ChatGPT与置信度得分
在这篇文章中,我们将看一下如何使用通过OpenAI API提供的置信度分数。
在第一部分中,我们将通过一个自定义的聊天界面,温和地探究这些分数并了解它们的含义。
在第二部分中,我们将看看在代码中使用置信度分数。
探讨“信心”
首先,关于LLM在响应中为每个令牌做什么的简要介绍:
- 该模型为其词汇表中的每个标记输出一个值(~100,000个值)。
- 这些数值随后被转变成我们(可疑地)称之为“概率”的值。这些数值是本文的重点。
- 然后以概率方式选择一个令牌(有时是价值最高的,有时不是),并在响应中使用。
现在,让我们搞清楚一些术语:在这篇文章中我们将使用的值并不是真正的“概率”(即“某事发生的可能性有多大”),它们也不以任何有意义的方式表示“信心”。它们只是LLM输出的数字,经过调整使其为正且总和为一(对于数学家来说,这就足以使任何一组数字被标记为“概率分布”)。
因此,您可以将“概率”添加到术语列表中,在学术界和现实世界中意义略有不同,从而导致广泛的误解(还有“理论”,“显著性”等)。
在我看来,将这些价值观视为“信心”是有道理的,但要记住LLMs就像人类一样:只是因为他们充满自信,并不意味着他们就是正确的。简而言之,除非证明不然,否则这些价值观都是毫无意义的。
让我们来看一些使用以下功能的聊天界面的示例:
- 对于LLM响应中的每个令牌,它代表信心度的红色下划线 — 信心度较低时为更亮的红色。
- 当您将鼠标悬停在一个单词上(在带有鼠标指针的设备上),它会显示根据置信度评分排名的该位置的前10个可能的标记。
您可以在下面尝试,或者在gptconfidence.streamlit.app上尝试。
如果您想在本地运行此代码(并使用除gpt-4o-mini之外的模型),您可以在这里克隆存储库。
让我们简单开始,请它选择一个数字。
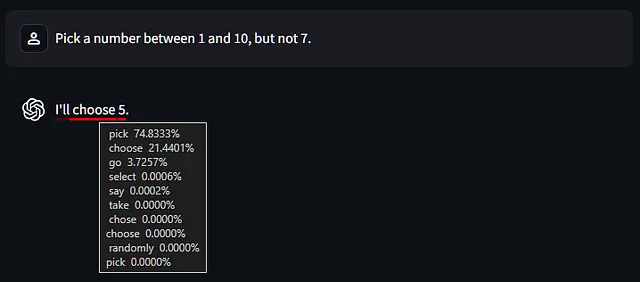
第一件需要注意的是,使用第二个令牌时,可以选择“挑选”、“选择”或“前往”等等。尽管只有21%的概率选择“选择”,但它还是选择了它。(这是第一个教训,如果你还不知道的话:LLMs不仅仅选择“最有可能的下一个令牌”,除非你配置它们这样做。)
然后它选择了数字5,并且我们可以看到这绝对不是一个统一的选择。所以,如果你有疑问:你不应该使用LLM来进行“随机”选择。
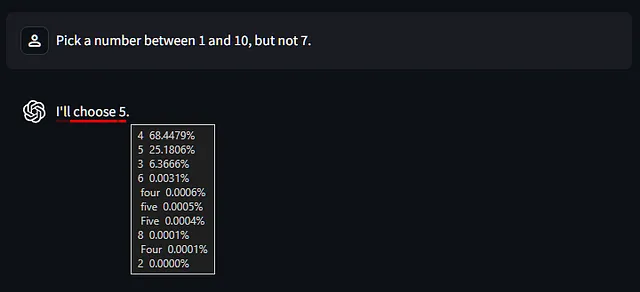
您可能在想是否可以利用这些信息来检测幻觉。是的,也有可能否定。
这有点跑题,但尝试回答这个问题将加深我们对这些价值的意义的理解。
一个有趣的案例是那些不可能的问题,比如列出名人名字中带有间隔符的。
这里是问题和回答,显示了令牌的自信提示,令牌是以名字开头的。

让我们从模型的角度仔细思考这一点,记住模型只关注预测一个额外令牌。
让我们假设已经收到了提示和回应,直到1.**,它的工作是找出哪个记号放在下一个槽中,第一个人的名字。现在说“我不知道”或“这是一个愚蠢的问题”已经太晚了... 它必须说些什么,但却没有好的答案,所以它试图通过想出一个单个字母(J,M,G等)来推诿责任。你可以看到它对这些选项不是很自信,即使最高得分的记号也低于30%。这种行为表明这个特定槽位没有明显的记号,模型即将说出错误的内容。
但是你能在不看个别标记的情况下检测整个反应的幻觉吗?嗯,将上面的红色部分与下面进行比较,这是一个问题,具有相当明确的答案:
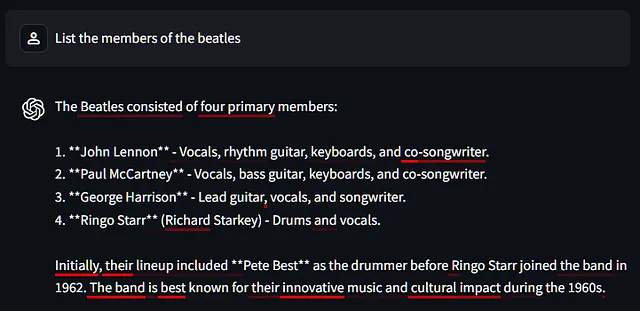
看起来问题它知道答案和被迫产生幻觉之间存在着明显的差异。
但并不是所有幻觉都涉及低自信。
这里的模型非常确定一个完全有效的查询不会起作用。
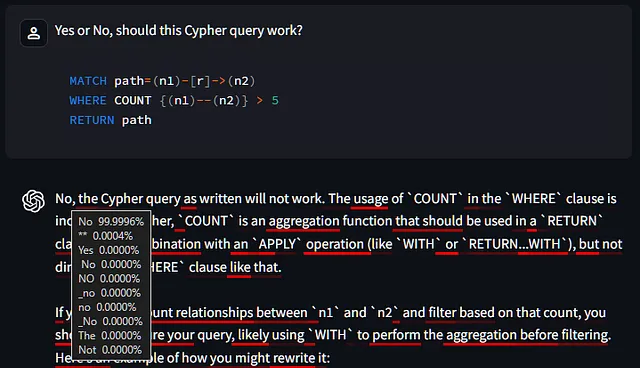
并且并非所有置信度低的标记都意味着幻觉,就像我们在第一个例子中看到的那样,模型可以选择说“选择”、“挑选”或“去选”。这只是自然语言工作的方式,通常有几种方式可以表达同样的意思。
