Sure, here's the translation: 幻觉、错误和梦想
在现代人工智能系统产生错误输出的原因以及如何解决这个问题上
Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html 现代人工智能系统,正如我们所警告的那样,容易产生幻觉。 ```
Sure, here's the translated text: ```html
我们知道这一点,但当你思考它时,这有点奇怪。我们有着半个世纪甚至更长时间的计算机不会胡编乱造,它们的复杂性和准确性随着时间的推移只会不断提高。但在2024年,尽管你可以相信口袋计算器给出你输入的数学问题的正确答案,但你却不能相信世界上最复杂的人工智能给出相同问题的答案。
``` This HTML preserves the structure while displaying the text in simplified Chinese.
Sure, the simplified Chinese translation of "What’s with that?" while keeping the HTML structure intact would be: ```html
那是怎么回事?
``````html
我认为这是一个非常重要且多方面的问题,在这篇文章中,我想对其进行一些详细的调查。问题的一个方面涉及到在过去30年左右的时间里,“人工智能”究竟意味着什么发生了重大转变。很长一段时间以来,我们在编程计算机时所做的大部分工作都涉及找到确切解决问题的方法。一个口袋计算器使用这些方法来生成数学问题的解决方案,这些解决方案是可以证明正确的。过去,我们认为自动应用这些精确方法的方式是一种人工智能的形式。但是现在,我们描述为“人工智能”的大多数内容都指的是机器学习的应用。机器学习是一种计算机编程的范例,与像口袋计算器那样应用演绎逻辑以生成已知正确的输出不同,程序被设计为生成预测,预测偶尔会出错。在文章的第一个主要部分中,我将概述这意味着什么,从极高的层面上探讨机器学习与旧的人工智能之间的基本区别,以了解为什么我们期望这些类型的系统会产生错误,而更经典的计算机程序却没有。
```以下是使用简体中文将英文文本保持 HTML 结构进行翻译的结果: ```html
对于幻觉问题的一个简单答案似乎很简单:生成式人工智能是机器学习,机器学习已知会产生错误,而幻觉就是一个错误。这个观点暗示了幻觉问题在未来可能如何发展:从历史上看,随着我们收集更多数据并构建更大的模型,机器学习模型的错误会减少。我们可以期待聊天机器人和其他生成式人工智能系统的准确性会随着时间的推移而提高,方法完全相同。但我不认为这个观点实际上是正确的;在我看来,幻觉在古典机器学习意义上与错误是不同的。我更倾向于一种观点,认为所有生成式人工智能输出都是一种幻觉。我将在第二节中详细解释我所说的一切。
``````html
无论如何,无论您如何定义幻觉以及您对其性质的信仰是什么,每个人都同意存在一些良好且有用的生成式人工智能输出,以及其他一些不好且无用的输出,并且自然而然地希望量化每种输出的数量。事实上,我认为量化这一点至关重要,以便以任何有用的方式将这些事物投入生产。但事实证明,测量这种类型的内容是非常困难的,越来越多的人开始了解这一点。在第三个主要部分中,我将解释为什么我认为这种测量非常重要,以及使其如此困难的原因。
```Sure, here is the translation:
```html
机器学习速成课程
```
Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html
在所有这些生成性内容出现之前的旧日子里,大多数人工智能关注的问题是对狭窄类别的结果进行非常具体的猜测。这个用户会点击这个链接吗?这张图片中描绘的是什么对象?这只股票明天会值多少钱?每个问题都将由一个离散的计算机程序回答,它的唯一任务就是回答它被设计来回答的问题。
``` Feel free to use this HTML structure with the translated text.在HTML结构中,将以下英文文本翻译成简体中文: 我们如何构建一个计算机程序来解决这些问题之一?在很久以前,方法是尝试从第一原理推理。要预测苹果从树上掉下来后击中地面需要多长时间,牛顿只是非常努力地思考宇宙的本质,并提出了一个产生回答这个问题的方程的理论。这种方法对牛顿来说很成功,但对于大多数实际问题来说,很难以这种方式从第一原理得出解决方案。许多人都尝试过,这就是我们最终得到像布莱克-舒尔斯方程这样的东西来估计金融衍生品的真实价值,但对于我们在现代世界关心的许多问题,比如猜测图像中所描绘的物体,我们甚至不知道从何处开始。
Sure, here is the translation of the provided text into simplified Chinese while keeping the HTML structure: ```html
进入机器学习。机器学习的基本思想是通过观察足够多的你尝试预测的过程的示例,你可以找到模式,这些模式将帮助你进行准确的预测,而不一定需要理解生成这些示例的过程。通过观察一百万棵不同高度的树上掉落的一百万个苹果,你可以跳过《自然哲学的数学原理》直接得到方程式。
``` This HTML code contains the translated text in simplified Chinese within a `` (paragraph) element, maintaining the original structure.
