Sure, here is the translated text in simplified Chinese while keeping the HTML structure: ```html Text to Video AI: 如何免费创建视频 — 完整指南 ```
Sure, here's the translation of the provided English text into simplified Chinese, while maintaining the HTML structure: ```html
文本转视频生成目前已成为趋势,有许多流行的工具可用于此用例,如Vadoo、Invideo、Pictory等。但是大多数这些工具都是付费的,当您需要对输出视频进行多次修订时,预算很快就会超出预期。
``` This HTML snippet contains the translated text in simplified Chinese within a `` (paragraph) tag, suitable for integration into an HTML document while preserving its structural integrity.
To keep the HTML structure intact while translating the text to simplified Chinese, here is the translation: ```html
因此,在本文中,我们将讨论如何使用开源解决方案 https://github.com/SamurAIGPT/Text-To-Video-AI 免费从文本创建视频。如果您更喜欢仅观看使用该项目的演示而不涉及编码方面,这里有一个相同内容的教程视频。
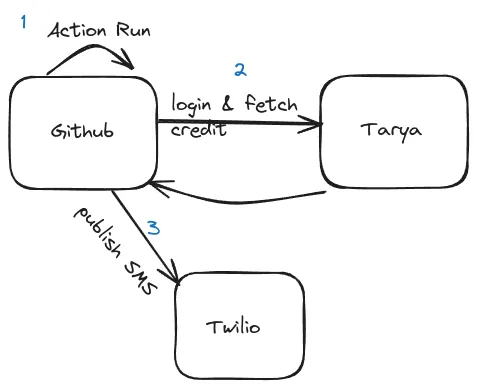
``` This HTML snippet will display the translated text in simplified Chinese while maintaining the structure of the original text.现在让我们来谈谈技术。以下是从文本生成完整视频的整个工作流程。
Sure, here's how you could structure that in HTML:
```html
Workflow
Workflow
```
This HTML structure includes the text "Workflow" in both the `` and `<h1>` tags, ensuring it's properly displayed and accessible.</h1>
- Sure, here's how you would write "Use openai to generate a video script from a topic" in simplified Chinese while keeping the HTML structure intact: ```html 使用OpenAI根据一个主题生成视频脚本 ```
- Sure, here is the translation of the text into simplified Chinese: 使用 Edgetts 选择一个语音,并根据上面生成的脚本创建一个音频。
- Sure, here's the translation in simplified Chinese while maintaining the HTML structure: ```html 使用耳语功能获取上述音频的定时字幕 ```
- 请使用OpenAI API为视频脚本生成视觉关键词。
- To translate "Fetch videos based on the above visual keywords using pexels api" into simplified Chinese while keeping the HTML structure, you can use the following: ```html 获取基于以上视觉关键词的视频,使用 Pexels API ``` This maintains the original HTML formatting while providing the translated text in simplified Chinese.
- 在使用Moviepy将视频、音频和字幕拼接在一起时,请保持HTML结构,将以下英文文本翻译为简体中文。

Sure, here is the translated text in simplified Chinese while keeping the HTML structure intact: ```html 如果你更喜欢选择高级语音,可以尝试使用 Elevenlabs API 而不是 Edgetts。如果你使用硬件规格较低的系统,可以跳过本地使用 Whisper,改用 Whisper API。整个工作流程清晰明了,让我们来理解以上步骤是如何实现的。 ``` This translation maintains the HTML structure for embedding in a web context while providing the simplified Chinese translation of the original English text.
为视频生成脚本
Sure, here's how you can structure the HTML to display the translated text in simplified Chinese: ```html
将使用以下提示生成一个主题的视频脚本。
由于我们专注于生成短视频,我们指示LLM生成约50秒或140字的脚本。
此外,我们指示LLM生成一份有趣且原创的脚本。
``` This HTML structure ensures that the content is displayed correctly with the translated Chinese text.def generate_script(topic):
prompt = (
"""You are a seasoned content writer for a YouTube Shorts channel, specializing in facts videos.
Your facts shorts are concise, each lasting less than 50 seconds (approximately 140 words).
They are incredibly engaging and original. When a user requests a specific type of facts short, you will create it.
For instance, if the user asks for:
Weird facts
You would produce content like this:
Weird facts you don't know:
- Bananas are berries, but strawberries aren't.
- A single cloud can weigh over a million pounds.
- There's a species of jellyfish that is biologically immortal.
- Honey never spoils; archaeologists have found pots of honey in ancient Egyptian tombs that are over 3,000 years old and still edible.
- The shortest war in history was between Britain and Zanzibar on August 27, 1896. Zanzibar surrendered after 38 minutes.
- Octopuses have three hearts and blue blood.
You are now tasked with creating the best short script based on the user's requested type of 'facts'.
Keep it brief, highly interesting, and unique.