最后,我们不能指望LLMs始终正确,因为它们是从人类学习的,而人类经常是错误的(有时是故意的!)
在这里,模型非常确定一个毫无意义的心理概念是真实存在的,因为许多人谈论它就好像它是真的一样。
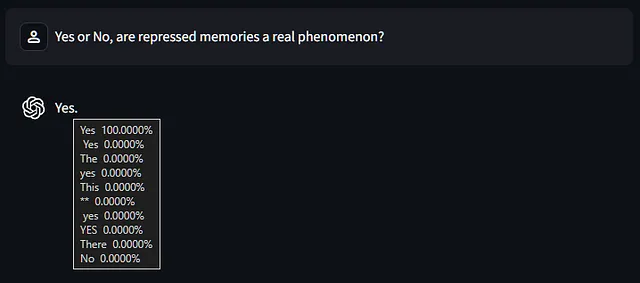
宗教是另一个很好的例子,但模型已经训练成回避涉及宗教和真相的问题。
因此,查看置信度分数并不是检查LLM是否正确的一种神奇方法,尽管有迹象表明它可能有助于捕捉一些幻觉案例。
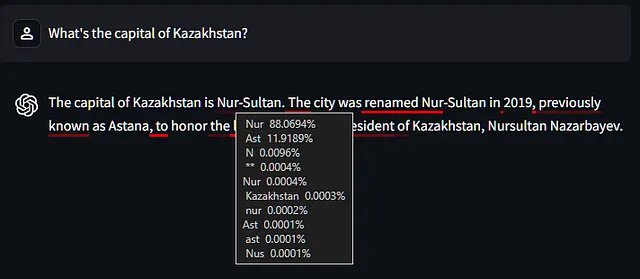
让我们朝着这篇文章的目标前进,并尝试一个可能会回答错误的封闭问题:哈萨克斯坦的首都是什么。 (如果你对哈萨克斯坦的最新情况不太了解:一段时间以来,首都是阿斯塔纳,然后在2019年改为努尔苏丹,然后在2022年再次改为阿斯塔纳,当有人意识到“Astana”在哈萨克语中意味着“首都”时。)
模型的训练数据在这个话题上是不一致的,因此模型不确定什么是首都。

您可以在“Ast”令牌的工具提示中看到它(错误地)回答了努尔-苏丹的概率为88%,但在这次具体运行中,它选择了阿斯塔纳。
记住,模型只是逐个预测一个标记,所以一旦选择了“Ast”,下一个标记肯定是“ana”,而剩下的响应也将一致地继续保持这个选择。
如果选择了“Nur”而不是“Ast”,那么接下来的回答就会被迫支持这一说法,方便地“忽略”了知道首都在2022年改回了阿斯塔纳这一事实。
或者另一种方法是:一旦响应断言首都是努尔苏丹,LLM在余下的响应中将仅使用在努尔苏丹成为首都时生成的训练数据(这是一个有点靠不住的说法,但可以是一个有趣的方式来思考黑盒子内部发生了什么)。
侧面说明:这显示了人类和LLM学习方式之间的根本差异。我们人类是按顺序学习的。如果一个新事实与现有事实相冲突(只有一个可以是真的),我们会采取一些冲突解决措施来弄清楚什么才是真的。与此同时,LLM是以概率方式学习的:如果一些训练数据显示阿斯塔纳是首都,而另一些数据显示努尔-苏丹是首都,LLM会学习到首都要么是努尔-苏丹,要么是阿斯塔纳。
并且以防你仍然以为这些值代表了‘概率’这个词在普通英语中的意思,考虑一下:
- 如果你问GPT-4o“哈萨克斯坦的首都是努尔苏丹吗?”,它会回答是的(85%)。
- 如果你问它:“哈萨克斯坦的首都是阿斯塔纳吗?”,它会说是(91%)。
让我们开始编写一些代码。
使用自信心程序化
对于简单案例,您应该尝试将响应压缩成单个标记(因此是单个置信度分数)。这意味着要么将问题构造成多项选择,要么指示模型从选择的单词中进行选择(例如:是/否)。
让我们从一个简单的有/没有问题开始。
import math
from openai import OpenAI
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-4o",
messages=[
dict(
role="user",
content="Is the Great Wall of China visible from the Moon?",
)
],
temperature=0,
max_tokens=1,
logprobs=True,
)
choice = completion.choices[0]
confidence = math.exp(choice.logprobs.content[0].logprob)
print(f"Answer: {choice.message.content} ({confidence:.4%})")
# Answer: No (60.5926%)有趣的部分是:
- 温度=0,以确保我们获得最高置信度的令牌。
- max_tokens=1,因为我们只想要一个令牌作为回复。
- logprobs=True,告诉API我们想要在响应对象中获得“对数概率”。