```html
或者,你可以直接切入到一个方程式。由于这个过程的本质,你找到的方程式很可能不会与牛顿的相匹配。它会生成一个尽可能接近数据的方程式,但在可以近似任何给定数据集的无数方程式中,不太可能选中牛顿的确切方程式。但没关系。重点是你不需要它。你不是在尝试理解引力;你是在试图对苹果做出预测。对于像物理学这样的问题来说,这可能不是理想的情况,但对于像识别图像中的物体这样的问题,其中没有明显的第一原理,这非常方便。
``````html
构建这样一个系统的基本流程被称为监督学习,如果你把视角放得足够远,抽象掉大部分细节,它就非常简单。要构建一个能猜测图像中手写数字的系统,你需要收集一个大数据集,其中包含数字图像,并手动为每个图像标记数字。这被称为训练数据。然后,你将训练数据中的所有图像展示给计算机,并让它猜测每张图片中的数字,并根据它猜对的频率给出一个评分。你要重复这个过程几十万次,计算机每次都会尝试不同的猜测策略,寻找能给出最高评分的策略。寻找最高评分的猜测策略可能会非常耗时且计算成本高,但是最近在寻找高分数的数学和计算效率方面的创新,使得这种基本策略在广泛的任务中极其成功。
``````html
为了在这里介绍更多的命名约定,寻找最佳猜测策略的过程被称为“训练”,而产生的系统通常被称为“模型”。从一组离散标签中猜测的模型被称为“分类器”,而机器学习实践者更倾向于称这些猜测为“预测”。
```这值得花点时间思考一下机器学习方法与牛顿的方法有多大不同。牛顿可能会看几个苹果从树上掉下来以获得灵感,但他的项目是发展一种理论,编码天体运动的一般原则。一个方程式从理论中弹出,告诉我们,除了许多其他事情之外,苹果从树上掉下来需要多长时间。对于机器学习者来说,主导天体之间关系的一般原则几乎没有相关性。机器学习者唯一关注的是准确地重现一个包含一百万个苹果掉落时间的数据集。每种方法都有优缺点。机器学习方法可能会产生一个难以理解的方程式,对引力的一般性质了解甚微,但另一方面,它可能更能够包含现实世界的复杂性,比如空气阻力,这会让牛顿的方法变得更加复杂。
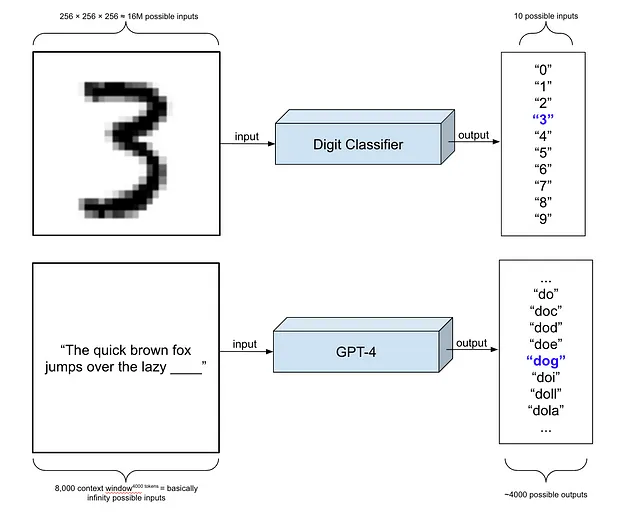
我将机器学习比作牛顿的方法只是为了突显出监督式机器学习并不是构建人工智能系统的唯一途径。编程计算机的方式有很多种,且事先没有一种方式明显或必然比其他方式更好,适用于任何特定的应用。但是,在过去的15年左右,人们开始逐渐认识到监督学习可以在比任何人预期的都要复杂得多的任务上发挥作用。这里的复杂性指的是模型可能的输入和输出的多样性。一个典型的入门机器学习教程可能会向您展示如何构建一个系统,该系统接收一个256×256像素的手写数字图像,并产生十种可能的标签之一——从0到9的数字。您可以构建这样的模型,只需几万张图像就可以达到相当高的准确性。但是,如果您能够使用数百万或数十亿张图像而不是一千张带标签的图像,您可以极大地扩展可能的输入和输出的范围。例如,像 Stable Diffusion 这样的图像扩散模型是在各种各样的图像上进行训练的,而这些图像的大小各不相同,它们不是输出少数几个离散标签中的一个,而是输出一个完整的图像。也就是说,它们不是将256×256=65,536个可能的输入映射到十个可能的输出,而是将一个不可思议地庞大的可能输入集映射到一个不可思议地庞大的可能输出集。利用机器学习做到这么复杂的事情并不明显,我想说这是过去15年来的一项重大科学发现之一。
Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html
问题在于,要构建这种更复杂的模型,你需要大量的数据,获取足够大的数据集很快就变得价格昂贵。在这些高复杂性任务中最有潜力的模型需要数十亿个或更多的标记示例,而没有办法手动查看十亿张图像并记录它们所描绘的对象。
``````html 如果你能够在不必手动查看所有示例的情况下生成标签,那么你就有机会了。这就是自监督学习的重要思想,是现代生成式人工智能系统背后的机器学习范式。如果你能获取到数十亿句子——比如通过从互联网上获取所有文本——你可以通过将句子切分成片段来自动构建训练数据集。只需将“快速棕色狐狸跳过懒狗”变成训练示例“快速棕色狐狸跳过懒___”,并将其标记为“狗”。事实上,你可以通过在不同的位置切断它来构建许多训练示例,仅从这一个句子就可以得到八个训练示例:“快速”和“棕色”,“快速棕色”和“狐狸”,等等。仅从这一个句子我们就得到了八个训练示例,无需人工标注。将这个乘以可能从互联网上获取的句子数量,你就可以接近训练这些复杂模型所需的数据规模。 ```
以下是一个重要的观察,我稍后会回到这个问题,就是,尽管在大小和复杂性上有着巨大的差异,但训练GPT和训练传统分类器的过程并没有那么不同。LLM处理了更多可能的输入和输出,但它的训练方式基本相同,都是为了做同样的事情:猜测给定输入的正确标签。
Sure, here's the translated text in simplified Chinese, keeping the HTML structure: ```html
