Sure, here is the text translated into simplified Chinese while keeping the HTML structure:
```html
为您的税务申报构建聊天机器人 — 第2部分:构建本地RAG
```
This HTML snippet translates "A Chatbot for Your Tax Return — Part 2: Build a Local RAG" into simplified Chinese and maintains the structure for web display.
在保留HTML结构的情况下,将以下英文文本翻译为简体中文: **第一部分:为ATO创建爬虫。**
Sure, here's the translation of "Part 2: Building a local chatbot using GPT and LLama3" in simplified Chinese: ```html
第二部分:使用GPT和LLama3构建本地聊天机器人。
```Sure, the translation of "Part 3: Deploying things onto the cloud using Groq and Streamlit Community" into simplified Chinese while keeping the HTML structure would look like this: ```html
第三部分:使用Groq和Streamlit Community将事物部署到云端。
``` This HTML snippet maintains the structure while providing the translated text in simplified Chinese.To translate the given English text into simplified Chinese and keep the HTML structure, you can use the following: ```html 在第一部分中,我们讨论了如何准备输入到您的RAG中所需的数据。 ``` This HTML snippet maintains the structure while providing the translation of "In part 1, we discussed how you can prepare the data needed to be fed into your RAG."
Sure, here's the simplified Chinese translation of "In this part, we are going to focus on:": 在这部分,我们将专注于:
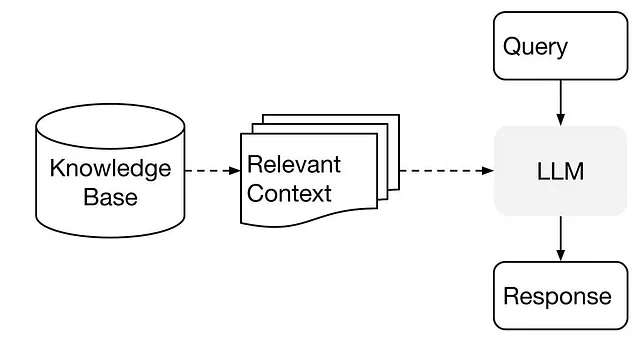
- 在保持HTML结构的情况下,将以下英文文本翻译成简体中文: 将我们抓取的一切内容创建为知识库。我们称之为索引。我们将把索引存储在我们的硬盘上。
- 在我们的LLM中输入知识库。这通过LlamaIndex完成。每次查询时,索引会被探查以获取相关上下文,从而帮助回答用户的问题。 (Note: The translation is provided in simplified Chinese characters.)
- 在保持HTML结构的情况下,将以下英文文本翻译成简体中文: 使用Streamlit创建简单的聊天界面。
在保留HTML结构的情况下,将英文文本"Choosing an LLM"翻译成简体中文: 选择一个LLM
Sure, here's the translation in simplified Chinese, while keeping the HTML structure intact: ```html 这是一个先决条件。为了简单起见,现在让我们从 GPT 开始。 ``` This HTML code will display the translated text correctly with proper formatting.
- 在HTML结构中保持不变,将以下英文文本翻译成简体中文: 去 https://platform.openai.com
- Sure, the translation of "Sign up/ log-in" to simplified Chinese while keeping the HTML structure intact would be: ```html 注册/登录 ``` This HTML code will display "注册/登录" on the webpage, where "注册" means "Sign up" and "登录" means "Log in" in simplified Chinese.