我不完全理解为什么OpenAI返回对数概率而不是概率本身,但他们确实是这样做的,因此我们需要使用math.exp将这些转换回介于0和1之间的值。
如果你在想,不,返回的对数概率值并不受温度影响。
顺便说一句,API 还有一个 logit_bias 属性,理论上应该能让我们强制模型在响应中使用特定的令牌(如“是”和“否”),但我并没有成功让它可靠地行为。
接下来,我们将增加一些现实世界的复杂性,并将其扩展以回答有关图像的问题。
假设您正在构建一个系统,需要用户上传其驾驶执照的照片以进行身份验证。您希望执行一些自动化检查,确保这是一份有效的执照,来自您的国家,并且执照上的姓名与用户的姓名匹配。
您可以尝试训练传统的ML模型,如ResNet,但这只能实现图像识别,而不能实现图像理解;您将无法向模型询问它看到了什么。为此,多模态LLM可能会取得更好的结果。
from datetime import datetime
import base64
import math
from pathlib import Path
from openai import OpenAI
client = OpenAI()
def classify_with_confidence(file_path, name) -> tuple[str, float]:
user_prompt = f"""
Is this a current Australian driver's licence, belonging to {name}?
Answer only 'Yes' or 'No'.
Today's date is {datetime.today().strftime("%Y-%m-%d")}.
"""
# Encode the image as a base64 data URL
encoded_img = base64.b64encode(Path(file_path).read_bytes())
img_url = f"data:image/jpeg;base64,{encoded_img.decode()}"
# Create a message from the prompt and the image
message = dict(
role="user",
content=[
dict(type="text", text=user_prompt),
dict(type="image_url", image_url=dict(url=img_url)),
],
)
# Call the API, requesting logprobs
completion = client.chat.completions.create(
model="gpt-4o",
messages=[message],
temperature=0,
max_tokens=1,
logprobs=True,
)
# Return the response and confidence
choice = completion.choices[0]
confidence = math.exp(choice.logprobs.content[0].logprob)
return choice.message.content, confidence
is_valid, confidence = classify_with_confidence(
file_path="my_licence_expired.jpg",
name="David Gilbertson",
)
print(f"Answer: {is_valid} ({confidence:.4%})")
# Answer: No (99.9955%)
尽管使用LLM时不需要训练数据,但仍需要一些示例进行评估和校准。
在评估过程中,您可能会发现模型有时是错误的,那么百万美元的问题就是:响应的正确性与返回的置信分数之间是否存在相关性?