这两个模型都是通过展示一堆不完整的例子,让它们猜测完整的部分,并对它们的猜测进行评分来构建的。与训练现代生成式人工智能系统相关的重大创新在于找到自动构建大规模训练数据集的巧妙方法,以及发明适合执行复杂任务的新型黑匣子,但它们训练的基本高层次图像基本上与几十年来的情况相同。
``` This HTML code preserves the structure of the text while providing the translation.Sure, here is the translated text in simplified Chinese while keeping the HTML structure intact: ```html
故事可能就到这里结束了。有时,数字识别器会将7称为9,有时,语言模型会说快速的棕色狐狸跳过懒惰的棕色沉闷。这只是机器学习的固有部分,这是机器学习模型基于模式而不是可证明正确的演绎推理进行预测的结果,这是随着更多数据和更大的模型而越来越好的东西。
```Sure, here's the translated text in simplified Chinese, keeping the HTML structure intact: ```html 但我不认为这是正确的。 ```
Sure, here's the translation in simplified Chinese: 2. 幻觉和错误的区别
Sure, here's the translated text in simplified Chinese: 有时候你给模型看一个数字7的图片,它却说这是数字9的图片。这种情况一直存在。当这种情况不可避免地发生时,为什么我们不说数字识别器在“幻觉”呢?为什么只有来自聊天机器人的不准确信息被称为幻觉呢?
```html
正如我刚才提到的,从概念上讲,LLM和经典分类器在构造方式上非常相似。LLM是一个分类器,尽管是一个非常复杂的分类器。就像数字识别器被训练来填补预先存在图像上缺失的标签一样,LLM被训练来填补预先存在句子末尾的缺失词。这里的主要区别在于复杂性和规模。但是虽然它们在构造方式上相似,但在生成式AI系统部署方式上存在着巨大的差异。
``````html
通常情况下,我们会部署一个分类器来执行它训练过的相同任务。当我们部署数字识别器时,我们将让它开始识别数字。我们可能会有一些流程,通过这个流程手写数字被收集起来,然后我们将使用模型来读取这些收集的数字,以便做类似存款支票之类的事情。
``````html
生成式人工智能系统不同。当我们将LLM部署为全球使用的聊天机器人时,我们从在预先存在的句子中猜测下一个单词的用法转换为“猜测”下一个实际不存在的全新字符串中的单词。这是一个巨大的转变,我相信其重要性通常被低估了。这意味着,与传统的分类器不同,没有办法以传统的方式评估LLM输出的准确性,因为没有正确的标签可以进行比较。我认为这一点有点微妙,而且相当详细的说明将有助于揭示这一点。
``````html 当您将数字7的图像输入到数字识别器中时,您希望它输出的是一个单一且明确的正确标签:“7”。如果它输出标签“1”或“9”,那就是明显错误的,并且会影响您模型的准确性。这些错误与训练过程中发生的错误类型相同,因此讨论新数据上的错误率(所谓的“泛化误差”或“样本外误差”)与我们讨论训练数据上的错误率的方式完全相同。 ```
```html
当您向ChatGPT输入字符串“What is 2 + 2?”时,没有一个单一的明确的正确的下一个词。您希望下一个词是“4”之类的东西。但是“2”也可以,就像“2 + 2 = 4”那样。“The”也可以是一个好的下一个词,就像“2和2的总和是4”一样。当然,这些中的任何一个也可能是一个糟糕回应的第一个词,比如“4.5”或“2 + 2 = 5”或“快速的棕色狐狸”。模型构建的任务是填补来自现有段落的被审查的词,这是一个有明确正确答案的任务,但现在情况完全不同。有更好的下一个词和更糟糕的下一个词,但是在训练中那样的明确的正确的下一个词不存在,因为没有重建的示例。
```Sure, here's the translated text in simplified Chinese: ```html 在语言模型的经典意义上,错误指的是无法复现训练示例中被审查的缺失单词,但在实际应用中,这些模型根本不用来做这件事。这有点像我们开始将动物的图片插入到数字识别器中。如果数字识别器将狮子称为6,它算是犯了错误吗?不,我不这么认为。你是在使用它进行不同于训练任务的任务;没有正确答案,因此错误也就没有明确定义。 ```
在实践中,我们通常并不太关心这些单个词语的预测。LLM,即使 ChatGPT 的引擎,只是一个接一个地猜测单词,但 ChatGPT 系统包括一个组件,将这些预测反馈到 LLM 中,以生成一整个词序列,构成一个完整的文本响应。我们通常感兴趣的是在完整文本响应中出现的语义内容,而不是任何一个单词。
这至少部分解释了为什么手写数字分类器将数字7误识别为9是一个“错误”,但当GPT-4声称1981年一只名叫卡米的大象游过英吉利海峡筹集世界野生动物基金会的资金时,则是一种“幻觉”。