- 在HTML结构中保持不变,将以下英文文本翻译为简体中文: 前往仪表板,然后选择API密钥。
Sure, here's the translation in simplified Chinese while maintaining HTML structure: ```html
4. 创建一个新的密钥并记下来。我们后面会用到它。
```在保持HTML结构的情况下,将英文文本"Building the Knowledge Base"翻译成简体中文可以是: 构建知识库
在保持HTML结构的情况下,将以下英文文本翻译为简体中文: 首先,让我们安装所需的软件包。
pip install llama_index
pip install openai
现在,请创建一个名为 create_index.py 的文件。
from llama_index.core import SimpleDirectoryReader, ServiceContext, VectorStoreIndex
import openai
from llama_index.llms.openai import OpenAI
# Set the OpenAI API key for authentication
openai.api_key = 'your secret key'
def create_and_store_index():
# Create a reader to load documents from a specified directory recursively
reader = SimpleDirectoryReader(input_dir="./taxScrapy/output_files", recursive=True)
# Load the documents from the specified directory
docs = reader.load_data()
# Create a service context for the LLM with specified parameters
service_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-4", temperature=0.5, system_prompt=
"You are an expert on the Australian Tax Laws and your job is to answer questions related to tax. "
"Assume that all questions are related to tax return in Australia in July 2024. "
"Keep your answers technical and based on facts – do not hallucinate features.")
)
# Create an index from the loaded documents using the service context
index = VectorStoreIndex.from_documents(docs, service_context=service_context)
# Persist the created index to the specified directory
index.storage_context.persist(persist_dir="index")
if __name__ == "__main__":
# Call the function to create and store the index
create_and_store_index()
Sure, here's the text translated into simplified Chinese while keeping the HTML structure: ```html 运行创建的文件和索引文件夹如下。这是我们的知识库。 ``` This HTML code maintains the structure while displaying the translated text in simplified Chinese.
To translate "The most important line in the code above is" to simplified Chinese while keeping HTML structure, you can use the following: ```html 以上代码中最重要的一行是: ``` This HTML snippet ensures that the Chinese text is properly identified as simplified Chinese (`zh-CN`) for language purposes.
service_context = ServiceContext.from_defaults(
llm=OpenAI(model="gpt-4", temperature=0.5, system_prompt=
"You are an expert on the Australian Tax Laws and your job is to answer questions related to tax. "
"Assume that all questions are related to tax return in Australia in July 2024. "
"Keep your answers technical and based on facts – do not hallucinate features.")
)
Here is the English text translated into Simplified Chinese, keeping the HTML structure: ```html
这行代码使用默认设置创建了一个 ServiceContext 对象,但为语言模型(LLM)提供了特定的配置。它使用了 OpenAI 的 GPT-4 模型,温度设置为 0.5,用于控制模型响应的随机性。此外,它设置了一个系统提示,指示模型充当澳大利亚税法方面的专家,特别是针对 2024 年 7 月的澳大利亚税务申报问题。
To translate the given English text "If you don’t have an OpenAI subscription, you may still get away with using gpt-3.5-turbo instead." into simplified Chinese while keeping the HTML structure, you can use the following code snippet: ```html 如果您没有OpenAI订阅,您仍然可以使用gpt-3.5-turbo代替。 ``` This HTML code maintains the structure while incorporating the translated text in simplified Chinese.
你可以在 https://platform.openai.com/usage 上监控你的使用情况。
加载索引并创建聊天机器人
To translate the English text "For building the chatbot UI, we’re going to rely on Streamlit." into simplified Chinese while keeping HTML structure, you can use the following: ```html 为了构建聊天机器人界面,我们将依赖于Streamlit。 ``` In this HTML snippet: - `` specifies that the text inside is in simplified Chinese. - "为了构建聊天机器人界面,我们将依赖于Streamlit。" is the translated text. This ensures that the translation is properly marked as Chinese and can be correctly interpreted by web browsers and translation tools.