Stictly output the script in a JSON format like below, and only provide a parsable JSON object with the key 'script'.
# Output
{"script": "Here is the script ..."}
"""
)
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": prompt},
{"role": "user", "content": topic}
]
)
content = response.choices[0].message.content
script = json.loads(content)["script"]
return script
Sure, here is the translated text in simplified Chinese while keeping the HTML structure: ```html 一旦脚本准备好,我们将其传递给Edgetts以生成相同的语音。然后我们获取生成的音频并传递给Whisper以生成定时字幕。现在字幕已经准备好,我们可以进行下一个任务,即识别视觉关键词,用于获取相关视频以配合字幕。 ``` Please note that the translation is presented as plain text here due to the limitations of HTML rendering in this environment, but you can embed it within your HTML structure as needed.
Sure, here's the translation: 寻找剧本的视觉关键词
Sure, here's the translation in simplified Chinese while keeping the HTML structure: ```html
我们将使用下面的提示来根据输入标题识别相关关键词。我们使用 Pexels API 根据关键词查找视频。这些关键词应该以一到两个词的方式生成,以便于获取视频,并且应该描绘出一些视觉内容,这样可以使在 Pexels 中搜索视频更容易。
```To translate the given English text to simplified Chinese while keeping the HTML structure intact, you can use the following: ```html
首先,我们将输入的字幕分成每3秒钟的时间段。我们这样做是为了保持视频内容的吸引力,每3秒钟就会有一个新视频出现。对于每个时间段,我们使用以下提示生成3个关键词。这样做是为了确保即使我们为一个关键词找不到视频,我们也可以尝试另外生成的3个关键词中的其他关键词。
``` Here is the translation: ``` 首先,我们将输入的字幕分成每3秒钟的时间段。我们这样做是为了保持视频内容的吸引力,每3秒钟就会有一个新视频出现。对于每个时间段,我们使用以下提示生成3个关键词。这样做是为了确保即使我们为一个关键词找不到视频,我们也可以尝试另外生成的3个关键词中的其他关键词。 ``` This translation maintains the structure of the HTML while providing the simplified Chinese translation of the text.prompt = """# Instructions
Given the following video script and timed captions, extract three visually concrete and specific keywords for each time segment that can be used to search for background videos. The keywords should be short and capture the main essence of the sentence. They can be synonyms or related terms. If a caption is vague or general, consider the next timed caption for more context. If a keyword is a single word, try to return a two-word keyword that is visually concrete. If a time frame contains two or more important pieces of information, divide it into shorter time frames with one keyword each. Ensure that the time periods are strictly consecutive and cover the entire length of the video. Each keyword should cover between 2-4 seconds. The output should be in JSON format, like this: [[[t1, t2], ["keyword1", "keyword2", "keyword3"]], [[t2, t3], ["keyword4", "keyword5", "keyword6"]], ...]. Please handle all edge cases, such as overlapping time segments, vague or general captions, and single-word keywords.
For example, if the caption is 'The cheetah is the fastest land animal, capable of running at speeds up to 75 mph', the keywords should include 'cheetah running', 'fastest animal', and '75 mph'. Similarly, for 'The Great Wall of China is one of the most iconic landmarks in the world', the keywords should be 'Great Wall of China', 'iconic landmark', and 'China landmark'.
Important Guidelines:
Use only English in your text queries.
Each search string must depict something visual.
The depictions have to be extremely visually concrete, like rainy street, or cat sleeping.
'emotional moment' <= BAD, because it doesn't depict something visually.
'crying child' <= GOOD, because it depicts something visual.
The list must always contain the most relevant and appropriate query searches.
['Car', 'Car driving', 'Car racing', 'Car parked'] <= BAD, because it's 4 strings.
['Fast car'] <= GOOD, because it's 1 string.
['Un chien', 'une voiture rapide', 'une maison rouge'] <= BAD, because the text query is NOT in English.