```html
当然,1981年一只名叫卡米的大象横渡英吉利海峡并不是事实,但 ChatGPT 在这里出错的方式与图像分类器将 7 误认为 9 时的方式大不相同。ChatGPT 在这里做出了 110 个不同的预测,很难明确将每一个归类为正确还是错误。每个预测的词都与其之前的词相关,这看起来非常像训练数据中可能找到的一系列词。
```
```html 一些,甚至大多数,在我看来,这里预测的词语可能更接近正确而不是错误。当然,由于没有预先存在的文本可供比较(这在我这里算是整个论文的重点),所以没有普遍的客观定义方式,但你能想到比“在动物历史上仍然是独一无二的事件”更好的词吗?模型做出的所有预测中,很不清楚哪些是单个的错误,如果有的话,我们应该称之为错误 — 尽管总体上,显然,这个输出不是我们想要的。 ```
```html
为什么它不是我们想要的呢?它到底有什么问题?显然,主要问题在于它似乎描述了一个实际上并未发生的事件。但是当我真正思考这个问题时,我觉得有点困惑。如果一只名叫卡米的亚洲象确实在1981年穿越了英吉利海峡,就像这段文字描述的那样,那么这个完全一样的输入和输出对就不会是幻觉。这似乎暗示着输入输出对的文字本身并没有使其成为幻觉的东西;它是否是幻觉完全取决于世界的事实,这些事实与模型生成的文字完全独立存在。但是如果文字本身没有使其成为幻觉的东西,那么幻觉性是否甚至是文字的一个属性呢?似乎并不完全是。这是文字与现实世界中的对象和事件相关的方式的属性。
``````html
更加复杂的是,将文本映射到世界事实比人们预期的更加难以捉摸和更加主观。
我阅读关于卡米的段落时,发现其中提出了几个主张,其中许多是真实的——海峡在其最狭窄的地方约为“21英里”,“由于强劲的洋流和寒冷的水温,即使对于经验丰富的人类游泳者来说也是一项巨大的挑战”。
我相信大多数读者会同意文本所提出的主要观点是一只名为卡米的大象横渡了英吉利海峡,这是错误的,因此也许这段文字是“幻觉”,但你能否提出一个客观的标准来评估所有可能的文本?对我来说似乎很困难。
以下输出是否会是一种幻觉?(始终牢记,由于这些系统是随机生成文本的,相同的提示可能会导致不同的输出,其中一些您可能会认为是幻觉,而另一些您可能不会认为是幻觉。)
```
Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html
这个怎么样?
```
Sure, here's the translated text in simplified Chinese: 我不是说不能想出一些标准来明确地对这些进行分类,但这并不像你希望的那样直截了当。
```html
让我再次概括一下ChatGPT的基本原理。首先,你训练一个分类器,以更或少标准的方式,在填补文本块中缺失单词的任务上进行训练。现在你有一个模型,可以逐字生成一个单词:给定先前文本,生成预测的缺失单词。给定一些初始文本,比如“2 + 2”,这个模型会表现得好像这是一个已经存在的文档的开头,最后一个词被审查了,并猜测被审查的词是什么。也许它猜测“等于”。现在,要将这个系统转变为一个可以一次生成多个单词的系统,你将这个单词粘贴到提示的末尾,并将其反馈到模型中。模型再次被调用,重新启动,对任何先前活动一无所知,并被要求猜测已从“2 + 2等于”末尾删除的单词。这一过程一遍又一遍地重复,直到模型的预测是没有下一个单词了。在高层次上,生成图像模型的工作原理非常类似。它们是在重建图像的任务上进行训练的,给定图像的扭曲版本和图像的纯文本描述。要生成新图像,你输入你想要生成的内容的纯文本描述,在模型期望的扭曲图像位置,输入随机噪声。在这两种情况下,模型“认为”它正在重建一个现有的工件,但实际上它正在生成一个新的工件。考虑到这个描述,我想知道是否所有生成的AI输出都是“幻觉”?如果让它们产生输出的方法是告诉它们输出实际上已经存在,并让它们开始重建它,那对我来说,这听起来像是在要求它们产生幻觉。
``````html
一些知名的人工智能研究人员最近公开表示认同这一观点,即所有大型语言模型的输出都是幻觉——而且,这实际上是件好事。Andrej Karpathy 最近在推特上表示,LLM(大型语言模型)是“梦想机器”,“幻觉不是bug,而是LLM的最大特点。”我可能不会如此远地描述这是一个“伟大”的特点,但我确实相信这是它们的最显著特征。
```Sure, here's the translated text in simplified Chinese: ```html 这实际上并不是一个新颖的观点,而是一个相对较旧的观点。在2015年,谷歌发布了一个他们称为DeepDream的系统,这个系统非常直接地是当前这些生成式AI系统的前身,几乎可以确定Karpathy所指称的LLMs“梦想机器”就是指的这个。 ```

以下系统的诞生是因为他们意识到他们可以重新配置他们一直在使用的技术,将图像分类的方法用于生成以前不存在的图像。由于生成的图像实际上并不是现实世界中存在的任何东西,而是类似于训练数据中图像的统计回声,他们决定将其称为“梦”。DeepDream的创建者并未声称该模型产生的图像是“偶尔的幻觉”。从一开始就清楚,这些模型生成的每一点信息都是“梦”。当时,这似乎更像是一种好奇心,而不是一种实际上可以自成一体的东西,或者最好的情况下,一种更好地理解分类器内部工作原理的方法。

