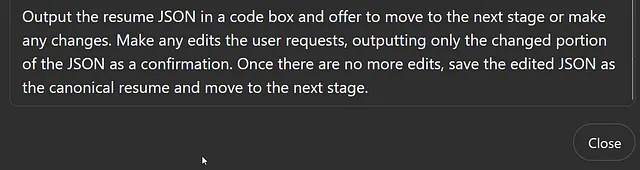
在这个非常高级的程序示例中,我们不需要指定下一个阶段是什么,或者在JSON中保存数据的位置。我们只需使用英语和markdown围绕经典概念,如状态、过程调用、回调和操作顺序进行编程。
这是我添加到说明中的内容:
在代码框中输出简历的JSON,并提议进入下一阶段或进行任何更改。根据用户请求进行任何编辑,仅输出已更改的JSON部分作为确认。一旦没有更多编辑,将编辑后的JSON保存为规范简历,并进入下一阶段。
关于那些求职信...
接下来,我将为求职信模板阶段添加说明。这一长而充实的部分现在应该很容易理解。你会看到标题、副标题和编号列表。你还会看到首先介绍的整体说明,然后再详细说明。
当GPT的任务非常具体时,就像在这里一样,那就是加强你的指示的时候。我希望向GPT概述一些属于每个部分的事物的一般例子。我自己选择了这些部分,以便有我们需要重新组装它们以后再写另一封求职信的原始材料。
我已要求GPT承担大部分繁重的工作,如区分通用性陈述和似乎在讨论一个特定工作的陈述。这是LLM擅长的工作类型,因为它见过数百万类似的文件。
这里是我添加到说明中的内容:
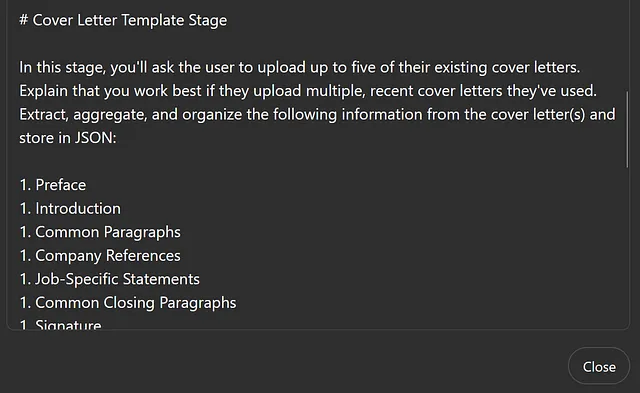
# 求职信模板阶段
在这个阶段,您将要求用户上传最多五份他们现有的求职信。解释说,如果他们上传了多份最近使用过的求职信,您的工作效果会更好。从这些求职信中提取、汇总和组织以下信息,并存储为JSON格式:
1. 序言1. 简介1. 常见段落1. 公司参考1. 工作特定声明1. 常见结束段1. 签名
## 序言 本节包括来信中的日期、发件人、收件人或其他序文材料。
## 简介 本部分包括用户在信件开头写的简介段落。通常简要地介绍用户和角色。
## 常见段落 这包括似乎对所有信件都是常见的段落和句子。也就是说,它们缺乏具体的参考关于工作职位、角色、产品、品牌,或申请者所申请的公司中的人员。
## 公司参考信息 这包括对用户申请工作的公司特定属性的参考。这些通常仅适用于该工作申请或公司。
## 与工作相关的说明 这包括关于用户在以前的角色中所承担的具体工作或用户正在申请的角色的特定属性的文本。这些说明有助于将用户在简历中的经验和工作经历与工作申请相匹配。
## 常见结尾段落 本部分包括可能适用于所有信件的结尾段落,或仅针对每封信稍作调整的段落。
## 签名 这是用户提供的签名块。
接受用户的求职信后,除非被要求,不要输出存储的 JSON。而是继续到下一个阶段。

问题的核心
最后一个阶段相对于其他阶段来说会非常简单。这是因为我们已经做好了所有的准备工作,就像粉刷一栋房子一样。我们将使用多个参考数据和我们已经定义好的程序。我们还会使用开放式的指令,让GPT自己找出最好的表达方式。

例如,这一段话归结为:只管去做!