Sure, here's the translation of the text into simplified Chinese, while keeping the HTML structure intact: ```html Streamlit 在几分钟内将数据脚本转化为可共享的 Web 应用。一切都在纯 Python 中完成,无需前端经验。 ``` In this HTML snippet, the translated text appears in Chinese characters, suitable for display on a web page.
pip install streamlit
import streamlit as st # Import Streamlit library for building web apps
import openai # Import OpenAI library for AI responses
from llama_index.core.chat_engine.types import ChatMode # Import ChatMode enum from llama_index package
# Set OpenAI API key from secret.py
openai.api_key = 'your openai secret key'
# Import necessary components from the llama_index package
from llama_index.core import SimpleDirectoryReader, ServiceContext, VectorStoreIndex, StorageContext, \
load_index_from_storage
# Configure Streamlit page settings
st.set_page_config(page_title="Ask your Tax Questions", page_icon="💰", layout="centered", initial_sidebar_state="auto",
menu_items=None)
# Set title of the app
st.title("Ask your Tax Questions 💬")
# Initialize chat messages history if not already initialized
if "messages" not in st.session_state.keys():
st.session_state.messages = [
{"role": "assistant", "content": "Ask me a question about Tax and Tax Return in Australia. 🇦🇺🦘🦙"},
]
# Function to load data from ATO docs index and cache it
@st.cache_resource(show_spinner=False)
def load_data():
with st.spinner(text="Loading the ATO docs index – hang tight! This will take a few moments."):
storage_context = StorageContext.from_defaults(persist_dir="index")
loaded_index = load_index_from_storage(storage_context)
return loaded_index
# Load data from ATO docs index
index = load_data()
# Initialize chat engine if not already initialized
if "chat_engine" not in st.session_state.keys():
st.session_state.chat_engine = index.as_chat_engine(chat_mode="condense_question", verbose=True)
# Get user input question
if prompt := st.chat_input("your question:"):
st.session_state.messages.append({"role": "user", "content": prompt})
# Display chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
# If the last message is not from the assistant, generate assistant's response
if st.session_state.messages[-1]["role"] != "assistant":
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = st.session_state.chat_engine.chat(prompt)
st.write(response.response)
message = {"role": "assistant", "content": response.response}
st.session_state.messages.append(message)
Sure, here's the translation of the English text into simplified Chinese, keeping the HTML structure: ```html 我们在将索引加载到内存后,这里正在创建一个简单的单页面聊天对话框。 ``` In this HTML snippet, the Chinese text is inserted where the English text was, maintaining the overall structure of the HTML document.
To translate "The most important line in the code is" to simplified Chinese, while keeping HTML structure intact, you can use the following: ```html 代码中最重要的一行是 ``` This HTML snippet ensures that the text "代码中最重要的一行是" is displayed in simplified Chinese, while `` indicates the language of the text for accessibility and semantic purposes.
st.session_state.chat_engine = index.as_chat_engine(chat_mode=ChatMode.CONDENSE_QUESTION, verbose=True)
Sure, here's the translated text in simplified Chinese, keeping the HTML structure: ```html 我们在加载的索引中创建了一个聊天引擎。 ``` This HTML snippet retains the structure and provides the translation of "where we create a chat engine out of the loaded index" into simplified Chinese.
Sure, here's the translation of the phrase into simplified Chinese while keeping the HTML structure intact: ```html 让我们查看文档,了解不同聊天模式的含义。 ```
Sure, the translation of "types.py of llama_index" into simplified Chinese, keeping HTML structure, would be: ```html llama_index 的 types.py ``` In this HTML snippet: - `` is used to enclose the text for styling purposes. - "llama_index 的 types.py" translates the phrase directly into Chinese, maintaining clarity and structure.
class ChatMode(str, Enum):
"""Chat Engine Modes."""
SIMPLE = "simple"
"""Corresponds to `SimpleChatEngine`.
Chat with LLM, without making use of a knowledge base.
"""
CONDENSE_QUESTION = "condense_question"
"""Corresponds to `CondenseQuestionChatEngine`.
First generate a standalone question from conversation context and last message,
then query the query engine for a response.
"""
CONTEXT = "context"
"""Corresponds to `ContextChatEngine`.
First retrieve text from the index using the user's message, then use the context
in the system prompt to generate a response.
"""
CONDENSE_PLUS_CONTEXT = "condense_plus_context"
"""Corresponds to `CondensePlusContextChatEngine`.