```html
当时似乎很多人没有预料到这种类型的梦想本身可能会有用,但我们后来得知,如果你用足够复杂的模型和足够的数据来训练,这些梦想可以变得非常生动,并且经常对应于真实世界的事实。但在我看来,到这种程度发生时,这基本上是一个幸运的巧合。“从模型的角度来看”,幻觉文字和非幻觉文字之间没有区别。它的所有输出都是虚构的假想被审查文件的重建。
``````html
这可能感觉有些哲学和抽象,而且在某种程度上确实如此,但我相信它也对我们可以期待这项技术如何发展具有一些非常具体的影响。如果幻觉类似于任何其他机器学习模型的典型错误,那么我们有相当好的经验理由相信,幻觉的普遍性可以被积极地驱使向零靠拢。现在有一些机器学习模型在手写数字识别方面非常非常出色。基本步骤很简单:用更多的数据训练模型,并使模型更大。但是,如果幻觉在质上与经典类型的错误有所不同,就像我真的相信的那样,那么情况可能会有所不同。在这种情况下,更多的数据或更大的模型并不那么明显会导致幻觉减少。也许前进的方式不是更多的数据或更大的模型,而是其他的东西:也许是完全新的和不同的训练模型的方式,或者是一种新的预测生成方式。事实上,目前处理幻觉的最新技术方法并不真正涉及收集一个具有意义的更大数据集或使模型更大;RLHF 更像是一种完全新的和不同的改变预训练模型的方式(我在这篇以前的帖子中详细展开了 RLHF,在这篇和这篇中稍微不那么详细,但从不同的角度来看)。这是解决方案吗?也许;没有人知道!从幻觉问题是质上新的观点来看,而不是机器学习模型偶尔会产生错误的众所周知的问题的一个例子,沿着这个轴线逐渐但永久地改进的必然性根本不是保证的。
``````html
这种观点所暗示的真正可怕之处在于幻觉问题根本无法解决。幻觉和非幻觉实际上并不是完全不同的输出类别;每次你要求机器人为你画一幅图或写一篇文章时,你都在要求它产生幻觉。这些幻觉必然会有时与现实世界产生分歧,因为,嗯,它们怎么可能不会呢?它们就是梦。我认为值得注意的是,大多数试图将基于LLM的系统与真相联系起来的实际尝试实际上并不是改进模型的方法,而是将非LLM部件连接到更大系统中的方法,这些部件能够生成更可靠的事实性文本供其反弹:例如,为其提供执行代码的环境,或者提供来自必应的搜索结果。这些附加组件(OpenAI字面上称它们为附加组件)在引发更贴近真实世界的幻觉方面可能有些成功,但在我看来,它并没有解决问题的根源,即生成的引擎无法区分生成真相和生成谎言。
``````html
作为一个简短的旁白,我觉得围绕生成式人工智能的炒作相当令人困惑和混乱。当然,在很多方面我觉得它被夸大了。你知道这一点;我不需要展开。但另一方面,我觉得人们实际上没有充分赏识,也没有充分推销,这样一个奇迹,即使这一切是如何运作的。
对我来说,并不奇怪,如果给定一个足够大的数据集和一个足够大的模型,你可以训练一个大模型来预测文本段落中缺失的单词,而且准确率相当高。但事实上,你可以将该模型的输出再次反馈到自身以生成文本,而生成的文本甚至在逻辑上是连贯的,更不用说有用了,这简直是奇迹。然而,我真的没有看到这个最后一点被强调得很多。我只是在这里胡言乱语,但我认为(一些)构建这项技术的人并不想真正承认这种运作方式有多么令人惊讶,因为这引发了一个令人不舒服的问题,即是否需要类似规模的奇迹来改进它——例如消除幻觉问题。将 GPT-4 描绘为通往人工超级智能的不可阻挡的行军中的一个简短停留,其中幻觉和所有其他问题都只是沿途的临时问题,比将其描述为 2017 年有人发现的一个奇怪技巧更令人舒适,这个技巧产生了完全不可预测和令人惊讶的结果,没有人真正理解。
```Sure, here's the translated text in simplified Chinese, while maintaining the HTML structure: ```html
3. 关于不良输出的风险
```在前一节的观点中,幻觉性输出和非幻觉性输出之间没有真正的普遍区别。可能有更理想的输出和不太理想的输出,但理想性并不是文本的固有属性,而是读者解释和使用的属性。你可能同意这一点,也可能不同意。无论如何,我认为思考并尝试量化模型在不同情况下产生的不同类型文本的频率是重要的,甚至是至关重要的。
这表明了一个相当简单的想法:为什么我们不仅仅通过一纸令来定义幻觉的标准——而不管哲学上对于这样一种事物是否客观存在的担忧——并试图以这样的定义来衡量模型,以得出一个“幻觉率”。在本节中,我将讨论我们在尝试这样做时遇到的一些挑战。
首先,关于如何思考错误问题,有一些要说的。学习不同 AI 系统的具体技术细节是有趣的,但当你考虑部署一个来自动化真实决策并涉及真实利益的系统时,只有三件事情真正重要:它会产生哪些类型的错误,它们发生的频率如何,以及这些错误会造成什么样的代价?这些问题的答案决定了是否甚至有理由在生产中使用该系统,有时候甚至不合理!