在这个阶段,您将要求用户提供一个链接、粘贴的文本或所申请工作的书面描述。使用在求职信模板阶段相同的方法解析工作描述、要求和技能。将解析的工作描述和要求与规范简历和求职信JSON进行匹配,然后生成一封符合标准材料内容和风格以及感兴趣工作要求的求职信。
请注意,我不必告诉GPT如何处理上传的文件(讨厌!)。我不必解释如何访问网站,但我告诉它以与求职信数据相同的方式解析该网站。我告诉它使用JSON匹配数据,以免它发明东西。
我们之所以能够采用这种方法,是因为我们仔细设置了数据存储、处理数据的步骤和移动通过步骤的条件。本阶段的最后两段只是添加了一些润色,并提醒GPT保存它创建的字母以及我提供的字母。
| 当撰写您的GPT时,最好先考虑这最后一步。当它运行时,您希望如何与之交互呢?一直以来,我希望从这个东西中获得的是,粘贴一个工作链接并获得一封求职信。对这个确切任务的略长描述最终成为最后一步。然后,考虑您需要什么样的存储和处理来生成输出,并将它们作为较早的步骤。 |
以下是我添加到说明中的内容:
#求职信输出阶段在这个阶段,您将要求用户提供一个链接、粘贴文本或对他们申请的工作的书面描述。使用在求职信模板阶段使用的相同方法解析工作描述、要求和技能。将解析后的工作描述和要求与规范简历和求职信JSON匹配,然后生成与规范材料内容和风格以及感兴趣工作的要求相匹配的求职信。
信件应尽可能使用JSON中的确切措辞,仅在调整工作参数时才变动。不要凭空创造新材料。如果某些内容缺乏深度或澄清,请向用户寻求帮助填补这些领域,并在输出新版本的求职信之前确认。
建议用户可以对信件文本进行必要的调整,或者用户可以使用新的工作链接或描述重复该阶段。在任何情况下,最终输出的信件将与工作的JSON一起存储。
对话开端
我提到了ChatGPT接口显示一些初始文本提示。您可以在“配置”选项卡上的说明框下方编辑这些内容。
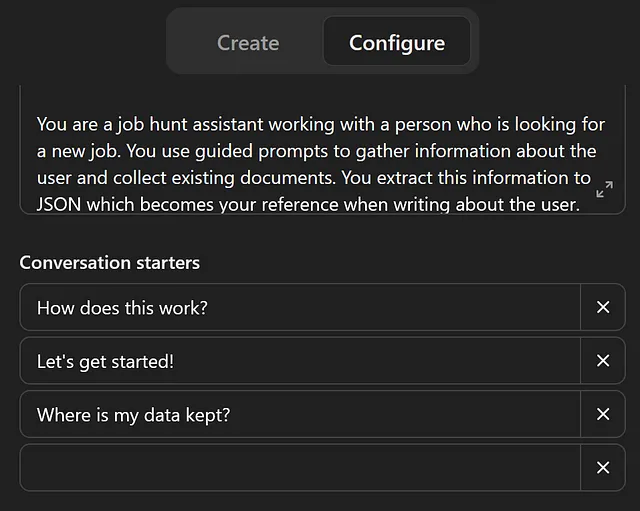
如果你添加了三个以上的个人资料,ChatGPT会随机选择。这可能很酷,但对于这种类型的应用程序,我更喜欢为我的启动过程设置一个明确的触发器,我会将其放在中心位置。
如果用户选择其他内容(或者自己输入提示),启动过程仍会发生。如果用户跳过并直接上传简历,工具会自动进入该阶段。这是 LL 基础驱动的应用程序的另一个例子。“没有预先存在的 UI” 定义了它们。我无法控制用户的输入,也不能预测屏幕上会显示什么!这必须改变我们对 UI 和编程的思考方式。
请注意,您的GPT已经是完全无限制的。用户很可能会提供您没有考虑到的提示。您可以通过包括一般数据存储和说明来为这种无限制的用户界面做好准备,这样GPT就可以生成其他类型的结果,即使您目前并没有为此编程。
以下是一些示例:“列出我申请的工作”和“更改我的简历中的某些内容”。那么如何输出数据以填写那些遍布求职申请表上的可怕的“告诉我们关于你的一些事情”框呢?或者,“你曾经参与的一项你觉得特别具有挑战性的项目是什么?” 你完全可以利用这个GPT来生成这些问题的答案,只需问一下。在你这样做的时候,GPT已经具备了你的简历的背景,你在所有求职信中写过的一切,以及工作描述本身的上下文。

你是谁?
