在信息抗体
在碰到你的脚趾头时锻炼了性格
```html
许多我的朋友和同事报告说,他们的企业正试图安装大型语言模型。这是非常令人兴奋的消息。(我们离上一轮人工智能热潮有多远啊!)经济活力是我们最重要的文明承诺,看到这股浪潮把我们的工作场所搅动起来令人振奋。然而,市场已经泡沫化,我认为我们在采用这项技术时将需要一些抗体来构建。特别是,我们(至少是未来的盈利企业)有望学会与企业记录更健康的互动方式。
```Sure, here is the text translated into simplified Chinese while keeping the HTML structure: ```html 我使用信息抗体一词来描述由LLM混乱而产生的学习。我喜欢这个比喻,因为它概括了整个免疫系统激活以对抗感染的过程,这恰恰是应该从对数据操作重新评估中产生的整体性动作。 ```
Sure, here's the translation in simplified Chinese:
```html
2024年的LLM世界
```
```html
我们知道有一个泡沫,也知道原因所在。市面上有很多 GPT 封装公司。其中许多几乎是 YCombinator 的近乎相同的产品,正如我们所知,多亏了与 Sam Altman 的联系,它在很大程度上充当了 OpenAI 的市场调研部门。轻松地用每笔 50 万美元资助许多种子阶段的公司,看看什么奏效,什么不奏效。这是分散式摸索的最佳实践。
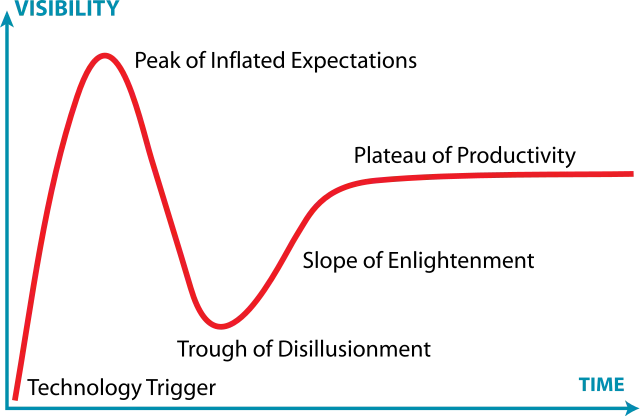
```在采用LLM本身方面,让我们参考一下Gartner的炒作曲线图:
Sure, here's the translation of the provided text into simplified Chinese while keeping the HTML structure: ```html
我们似乎正处在高峰附近。真正的决策者正在降落到失望谷。由于这是一个很大程度上与时间敏感相关的问题,与其纠结于经验性争论,不如牢记心理模型。
```Sure, here's the translated text in simplified Chinese: ```html
在过去一年里,我在工作场所看到的通常是两种情况之一:
```- 在与一家尝试为副本编辑或图像生成等任务增加生成能力的GPT初创公司合作;
- 尝试实现一个在专有商业信息上进行微调的LLM,成为某种形式的神谕。
我认为,第一类是直接的资产升级,将导致很多文案撰稿人和设计师失业。他们将被及时工程师和能够以流程工程思维创建文案和营销资产的人取代。这是正常和良好的创造性破坏,应该没有人会感到惊讶,我们的劳动社会将常规地更喜欢工业流程而不是手工生产。在我(同样受过大学教育)的看法中,文案撰稿人和设计师拥有许多经济上有价值的技能,我们低失业率表明,他们应该能够找到其他谋生方式,即使一开始可能不太舒适。关于这个和富裕社会,我还有几个其他想法,但我岔开了话题。
Sure, here's the translated text in simplified Chinese, while keeping the HTML structure: ```html 第二类是我更感兴趣的。有几个例子说明了LLMs如何被用来试图增强企业: ```
- 在我的旧工作中,我们对工程文档进行了 GPT-4 的优化,以加快工程师在 Slack 上提问的速度;
- 一个朋友的交易公司对与投资组合表现相关的市场新闻进行LLM微调,并将其用于指导他们的销售团队;
- 大型公司正在努力推出在其代码库上接受训练的副驾驶,以帮助工程师进行模式匹配和保持编码风格。
Sure, here's the translated text in simplified Chinese: ```html
我认为所有这些用例都存在明显的问题,并且由于YCombinator/OpenAI(等等)在市场上造成的热潮,这些问题被忽视了。并不是LLMs在产生幻觉,尽管我们似乎已经忘记了这一点。而是语料库本身可能不一致。这样做的结果是LLMs传播了误解。
```Sure, here's the translation of "Messy Data Operations are a Feature, not a Bug" in simplified Chinese: 混乱的数据操作是一种特性,而不是错误。
组织已经非常擅长传播误解,鼓励它们使用神谕将使情况变得更糟。即使你告诉普通员工请检查从聊天机器人得到的结果,他们也不会忘记它建议的内容。行为心理学充斥着研究,表明图像会在受试者的头脑中持续存在,无论听者是否被告知它们可能是误导性的。因此,在最坏的情况下,一个以不一致的专有数据语料库训练的LLM将把一个已经存在的问题 —— 我不知道什么是真的,我需要找出谁知道 —— 变成一个更糟糕的问题,即没有一个人类利益相关者甚至单独负责混淆事实。
```html