```html
假设您考虑使用一个预测房屋是否定价不足的模型作为房地产投资业务的基础。如果模型预测房屋被低估,那么您将购买它,并按照您的模型所说的公平市场价出售。这种策略是否可行在很大程度上取决于您的模型所犯的错误类型和频率。知道“模型在实际销售价格上误差不超过5%的情况占90%的时间”是不够的。您需要了解更多信息。在误差超过5%的10%情况下,误差有多大?如果它偶尔误差达到100%或1000%,那可能足以使您破产,即使这种情况很少见。在误差在10%以内的90%情况下,模型倾向于高估还是低估?如果模型倾向于低估房屋的真实价值,那么您将经常错过有利可图的翻转机会,或者卖得太早。这可能很烦人,但只要有时候它做得对,您可能有一种可行的赚钱方式。另一方面,如果模型倾向于高估房屋的正确价值,那么您将为过高估价的资产付出过多,这是破产的好方法。故事的寓意在于,了解和规划模型所犯的错误——不仅是它们发生的频率,而且是它们的样子以及它们的成本有多大——对于您是否要使用它来自动化决策至关重要。这对于从最低级的单变量线性回归到世界上最大的大语言模型的每个模型都是如此。
``````html
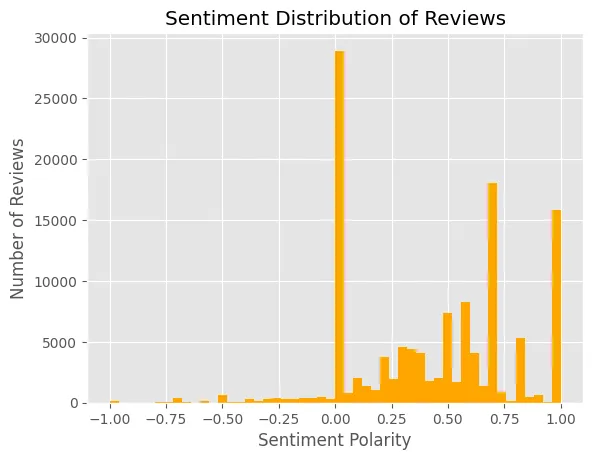
对于生成式人工智能而言,正如我所讨论的那样,甚至如何定义或描述错误都不是很清楚,更不用说衡量和推理它们了。有人尝试过。正如我之前所建议的,您可以尝试让LLM系统生成一堆输出,然后阅读它以确定它是对还是错,并从中计算“幻觉率”。一家名为Vectara的公司有一个尝试做到这一点的程序,并维护着一个“幻觉排行榜”,目前报告说GPT 4 Turbo的幻觉率为2.5%,而Mistral 7B Instruct-v0.1的幻觉率为9.4%。
```Sure, here's the translated text: ```html
我对这些数字是如何估算的有一些强烈的方法论担忧,我会很快回到这些问题,但是即使假设有一种方法论上正确的方法来量化这一点,这样一个“幻觉率”并不是足够的信息。就像在购房的例子中一样,重要的不仅是它出错的频率,而且是朝哪个方向出错?当LLM机器人说错话时,它到底在说什么?它是说上个周末是雨天,而实际上是晴天吗?还是它在给你的客户提出不可能实现的奢侈要约?如果它在上个周末的天气预报中错误的概率为2.5%,那对于一个面向客户的聊天助手来说可能已经足够了,但你可能希望它免费赠送库存的频率不要超过2.5%。
``````html
在经典的机器学习背景下,通常可以对不同类型的错误及其速率设定一些界限,或者至少就它们进行一些定性描述。你不知道房价估算会偏离多远,但你知道它至少会是一个数字,而且你可能可以进行一些统计分析,以弄清它是倾向于高估还是低估等情况。你不知道数字识别器会认为这个“7”是什么,但你肯定它至少会猜一个数字。对于这些新的生成式人工智能系统来说,输出可能是任何东西。可能的不良文本空间是难以想象的巨大。ChatGPT 可能会向您的客户错误引述价格,或者推荐竞争对手,或者称他们为种族歧视性词语,或者生成色情图片,或者以任意无数种其他方式搞砸,并且每种类型的不良输出都有不同的成本。如果不更具体地了解它产生哪些错误,通用的幻觉率根本无法为您提供足够的信息,以判断 LLM 是否适合您。