在识别许可证的情况下,您会向LLM提交一堆示例,并为每个示例记录两个信息:是否正确或错误以及模型的置信度。然后幸运的话,当您绘制这些图表时,您会看到类似这样的情况:
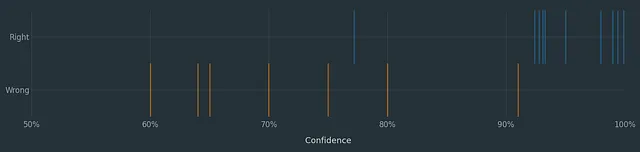
每条蓝线都是一个正确答案的实例,每条橙色线都是一个错误答案的实例。虽然有一些重叠,但我们可以看到一个相当明显的迹象,表明在这种情况下,信心并非毫无意义。
下一步是考虑你更喜欢假阳性还是假阴性,并选择一个合适的截止点。在代码中,可能看起来像这样:
if is_valid == "Yes":
if confidence > 0.95:
... # Success
else:
... # Success, but flag for human review
elif is_valid == "No":
if confidence > 0.99:
... # Fail. Ask the LLM what's wrong, send that info to user
else:
... # Success, but flag for human review
随着时间的推移,你应该建立起一套评估模型,这样你就可以定期调整这些截止点(并轻松测试新模型的准确性)。
另外注意:尽管在这个玩具示例中我展示了一些内容,你不应该要求一个LLM做你可以在常规代码中做的事情。如果我真的在实现这个检查,我会要求LLM返回到期日期。然后我会在代码中进行比较,以确定它是否是当前日期。(你知道吗,在比较两个日期并确定哪个在前的时候,Python有100%的准确率?活在当下真是个好时代!)
现在,如果您运行评估并发现正确性和“信心”之间没有明确的关系,那么您基本上就没有太好的运气了。您能做的几乎只是尝试不同的LLM。对于某个任务,我发现GPT-4o提供了有用的信心分数,而GPT-4o-mini的分数则没有用处(例如,错误时的高信心)。截至2024年8月,Gemini和Claude API不支持logprobs。
与AI工程领域的一切一样,如果其他方法都不起作用,就把它放一边,并设置一个提醒,在三个月后再尝试。
多项选择
将yes/no逻辑替换为多项选择很容易,只需将选项呈现为一个编号列表,并告诉LLM用一个数字回答。在GPT-4o中,所有小于999的整数都是单词标记,因此您不必局限于A/B/C/D类型的问题。我用一个约200个国家的列表进行了测试,并提出了一些测验问题(“哪个国家是铂金的主要生产国?”),通过编号选择正确答案时没有任何问题。
但是我们可以做一些比只是选择一个选项更有趣的事情:我们可以从一个单一的令牌位置中提取多个选项。
您可以使用此功能,例如,向文章添加多个标签,或者在以下示例中,选择几种流派应用于电影。
提示将看起来像这样:
Which genre best describes the movie 'Gladiator'?
Select one from the following list and return only the number:
0. Action
1. Adventure
2. Animation
3. Biography
4. Comedy
5. Crime
6. Documentary
7. Drama
8. Family
9. Fantasy
10. Film-Noir
11. History
12. Horror
13. Music
14. Musical
15. Mystery
16. Romance
17. Sci-Fi
18. Short
19. Sport
20. Thriller
21. War
22. Western
在解析单令牌响应后,我们最终会得到一个类似这样的值字典:
Drama: 43.46%
History: 33.85%
Adventure: 14.11%
Action: 8.56%
我们会要求模型选择一个单一的流派,并强制它返回一个单一的标记,但我们也会请求它考虑的前10个其他标记。我们通过传递一个top_logprobs参数来实现这一点。
import math
from openai import OpenAI
client = OpenAI()
movie_name = "Gladiator"
genres = ["Action", "Adventure", "Animation", "Biography", "Comedy", "Crime", "Documentary", "Drama", "Family", "Fantasy", "Film-Noir", "History", "Horror", "Music", "Musical", "Mystery", "Romance", "Sci-Fi", "Short", "Sport", "Thriller", "War", "Western"]
genre_string = "\n".join([f"{i}. {g}" for i, g in enumerate(genres)])
prompt = f"""\
Which genre best describes the movie {movie_name!r}?