First condense a conversation and latest user message to a standalone question.
Then build a context for the standalone question from a retriever,
Then pass the context along with prompt and user message to LLM to generate a response.
"""
REACT = "react"
"""Corresponds to `ReActAgent`.
Use a ReAct agent loop with query engine tools.
"""
OPENAI = "openai"
"""Corresponds to `OpenAIAgent`.
Use an OpenAI function calling agent loop.
NOTE: only works with OpenAI models that support function calling API.
"""
BEST = "best"
"""Select the best chat engine based on the current LLM.
Corresponds to `OpenAIAgent` if using an OpenAI model that supports
function calling API, otherwise, corresponds to `ReActAgent`.
"""
Sure, here is the translation of "Now to run everything, simply type in:" in simplified Chinese while keeping the HTML structure: ```html 现在,要运行所有内容,只需输入: ``` This HTML code ensures the Chinese text is displayed correctly within a web context, preserving the structure for integration into a webpage or document.
streamlit run chatbot.py
Sure, here's the translation in simplified Chinese while keeping the HTML structure intact: ```html 完成了! ```

除了提供的数据外,开始尝试不同的参数,如聊天模式、温度,并检查它们如何影响您回复的质量。
To translate "Replacing GPT with Llama3" into simplified Chinese while keeping the HTML structure, you can use the following: ```html 替换 GPT 为 Llama3 ``` This maintains the original HTML structure around the translated text.

Sure, here's the translation of the text into simplified Chinese, while keeping the HTML structure intact: ```html Llama 是 Meta 推出的另一个 LLM。它是免费且开源的。如果您的硬件满足这些要求,您可以在本地运行 Llama3。 ``` In this HTML snippet: - `` is used to specify that the text inside is in simplified Chinese. - The translated text is directly embedded within the `` tags.
在保持HTML结构的情况下,将英文文本“Step 1: Install Ollama”翻译为简体中文: 步骤1:安装Ollama
To translate the provided English text "Follow the steps here to install Ollama. This is by far the easiest way to get started with Llama3 locally. I’d say the version with 8B parameters would suffice here." into simplified Chinese while maintaining the HTML structure, you can use the following: ```html 跟随这里的步骤安装 Ollama。这绝对是在本地开始使用 Llama3 最简单的方法。我觉得带有 8B 参数的版本在这里就够了。 ``` This HTML structure will preserve the content and format while displaying the translated text in simplified Chinese.
Sure, here's the text translated to simplified Chinese while keeping HTML structure: ```html Step 2: 选择一个向量化模型 ```
在保持HTML结构的前提下,将以下英文文本翻译为简体中文: 创建索引本质上是将您的数据点向量化并存储在某处的行为。有许多有效的向量化输入模型。其中一个最广泛使用的模型是BAAI/bge-base-en-v1.5,我们将在这里使用它。
在保持HTML结构的情况下,将以下英文文本翻译为简体中文: 第三步:重构代码
在保留HTML结构的情况下,将以下英文文本翻译为简体中文: 让我们重构代码。
pip install llama-index-llms-ollama
pip install llama-index-embeddings-huggingface
Sure, the translation of "create_index_for_llama.py" into simplified Chinese while keeping the HTML structure would look like this: ```html create_index_for_llama.py ``` In this format, the text remains as it is but is wrapped in an HTML `` tag, maintaining the original structure of the document while displaying the translated text.
from llama_index.core import SimpleDirectoryReader, VectorStoreIndex, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.ollama import Ollama
def create_and_store_index():
reader = SimpleDirectoryReader(input_dir="taxScrapy/output_files", recursive=True)
docs = reader.load_data()
# bge-base embedding model
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
# ollama
Settings.llm = Ollama(model="llama3", request_timeout=360.0)
index = VectorStoreIndex.from_documents(
docs,
)
index.storage_context.persist(persist_dir="index")
if __name__ == "__main__":
create_and_store_index()
To translate "chatbot_llama.py" to simplified Chinese while keeping HTML structure, you would format it as follows: ```html chatbot_llama.py ``` This HTML snippet ensures that the text "chatbot_llama.py" is marked as simplified Chinese for proper rendering and interpretation by web browsers and other applications that support language specifications.