好的,为什么不指定这样一个利益相关者呢?让一个人负责在数据进入LLM之前审核语料库,并负责从用户那里获取和解决事实更正票证。简而言之,一个数据管理员。当然,听起来不错,我同意对于紧凑的语料库来说,这可能是一个有效的解决方案。今天许多大型公司都有图书管理员,比如洛克希德·马丁公司,他们可以用来执行某些类型语料库的数据正确性协议。但我认为这只在利益相关者在生成数据或记录时首先对质量负责的情况下才奏效。例如,如果GPT正在接受新闻提要或来自各种供应商的自定义信息流的训练,或者记录必须根据银行或军事承包商的监管协议进行保存。
```大多数企业面临的问题,我敢打赌,是信息的生成和收集方式不应受到规范。在我上一份工作中,作为销售工程师,我听到多少次提议要跟踪客户经理,并审核他们在会议中说过的一切,或者我们应该使用AI记录潜在客户在某次需求发现会议上所提出的所有想法。请原谅我:这些都是创意对话。我们可以做笔记,但头脑风暴不应该被过分认真对待。从销售会议或内部产品讨论等来源获取信息实际上需要批判性和排除性思维。这应该是让机器人远离的明确指标:记住,LLMs是生成AI,而不是“排除性”AI。要求它们做数学证明,你会得到提醒。
```html
个人经验示例:我曾尝试为销售工程师在我之前的雇主处使用的 LLM 进行调整,因为了解客户如何使用产品将是巨大的好处。销售飞轮毕竟是在产品具有社会认可之后启动的。但我们没有关于客户如何使用产品的信息语料库,也不清楚如何引导一个生成信息语料库的过程。这很像加密货币中的预言机问题。我们有一个基于工程文档训练的 LLM,但这对于实际查询使用案例毫无用处,我的销售工程师同行也避免使用它,因为工程师撰写的文档完全误解了实际使用案例,但却没有在任何地方声明这一点。
``````html
所以,实际结果是对企业聊天机器人产生了不信任。这是一种抗体。最终,迅速将人们拉入幻灭的低谷是件好事,所以我建议组织继续尝试他们的数据。但会有一些踩脚趾的情况发生。坐在我旁边的那个人经常抱怨这种新潮的技术,以及我们实际上只需要构建一个已经知道人们想要购买的产品。我相信许多公司出于类似原因已经停滞不前,无法继续他们的LLM动力数据操作。那没关系——如果他们无法适应信息技术的发展,那就是为那些能够的人争取的自由市场份额。创造性破坏,宝贝。
```如何使用信息抗体
Sure, here's the translated text in simplified Chinese within the HTML structure: ```html
然而,如果您是企业家或企业内的变革者,您自然会希望第一次就成功。对于这类事情,我的直觉是将痛点转化为资产。如果您真正使用了LLM项目出错的威胁,您突然就给了人们一个避免不得不做该项目的授权!这就是抗体的美丽所在。
```创业者可以利用混乱的威胁来缩小潜在解决方案的范围,仅限于LLM适用的任务:需要生成力量并且能够吸收无限量人力的任务。我怀疑,在接下来的几年里,我们都将努力培养出对于构建这些解决方案的直觉。
这是我对使用LLM作为诊断工具的粗略建议,抄袭自埃隆·马斯克的自动化战略。
- 在不改变HTML结构的情况下,将以下英文文本翻译为简体中文: 降低要求的愚蠢程度。利用仅仅威胁潜在的LLM混乱来简化数据操作需求。例如:询问LLM是否应该帮助生成销售文稿(令人恐惧!)或者团队是否应该只使用市场部门批准的静态模板。
- 删除部分或流程。利用潜在LLM混淆的威胁作为简化实际必要数据操作的诊断工具。修剪不必要的真相来源,直到决策过程的失败表面积很低。例如:强迫工程团队淘汰糟糕的文档,否则机器人会开始使用它来混淆每个人。
- Sure, here's the simplified Chinese translation of the text while keeping the HTML structure intact: ```html 简化或优化设计。利用LLM混淆的威胁来迫使团队将其流程写下来。例如:如果你不能告诉我从售前到售后如何交接需求的据称复杂的过程,我将使用机器人开始为你进行推理。 ```
- 加快循环时间。利用LLM混淆的威胁来迫使流程加速。例如:如果您的团队不能在十五分钟的专注工作中修改幻灯片,我们将考虑使用机器人来为您完成。
- ```html 最后,自动化。如果过程实际上需要在语料库中进行精细搜索,需要一段时间,并且没有明显的机械程序,那么实际上正在测试人类带宽,而LLM实际上可能是一个有用的生成辅助工具。例如:我不知道从哪里开始向一个对投资组合表现感兴趣的客户解释上周市场事件的情况。LLM可能会帮助激发我的灵感,并且核实事实是很快的。 ```
Sure, here's the translated text in simplified Chinese: 我们产生了大量的信息。它很凌乱,但没关系。让我们试着用同样的关注程度对待机器人,就像我们在职业生活的其他方面一样应该期待的那样。而且,就像我们在职业生活的其他方面疏忽带来的后果会培养抗体和纠正直觉一样,LLM(Large Language Models)可能会出现一些意外,这将教会我们更好地应对信息时代的习惯。