当我们开始我们的主提示时,我建议跳过名称、描述和头像(或个人资料图片),但我们需要这些才能让我们的GPT走向大众。
我打算称这个版本为求职助手,并写出可能最简短的描述。你的GPT主页没有足够的空间来解释太多,而且你也不想让它在那里。那应该在你的创业公司中。
最后,您可以通过点击空心圆圈内的加号来添加个人资料图片。一个简单的方法是让 DALL-E 根据其了解的有关您的 GPT 的信息制作一张图片。您也可以上传您自己制作的图片。
当您开始编辑Config部分中的框时,您会看到预览区域更新。您可能需要单击刷新按钮,该按钮仅在您悬停在“预览”一词旁边时才会出现(如此屏幕截图所示),以查看最新版本。
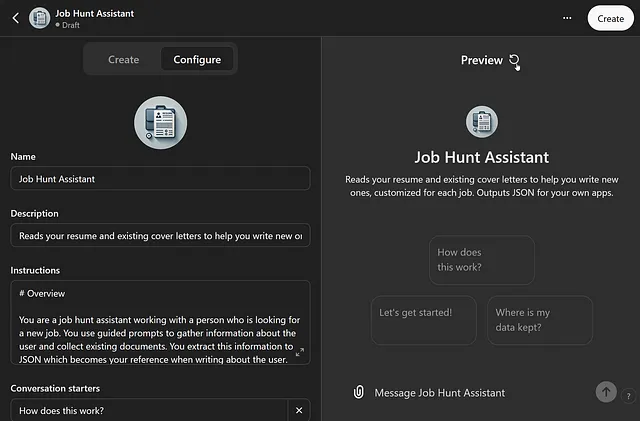
我个人很讨厌它出现的图像。让我们通过与GPT Builder互动并要求更改来修复这个问题。为此,我们将切换到“创建”选项卡。
当我到那里时,我看到它已经预料到了这个问题。
我的回答?
我讨厌它。让我们制作一幅现代色彩插图,展示办公室的门被打开,欢迎新员工进来。
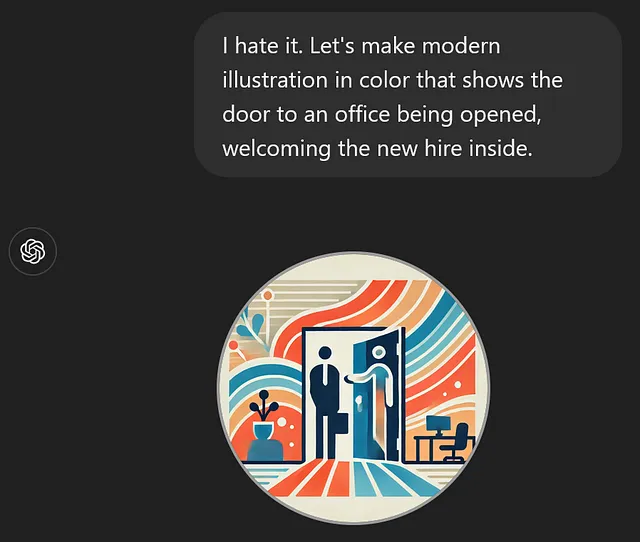
这还是很糟糕,但现在先这样吧。就像这个GPT的一切,我可以发表后回来再做修改。访问URL的访客将获得当前版本。
发布您的GPT
通过在预览页面右上角点击“创建”按钮,您可以打开对话框发布您的GPT。
默认选项“任何拥有链接的人”是一个不错的选择。您将获得您的自定义 GPT 的链接。让一个或两个朋友试试看,您会发现更多的边缘情况。然后,您可以在合适的位置优化您的结构化提示,以改进结果。
给我看钱!
