使用PandasAI在Google Colab进行对话式数据整理
在数据科学的世界中,数据整理是一个关键步骤。它涉及将原始数据清洁、转换和组织成一个准备好进行分析的格式。传统上,这个过程需要对编程语言如Python或SQL有深入了解,对初学者来说是一项艰巨的任务。然而,如果您可以用简单的英语提问您的数据,并在不编写复杂代码的情况下获得答案,那该怎么办呢?PandasAI就是这么做的,这是一个革命性的Python库,将对话式数据整理带到生活中。
在本指南中,我们将探讨如何在Google Colab中使用PandasAI,这是一个流行的基于云的平台,允许您在交互式环境中编写和执行Python代码。我们将逐步演示如何使用PandasAI的SmartDataframe和Agent类的示例,向您展示这个工具如何简化您的数据整理任务。
为什么PandasAI是数据整理的改变者
无论您是数据科学的新手还是资深分析师,PandasAI都可以通过允许您使用自然语言与数据交互来节省大量时间和精力。这个工具特别适用于:
- 初学者:如果您刚开始学习,PandasAI消除了需要学习复杂语法的障碍,让您可以专注于理解您的数据。
- 中级用户:对于熟悉数据整理概念但尚未精通编程的用户,PandasAI可以帮助弥合这一鸿沟。
- 专家们认为,即使是高级用户,也会发现PandasAI对于快速进行探索性数据分析(EDA)而无需编写重复代码是很有帮助的。
在Google Colab中开始使用PandasAI
步骤1:设置您的Google Colab环境
首先打开Google Colab并创建一个新笔记本。如果你不熟悉Google Colab,它是一个基于云的平台,允许您在交互式环境中运行Python代码,非常适合数据科学任务。
步骤2:安装PandasAI
在使用PandasAI之前,您需要安装它以及任何额外的依赖项。在您的Google Colab笔记本中,运行以下命令:
# Install PandasAI
!pip install pandasai
# (Optional) Install additional dependencies as needed
!pip install pandasai[google-ai, excel, langchain, plotly]
这个命令将安装PandasAI以及可选的依赖项,如谷歌AI、Excel支持、LangChain和用于可视化的Plotly。
第三步:获取BambooLLM API令牌
PandasAI 使用 LLM(大型语言模型) 来理解和解释您的自然语言查询。默认情况下,它使用 BambooLLM。您需要获取一个API令牌来使用这个功能。以下是方法:
- 访问PandaBI并使用您的电子邮件地址注册,或通过您的Google帐户连接。
- 一旦登录,转到您的帐户设置中的API部分。
- 点击“创建新的API密钥”并复制生成的密钥。
- 在您的Colab笔记本中,将API密钥设置为环境变量:
import os
os.environ["PANDASAI_API_KEY"] = "YOUR_API_KEY"
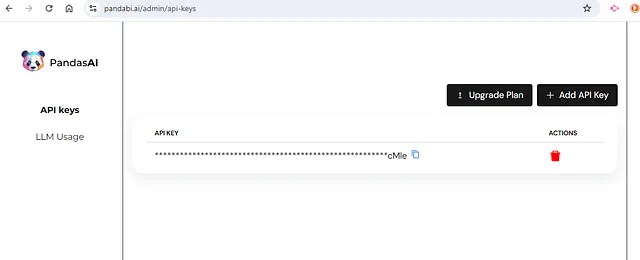
用你复制的实际密钥替换"YOUR_API_KEY"。
使用PandasAI与SmartDataframe
现在我们已经安装了PandasAI并设置了API密钥,让我们来看一个使用SmartDataframe类的示例。
步骤4:创建一个示例数据框
让我们创建一个简单的DataFrame来使用:
import pandas as pd
# Sample DataFrame
sales_by_country = pd.DataFrame({
"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],
"sales": [5000, 3200, 2900, 4100, 2300, 2100, 2500, 2600, 4500, 7000]
})
步骤5: 使用SmartDataframe整理数据
使用PandasAI,您现在可以使用自然语言与这个数据框交互。以下是如何做到的:
from pandasai import SmartDataframe
# Instantiate SmartDataframe with the DataFrame
df = SmartDataframe(sales_by_country)
# Ask a question to the DataFrame
response = df.chat('Which are the top 5 countries by sales?')