"""
Sure, here is the simplified Chinese translation of the provided text: 现在我们已经为每个时间段生成了视觉关键词。接下来我们使用 Pexels API 找到这些关键词的相关视频。以下是从关键词在 Pexels 中获取相关视频的代码。
def search_videos(query_string, orientation_landscape=True):
url = "https://api.pexels.com/videos/search"
headers = {
"Authorization": PEXELS_API_KEY
}
params = {
"query": query_string,
"orientation": "landscape" if orientation_landscape else "portrait",
"per_page": 15
}
response = requests.get(url, headers=headers, params=params)
json_data = response.json()
log_response(LOG_TYPE_PEXEL,query_string,response.json())
return json_data
def getBestVideo(query_string, orientation_landscape=True, used_vids=[]):
vids = search_videos(query_string, orientation_landscape)
videos = vids['videos'] # Extract the videos list from JSON
# Filter and extract videos with width and height as 1920x1080 for landscape or 1080x1920 for portrait
if orientation_landscape:
filtered_videos = [video for video in videos if video['width'] >= 1920 and video['height'] >= 1080 and video['width']/video['height'] == 16/9]
else:
filtered_videos = [video for video in videos if video['width'] >= 1080 and video['height'] >= 1920 and video['height']/video['width'] == 16/9]
# Sort the filtered videos by duration in ascending order
sorted_videos = sorted(filtered_videos, key=lambda x: abs(15-int(x['duration'])))
# Extract the top 3 videos' URLs
for video in sorted_videos:
for video_file in video['video_files']:
if orientation_landscape:
if video_file['width'] == 1920 and video_file['height'] == 1080:
if not (video_file['link'].split('.hd')[0] in used_vids):
return video_file['link']
else:
if video_file['width'] == 1080 and video_file['height'] == 1920:
if not (video_file['link'].split('.hd')[0] in used_vids):
return video_file['link']
print("NO LINKS found for this round of search with query :", query_string)
return None
Certainly! Here's the translated text in simplified Chinese while maintaining the HTML structure: ```html
对于每个时间段的3个关键词,我们尝试使用getBestVideo函数查找视频。如果找不到视频,它将返回None。否则,它会过滤结果,以便我们获得预期的短视频分辨率,即1920x1080,并找到持续时间小于15秒的最长视频。
``` This HTML snippet presents the translated text clearly and maintains the original structure for integration into web pages or documents.To translate "Merge videos, audio and captions with Moviepy" into simplified Chinese while keeping the HTML structure, you can use the following: ```html 合并视频、音频和字幕,使用 Moviepy ``` This HTML structure maintains the integrity of the text while providing the translation in simplified Chinese.
Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html 现在我们已经拥有了所有需要的东西,即音频、字幕和相关的字幕视频。现在我们需要把所有这些元素组合在一起,以获得一个包含所有以上元素的最终视频。为此,我们将使用下面代码中展示的Moviepy库。 ``` Please ensure that your HTML document encoding supports UTF-8 to display Chinese characters correctly.
def download_file(url, filename):
with open(filename, 'wb') as f:
response = requests.get(url)
f.write(response.content)
def search_program(program_name):
try:
search_cmd = "where" if platform.system() == "Windows" else "which"
return subprocess.check_output([search_cmd, program_name]).decode().strip()
except subprocess.CalledProcessError:
return None
def get_program_path(program_name):
program_path = search_program(program_name)
return program_path
def get_output_media(audio_file_path, timed_captions, background_video_data, video_server):
OUTPUT_FILE_NAME = "rendered_video.mp4"
magick_path = get_program_path("magick")
print(magick_path)
if magick_path:
os.environ['IMAGEMAGICK_BINARY'] = magick_path
else:
os.environ['IMAGEMAGICK_BINARY'] = '/usr/bin/convert'
visual_clips = []
for (t1, t2), video_url in background_video_data:
# Download the video file
video_filename = tempfile.NamedTemporaryFile(delete=False).name
download_file(video_url, video_filename)
# Create VideoFileClip from the downloaded file
video_clip = VideoFileClip(video_filename)
video_clip = video_clip.set_start(t1)
video_clip = video_clip.set_end(t2)
visual_clips.append(video_clip)
audio_clips = []
audio_file_clip = AudioFileClip(audio_file_path)
audio_clips.append(audio_file_clip)
for (t1, t2), text in timed_captions:
text_clip = TextClip(txt=text, fontsize=100, color="white", stroke_width=3, stroke_color="black", method="label")
text_clip = text_clip.set_start(t1)
text_clip = text_clip.set_end(t2)
text_clip = text_clip.set_position(["center", 800])
visual_clips.append(text_clip)
video = CompositeVideoClip(visual_clips)
if audio_clips:
audio = CompositeAudioClip(audio_clips)
video.duration = audio.duration
video.audio = audio
video.write_videofile(OUTPUT_FILE_NAME, codec='libx264', audio_codec='aac', fps=25, preset='veryfast')
# Clean up downloaded files
for (t1, t2), video_url in background_video_data:
video_filename = tempfile.NamedTemporaryFile(delete=False).name
os.remove(video_filename)
return OUTPUT_FILE_NAME
Sure, here's the translated text in simplified Chinese: ```html ImageMagick 是必需的,以我们偏好的样式在视频顶部叠加字幕,使用 Moviepy 中的 TextClip 函数。现在我们已经准备好最终输出,并存储在名为 rendered_video.mp4 的文件中。 ```
```html
这里是一个简单易行的Colab笔记本,附带演示视频,如果您不想在系统上手动安装所有内容。
```如果您希望深入了解代码,或者更喜欢在本地运行它,这里是Github仓库的链接