import streamlit as st # Import Streamlit library for building web apps
from llama_index.core.chat_engine.types import ChatMode # Import ChatMode enum from llama_index
from llama_index.embeddings.huggingface import HuggingFaceEmbedding # Import HuggingFaceEmbedding from llama_index
from llama_index.llms.ollama import Ollama # Import Ollama class from llama_index
from llama_index.core import StorageContext, load_index_from_storage, Settings # Import necessary components
# Configure Streamlit page settings
st.set_page_config(page_title="Ask your Tax Questions", page_icon="💰", layout="centered", initial_sidebar_state="auto",
menu_items=None)
# Set title of the app
st.title("Ask your Tax Questions 💬")
# Set Ollama model and HuggingFace embedding model for tax-related questions
Settings.llm = Ollama(model="llama3", request_timeout=360.0)
Settings.embed_model = HuggingFaceEmbedding(model_name="BAAI/bge-base-en-v1.5")
# Initialize chat messages history if not already initialized
if "messages" not in st.session_state.keys():
st.session_state.messages = [
{"role": "assistant", "content": "Ask me a question about Tax and Tax Return in Australia. 🇦🇺🦘🦙"},
]
# Function to load data from ATO docs index and cache it
@st.cache_resource(show_spinner=False)
def load_data():
with st.spinner(text="Loading the ATO docs index – hang tight! This will take a few moments."):
storage_context = StorageContext.from_defaults(persist_dir="index")
loaded_index = load_index_from_storage(storage_context)
return loaded_index
# Load data from ATO docs index
index = load_data()
# Initialize chat engine if not already initialized
if "chat_engine" not in st.session_state.keys():
st.session_state.chat_engine = index.as_chat_engine(chat_mode=ChatMode.CONDENSE_PLUS_CONTEXT, verbose=True)
# Function to classify user's question as related to tax in Australia
def classify_question(prompt):
classification_prompt = f"Is the following question related to tax or tax returns in Australia? Answer 'yes' or 'no'.\n\nQuestion: {prompt}"
response = st.session_state.chat_engine.chat(classification_prompt)
return "yes" in response.response.lower()
# Get user input question
if prompt := st.chat_input("your question:"):
if classify_question(prompt): # If question is related to tax, process it
st.session_state.messages.append({"role": "user", "content": prompt})
with st.chat_message("assistant"):
with st.spinner("Thinking..."):
response = st.session_state.chat_engine.chat(prompt)
st.write(response.response)
message = {"role": "assistant", "content": response.response}
st.session_state.messages.append(message)
else: # If question is not related to tax, provide guidance
st.session_state.messages.append({"role": "assistant",
"content": "I'm here to answer questions about tax and tax returns in Australia. Please ask a relevant question."})
# Display chat messages
for message in st.session_state.messages:
with st.chat_message(message["role"]):
st.write(message["content"])
Sure, the translation of "What to Do Next?" into simplified Chinese while keeping the HTML structure intact would be: ```html 接下来该做什么? ```
Sure, here is the translation in simplified Chinese while keeping the HTML structure: ```html 现在,我们准备好进入云端了。第三部分涵盖了这部分工作。 ```
Certainly! Here's the text "Code" translated into simplified Chinese, keeping the HTML structure:
```html
代码
```
In this HTML snippet, `` tags are used to maintain the structure and indicate that the enclosed text is computer code or a piece of code.
To translate the text from the GitHub link into simplified Chinese while keeping the HTML structure intact, you can use the following HTML markup: ```html
税务GPT项目
这个项目目的是使用GPT来处理税务相关的问题。
您可以在 GitHub页面 查看更多关于这个项目的信息。
``` In this HTML structure: - `