Qwen2-VL:阿里巴巴在视觉语言人工智能领域的改变者
在人工智能不断发展的领域中,阿里巴巴再次展示了其实力,推出了Qwen家族中最新、最先进的视觉-语言模型Qwen2-VL。这一发布标志着人工智能在理解和与周围世界互动方面迈出了重要的一步,为视觉和文本理解设立了新的标准。
在制作一年后:进化至Qwen2-VL
经过一年不懈的发展,Qwen2-VL作为一种最先进的工具出现,旨在处理各种复杂任务。它借鉴了其前身Qwen-VL的优势,同时引入了开创性的新功能,使其成为当今最多才多艺、强大的视觉语言模型之一。
那么,是什么让Qwen2-VL脱颖而出呢?
- 现代视觉理解技术:Qwen2-VL在处理不同分辨率和比例的图像方面表现出色,实现了在行业基准测试中的最佳性能,如MathVista、DocVQA、RealWorldQA和MTVQA。无论是识别手写文本,理解图像中的多种语言,还是解析物体之间复杂的关系,Qwen2-VL都能以前所未有的准确性完成。
- 视频理解进阶: 与许多模型在处理视频内容时困难重重不同,Qwen2-VL被设计用于理解超过20分钟的视频。这种能力为高质量的基于视频的问答、实时对话,甚至内容创作开启了新的可能性。
- 智能代理功能:Qwen2-VL 不仅局限于 passively 的理解,它还能够主动操作诸如手机和机器人等设备。凭借其增强的推理和决策能力,它可以根据视觉环境和文本指令自动执行任务,使其成为自动化的强大工具。
- 多语言文本支持:Qwen2-VL 设计时考虑了全球用户。除了英语和中文,它支持对包括大多数欧洲语言、日语、韩语、阿拉伯语和越南语在内的多种语言进行文本理解。这使得 Qwen2-VL 成为那些需要在不同语言环境中运行的应用程序的宝贵资源。
我们以Apache 2.0许可证开源Qwen2-VL-2B和Qwen2-VL-7B,并释放了Qwen2-VL-72B的API!这些开源项目已集成到Hugging Face Transformers、vLLM和其他第三方框架中。希望你喜欢!
执行
基准性能:Qwen2-VL vs. 竞争对手
Qwen2-VL 已在六个关键维度上经过严格测试:
- 复杂的大学级问题解决
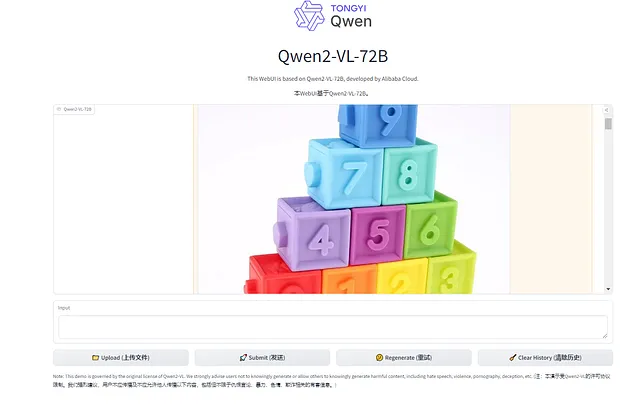
图像显示了一堆有数字的彩色方块。 从上到下,这里是每个方块的颜色和数字:
- 顶部一行(从左到右):蓝色(9),浅蓝色(7),浅绿色(8)
- 第二行:紫色(4),粉红色(5),绿色(6)
- 底排:红色(0),橙色(1),黄色(2),浅绿色(3)
- 数学推理
- 文档和表格理解
- 多语言文本-图像理解
- 常见场景问答
- 视频理解和基于代理的互动
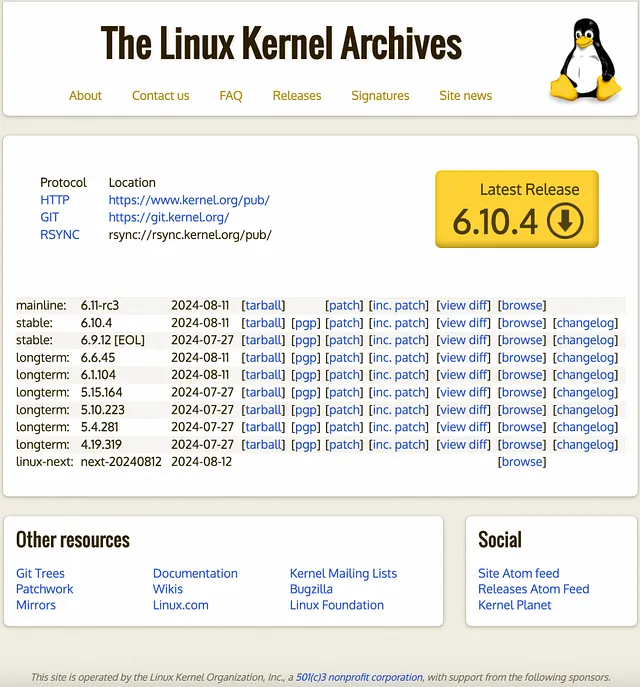
在这些评估中,Qwen2-VL的72B型号始终表现出色,甚至超过了像GPT-4o和Claude 3.5-Sonnet这样的领先闭源模型,特别是在文档理解和多语言文本图像任务方面。7B型号,虽然体积较小,但在图像和视频输入方面表现稳健,使其成为一种经济实惠但功能强大的选择。对于移动部署,2B型号经过优化,可以在视频相关任务和一般场景问答中提供强大的性能,证明了人工智能的卓越性能可以体现在紧凑的形式中。
增强功能:Qwen2-VL有什么新功能?