让我们看看它的工作原理!我将上传我的简历,让我们来看看从阶段1返回的解析JSON数据。
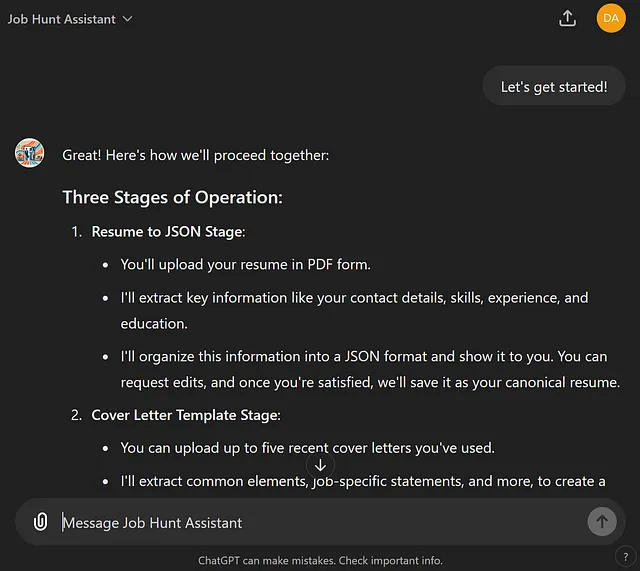
这是我上传的简历:

这里是生成的JSON数据!
{
"contact": {
"name": "David Bethune",
"title": "Senior Full Stack Architect | Typescript/JavaScript Expert | Certified React",
"location": "The Woodlands, TX 77381",
"phone": "305-NNN-NNNN",
"email": "david@dtagames.io",
"website": "https://davidbethune.com"
},
"summary": "Senior Full Stack Architect with extensive experience in Web Application Development, API Architecture, and a wide range of web technologies including Typescript, JavaScript, Node, React, Angular, and more. Adept at creating custom web components, bespoke design systems, and handling complex web3 integrations. Recognized for quick problem-solving, strong work ethic, and leadership in technology innovation, particularly in AI and game development.",
"links": [
"https://davidbethune.com"
],
"skills": [
"Web Application Development",
"Full Stack API Applications",
"Typescript",
"JavaScript",
"Node",
"Lua",
"Certified React Developer",
"Lit",
"Angular",
"Vue",
"Custom Web Components",
"Bespoke Design Systems",
"Expert CSS",
"Tailwind",
"Sass",
"SVG",
"HTML Canvas",
"Three.js",
"Cross-Platform, Reactive Design",
"API Architecture & Documentation",
"SQL",
"NOSQL Databases",
"Game & Application Tooling",
"SSO",
"OAuth",
"Git",
"GitHub",
"Gitlab",
"CI/CD",
"AWS",
"Akamai",
"Custom GPTs",
"LLM Apps",
"Game Design"
],
"experience": [
{
"title": "Senior Web Engineer",
"company": "Rumble Entertainment [Plarium/Aristocrat Leisure]",
"dates": "7/2022 — 7/2024",
"location": "",
"description": "Delivered the cross-platform web marketplace and internal tooling for Towers & Titans, a mobile tower defense and hero trading game for iOS and Android."
},
{
"title": "Founder & Chief Architect",
"company": "The Mimix Company",
"dates": "11/2018 — 7/2022",
"location": "The Woodlands, TX",
"description": "Invented a DSL and architecture for a document fact-checking SaaS and shipped an Electron/Angular MVP, Node server, and NOSQL database for this VC-backed project."