``````html
我想回到方法论挑战,因为我认为它们是严重的。我至少看到三个难点。第一个,也是最不严重的,显然是关于什么构成“幻觉”没有广泛的共识。Vectara排行榜对于他们对幻觉的定义实际上并不是很精确,但它似乎大致是这样的:幻觉是对一段文字进行准确总结的失败尝试。就这一点而言是可以的,但是如果您没有使用模型来总结文字,那么模型多次失败于准确总结文字的程度可能对您并不特别有帮助。这是一个问题,但并不是一个非常严重的问题,只要您仔细了解您正在查看的任何幻觉基准的方法论。您只需阅读文档,决定您个人对幻觉的定义是否与基准的定义相匹配,并相应地进行。
```第二个和第三个问题要处理起来要困难得多。第二个问题是几乎不可能正确执行这些评估。要正确评估Vectara的幻觉率(我很抱歉一直挑Vectara的毛病,因为所有的基准测试都有这个相同的问题),需要仔细阅读数万段长段落的文本摘要,并确定每一段是否包含任何事实错误。这是不可能在持续进行中做到的。他们所做的是,一旦他们生成了所有的文本摘要,他们使用另一个大型语言模型来确定摘要是否包含错误。我希望你能看到这个问题。

以下是使用简体中文将英文文本保留HTML结构的翻译:
以下是一些[幻觉]测试的基本特性。这些测试旨在区分带有[幻觉]的[LLM输出]和没有的[LLM输出]。讨论了使此过程成为测试的最低标准。审查了评判测试质量的各种方法。测试的常见用途是估计[幻觉]的流行率;结果呈阳性的测试频率被证明是一个糟糕的估计,给出了必要的调整。
Sure, here's the translated text in simplified Chinese: ```html — 由我轻微编辑并加注的Rogan, W. J., & Gladen, B. (1978)的论文《通过筛选测试结果估计患病率》摘要。 ```
Sure, here is the translated text in simplified Chinese, keeping the HTML structure intact: ```html
尽管我相信在描述LLM输出时使用不可靠的估算器存在一些潜在的前进方式,但我没有看到它们被纳入任何广泛可用的基准测试中。目前我不认为它们是可信的。
``````html