Qwen2-VL不仅仅是一个增量升级 - 它引入了几个增强功能,推动了人工智能所能做的边界。
- 改进的对象识别: Qwen2-VL 显著增强了识别和理解场景中多个对象之间复杂关系的能力。 这扩展到手写文本,并支持多种语言,使该模型更易于接触和对更广泛的受众有用。
- 视觉推理: 该模型的数学和编码能力显着提升。 它现在可以通过分析图片和通过图表分析解释复杂的数学问题来解决问题。 这使得Qwen2-VL成为实际问题解决和连接抽象概念与具体解决方案之间差距的强大工具。
- 视频理解与实时聊天:Qwen2-VL的功能不仅限于静态图片,还包括视频内容分析。它可以总结视频内容,回答相关问题,并保持实时对话的连续流,提供实时聊天支持,并充当个人助手。
- 可视代理功能:Qwen2-VL 可以作为可视代理,使其能够利用外部工具进行实时数据检索 — 无论是航班状态、天气预报还是包裹跟踪 — 通过解读视觉线索。将视觉解释与功能执行相结合,提高了其效用,使其成为信息管理和决策制定的强大工具。
限制和未来方向
尽管Qwen2-VL是一大进步,但重要的是要承认它的局限性。该模型的知识仅限于2023年6月,仍然在涉及计数、字符识别和3D空间意识的任务上面临困难。此外,它无法从视频中提取音频,这限制了它完全理解多媒体内容的能力。
然而,Qwen团队已经展望未来。预计未来版本将解决这些限制,并进一步扩展模型的能力。目标是构建更强大的视觉语言模型,整合额外的模态,朝着真正全能的人工智能迈进。
Qwen2-VL背后的架构
Qwen2-VL保留了其前身的核心架构,利用了结合了Qwen2语言模型的Vision Transformer(ViT)模型。引入了几个关键升级:
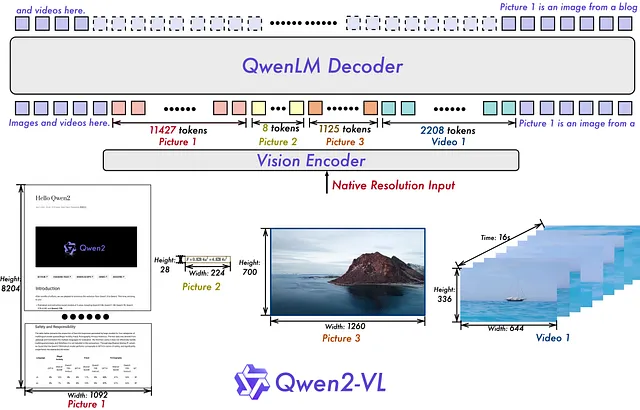
- 天真的动态分辨率支持:与早期模型不同,Qwen2-VL可以处理任何分辨率的图像,将它们映射到动态数量的视觉令牌中。这确保了模型输入和图像中固有信息之间的一致性,紧密模仿了人类视觉感知。
- 多模态旋转位置嵌入(M-ROPE):这一创新技术将原始的旋转嵌入解构为代表时间和空间信息的组件。M-ROPE使模型能够同时捕捉和整合1D文本、2D视觉和3D视频的位置信息,极大地增强了其理解复杂视觉数据的能力。
如何开始使用 Qwen2-VL
对于那些渴望探索Qwen2-VL的人来说,最大的72B型号可以通过阿里巴巴官方的API获得。同时,2B和7B型号已经在Apache 2.0许可证下开源,并可以在Hugging Face和ModelScope等平台上访问。开发人员可以使用提供的代码片段和工具轻松地将Qwen2-VL集成到他们的项目中。
例如,使用API非常简单,并提供详细说明以帮助您开始使用。此外,Qwen2-VL集成了第三方框架,如拥抱面部变换者和vLLM,确保它与您现有的人工智能工作流程无缝衔接。
Qwen2-VL接下来会怎样?
Qwen2-VL 是人工智能领域的一大进步,但这只是个开始。Qwen团队致力于持续改进和创新。在不久的将来,我们可以期待更强大的模型,进一步提升视觉-语言人工智能的能力。
无论您是寻求将尖端人工智能集成到您的应用程序中的开发人员,还是一个寻求利用人工智能获取竞争优势的商业领袖,Qwen2-VL提供了丰富的机会。立即探索它,成为人工智能未来的一部分。
官方介绍:https://qwenlm.github.io/blog/qwen2-vl/
GitHub: https://github.com/QwenLM/Qwen2-VL GitHub: https://github.com/QwenLM/Qwen2-VL
模型下载: https://huggingface.co/collections/Qwen/qwen2-vl-66cee7455501d7126940800d
在线演示:https://huggingface.co/spaces/Qwen/Qwen2-VL
API: https://help.aliyun.com/zh/model-studio/developer-reference/qwen-vl-api API: https://help.aliyun.com/zh/model-studio/developer-reference/qwen-vl-api