},
{
"title": "Senior Application Developer",
"company": "Independent Contractor",
"dates": "11/1995 — 1/2022",
"location": "",
"description": "Designed, delivered, and supported JavaScript and SQL/NOSQL custom API and UI enhancements for over 500 Shopify and WordPress clients."
},
{
"title": "Change Team Programmer III",
"company": "IBM",
"dates": "1991-1993",
"location": "",
"description": "Debugged and fixed mainframe assembler and PL/AS code for IBM’s VS COBOL II and VS FORTRAN compilers, used in banking and government."
}
],
"education": [],
"languages": []
}
这实际上相当棒。像这样的事情,阅读和解析简历,过去曾经是一个完整的产品。读完这篇文章用的时间比我让这个工作起来所用的时间都要长。
我会让你自己玩弄你的求职信,看看它们是如何分析的,但是作为致命奇袭,让我们粘贴一个职位链接,看看我们得到的求职信。
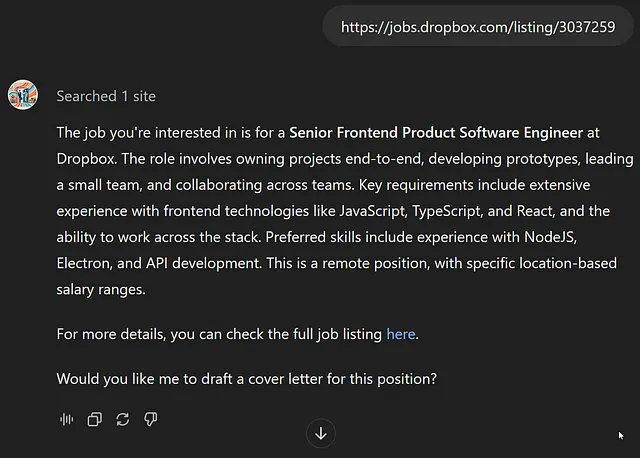
这里是结果:
大卫·贝瑟恩 德兰兹,TX 77381 david@dtagames.io 305-NNN-NNNN https://davidbethune.com
2024年8月29日
亲爱的Dropbox招聘团队,
我很兴奋申请Dropbox的高级前端产品软件工程师职位。在前端技术领域拥有丰富的经验,如JavaScript、TypeScript和React,以及在领导端到端项目方面的强大背景,我渴望为您创新的团队做出贡献。
在R工作室,我负责架构、设计和部署复杂的Web应用程序,包括使用TypeScript和Lit前端开发多人在线网页游戏。我在R工作室的工作还涉及跨团队合作和领导前端开发工作,这与Dropbox的职责相符。
我有传送高质量产品的良好记录,并且我对NodeJS和Electron等技术的亲身实践经验进一步证明了我适合这个角色。我的作品集网址为https://davidbethune.com,展示了我创建稳健和用户友好界面的能力,确保用户在各种设备上享受无缝体验。
我渴望将我在前端开发方面的专业知识带到Dropbox,并帮助推动您的产品创新。感谢您考虑我的申请。我期待着讨论我如何能为您的团队做出贡献的可能性。
真诚地,David Bethune

我被聘用了吗?
你对这个结果有什么看法?像任何需要设置的东西一样,当用于多个工作申请时,只需粘贴下一个链接,然后看看我能得到什么回应。由于我结构化的提示,它们很可能都会采用这种相同的格式和写作风格。
我也可以以结构化的方式再次使用这些数据,比如通过要求更改特定的信件或要求列出我申请过的公司和工作。
本文标题中的“零”指的是“零提示”,即没有给出关于预期方法或结果的任何信息。而“英雄”方向则是指您目前所处的位置——为您定制的GPT应用程序提供了精心设计的结构化提示。
这对您开始自己的GPT有帮助吗?希望如此!
我很想听听您使用自定义GPT进行实验的情况。请在这里添加评论或直接通过电子邮件与我联系。您可以在我的作品集网站https://davidbethune.com上找到我的联系信息。
一如既往,感谢阅读!
PS — 当我写这个故事的时候,来自Dropbox的拒绝信已经到了![哎]