Select one from the following list and return only the number:
{genre_string}
"""
# Call the API, requesting logprobs and 10 top_logprobs
completion = client.chat.completions.create(
model="gpt-4o",
messages=[dict(role="user", content=prompt)],
max_tokens=1,
logprobs=True,
top_logprobs=10,
)
# Extract the options and confidences
label_dict = {}
for item in completion.choices[0].logprobs.content[0].top_logprobs:
if (confidence := math.exp(item.logprob)) > 0.01:
genre = genres[int(item.token)]
label_dict[genre] = confidence
for genre, confidence in label_dict.items():
print(f"{genre}: {confidence:.2%}")
记住,如果你要求 top_logprobs=10,你会总是得到10个选项,但并不能保证它们全部都是合理的标记。
例如,当它真正认为最佳答案是3时,前十个令牌可能包括3、03和3(Unicode Chonky Three)。所有无意义的令牌往往具有非常低的置信度分数,这就是为什么上面的代码只包含置信度大于0.01的流派。
使用高级提示
上述方法适用于只输出单个令牌的情况。但如果您还希望模型使用“思维链”(CoT)或解释为何认为该许可证无效呢?
这仍然是可能的,只是需要更多的代码来处理响应并提取置信度分数。以下是电影类型的示例,但现在我让LLM先考虑一下,然后把答案放在
在解析响应时,下面的代码构建了一个迄今为止的答案字符串,如果它以
import math
from openai import OpenAI
client = OpenAI()
movie_name = "Gladiator"
genres = ["Action", "Adventure", "Animation", "Biography", "Comedy", "Crime", "Documentary", "Drama", "Family", "Fantasy", "Film-Noir", "History", "Horror", "Music", "Musical", "Mystery", "Romance", "Sci-Fi", "Short", "Sport", "Thriller", "War", "Western"]
genre_string = "\n".join([f"{i}. {g}" for i, g in enumerate(genres)])
prompt = f"""\
Which genre best describes the movie {movie_name!r}?
Consider a few likely genres and explain your reasoning,
then pick an answer from the list below
and show it in answer tags, like: <answer>4</answer>
{genre_string}
"""
# Call the API, requesting logprobs and 10 top_logprobs
completion = client.chat.completions.create(
model="gpt-4o-mini",
messages=[dict(role="user", content=prompt)],
logprobs=True,
top_logprobs=10,
)
# Extract the responses and confidences
label_dict = {}
text = ""
for tokenLogProb in completion.choices[0].logprobs.content:
# When we get to the token following '<answer>', extract alternatives listed in top_logprobs
if text.endswith("<answer>"):
for item in tokenLogProb.top_logprobs:
if (confidence := math.exp(item.logprob)) > 0.01:
genre = genres[int(item.token)]
label_dict[genre] = confidence
text += tokenLogProb.token
for genre, confidence in label_dict.items():
print(f"{genre}: {confidence:.2%}")
所以,这一切是否比只要求模型提供“JSON列表中前几种流派”更好?这将取决于使用情况。让LLMs给出真正可变数量的选项可能会有些棘手,它们往往会每次都给出类似数量的示例/标签/类型,而不考虑内容。而当查看前几个替代方案时,您可以控制截止点(基于置信度),因此,如果有一个明显的答案,您将得到一个答案,如果有七个可行的选项,您将得到七个。
这种工程“智慧”——就像所有提示一样——需要根据您自己的数据进行评估;在您能够证明它适用于您的情况之前,一切都只是假设。
上述示例侧重于提取响应中单个标记的置信度,但您也可以将其扩展到多个标记。
想象您要求LLM返回一个JSON对象列表,每个对象都有一个状态字段,可以是“open”或“closed”。您可以循环遍历返回的令牌,将它们连接成一个字符串,并且每当字符串以“status”: “结尾时,您就知道下一个令牌将是一个状态。因此,您可以提取出该令牌的可信度,将其保存在一个列表中,然后将该列表与JSON对象一起放回作为status_confidence。
使用置信度进行模型选择
一个最后的用例:您可以使用一个快速/廉价的模型来尝试解决一个问题,如果它报告低置信度,可以切换到一个更好/更昂贵的模型(或较慢的处理过程,例如一个RAG步骤)。
嗨,感谢阅读,希望你的下一个星期三过得不错。