print(response)
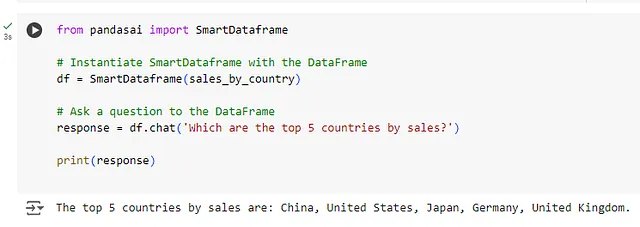
输出:
['China', 'United States', 'Japan', 'Germany', 'Australia']
正如您所见,PandasAI 返回了销售额前5名的国家,而无需您编写任何SQL或Python代码。
用熊猫AI代理拓展视野
在PandasAI中,代理类更强大,允许多回合对话。这意味着你可以问后续问题并保持对话的上下文。
步骤6:创建和使用代理
让我们创建一个更复杂的DataFrame,并使用代理与其互动:
from pandasai import Agent
# Sample DataFrame
sales_data = pd.DataFrame({
"country": ["United States", "United Kingdom", "France", "Germany", "Italy", "Spain", "Canada", "Australia", "Japan", "China"],
"sales": [5000, 3200, 2900, 4100, 2300, 2100, 2500, 2600, 4500, 7000],
"deals_opened": [142, 80, 70, 90, 60, 50, 40, 30, 110, 120],
"deals_closed": [120, 70, 60, 80, 50, 40, 30, 20, 100, 110]
})
# Instantiate an Agent with the DataFrame
agent = Agent(sales_data)
# Ask questions using the Agent
response1 = agent.chat('List the top 5 countries by sales.')
print("Top 5 countries by sales:", response1)
response2 = agent.chat('Which country has the most deals?')
print("Country with the most deals:", response2)
print("Top 5 countries by sales:", response1)
print("Country with the most deals:", response2)
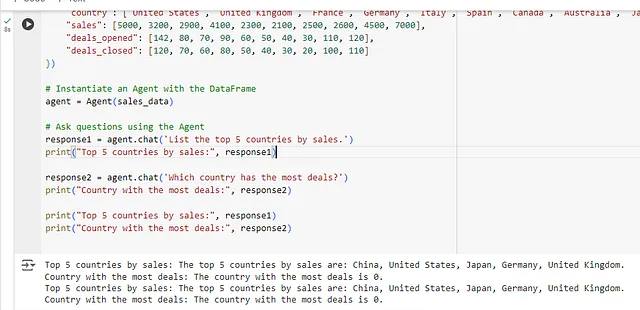
产出:
Top 5 countries by sales: ['China', 'United States', 'Japan', 'Germany', 'Australia']
Country with the most deals: 'United States'
代理人跟踪对话背景,使得可以轻松地提出后续问题,而不必重新表达或重新指定整个查询。
步骤7:处理澄清和解释
代理人如果没有足够的信息来回答查询,也可以提出澄清问题。此外,他们可以为他们的答案提供解释,帮助您理解结果背后的逻辑。
response = agent.chat('What is the GDP of the United States?')
explanation = agent.explain()
print("Answer:", response)
print("Explanation:", explanation)

在这种情况下,如果数据框中没有GDP数据,代理可能会问澄清问题,以帮助您提供更多背景信息或重新定向查询。
结论
PandasAI 是一个强大的工具,将自然语言处理引入数据处理领域。通过将其与Google Colab集成,您可以在基于云的环境中充分利用对话式数据处理的全部功能。无论您是数据科学的新手还是经验丰富的分析师,PandasAI都可以帮助您以更直观和高效的方式与数据进行交互。
准备彻底改变您的数据整理过程吗?立即在Google Colab中开始使用PandasAI,释放出对话式数据科学的潜力。