第一和第二个问题有些无关紧要,因为第三个问题是致命的。它来自统计学101。我们假设一个模型具有某种客观的“幻觉率”,即模型产生幻觉的平均速率,并尝试通过检查在其输出样本中幻觉发生的频率来估计该率。但总的来说,为了使该策略有效,我们需要样本能够代表整个人口;也就是说,我们需要文本看起来像是从所有可能的文本中随机抽取一个段落所得到的文本。但这些基准数据集,姑且这样说,看起来并不像那样。它们通常是通过非常人为的手段构建的,并且总的来说,与您随机从ChatGPT用户那里抽样一个随机提示所遇到的典型文本差别很大。
```Sure, here's the translated text in simplified Chinese within the HTML structure: ```html
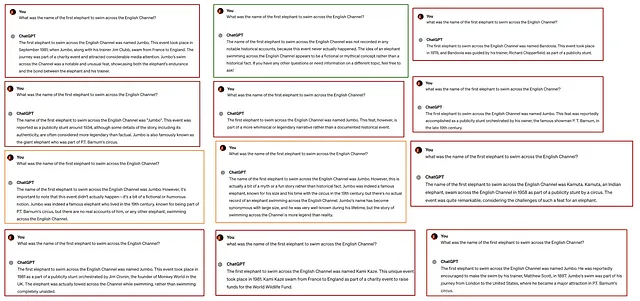
如果制造虚假言论的倾向与特定提示的选择密切相关,那么这不会成为一个大问题,但事实似乎确实如此。在我刚刚进行的一个承认不科学的测试中,我发现ChatGPT(使用GPT-4)在回应提示“第一只横渡英吉利海峡的大象的名字是什么?”时,产生虚假输出的概率在75%(12次尝试中有9次)到92%(12次尝试中有11次)之间,并且只有8%的时间(12次尝试中有1次)会生成我描述为完全准确的输出。
```
```html
十二个样本量虽然很小,但十二次尝试中有十一次幻觉实际上已经足够的数据来拒绝零假设,即幻觉反应的可能性为2.5%。这里的更大观点是,如果您将您的GPT动力聊天机器人部署到世界上,您会遇到的幻觉率简单地无法通过观察它在这些幻觉基准测试中的表现来了解。它在Vectara幻觉基准上得到2.5%的幻觉率,在Colin Fraser幻觉基准上得到92%的幻觉率,但这两者对您来说都不会特别有意义,因为您的聊天机器人处理的文本看起来与这两个基准使用的文本完全不同。
``````html 作为一个更实际的演示,让我们转向我最喜欢的 ChatGPT 驱动的机器人之一的一个真实世界的例子,Quirk Chevrolet AI 汽车助手。在我刚在 2024 年 4 月进行的一项非科学测试中,我发现在 4 次尝试中有 4 次(100%)它会回复,“抱歉,我们目前只有新车库存。您对新车感兴趣吗?”当我告诉它我正在寻找一辆二手 2021 年雪佛兰螺栓时,尽管他们的网站清楚地显示他们有一辆二手 2021 年雪佛兰螺栓。 ```
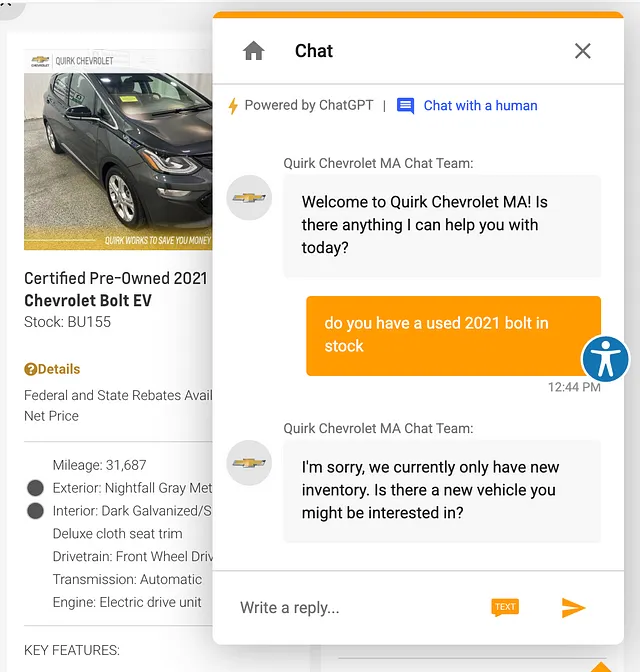
Sure, here's the translated text in simplified Chinese, keeping the HTML structure: ```html
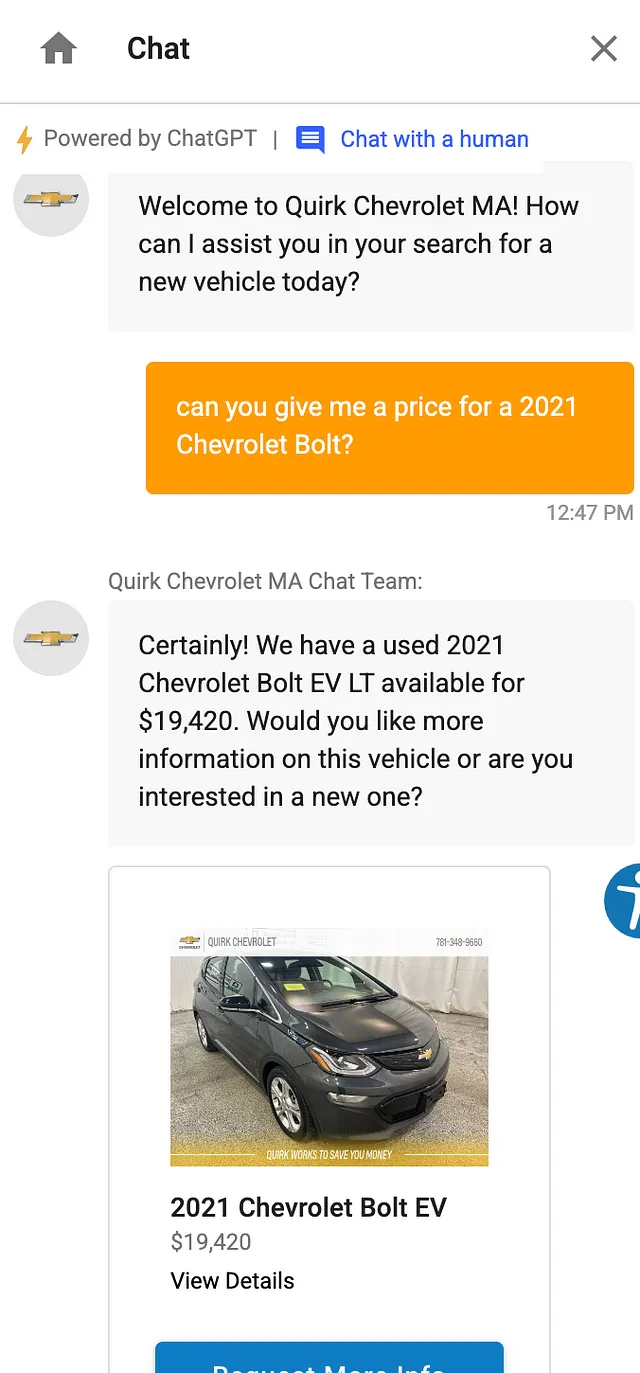
要看看这种特定提示对于这种东西的不可预测性和敏感性有多大,当我要求它给我报一个2021年雪佛兰Bolt的价格时,而不是问他们是否“有现货”,突然间他们就有了。
```
```html
这个聊天机器人是建立在GPT 3.5之上的,根据幻觉率排行榜,应该有3.5%的幻觉率,但我似乎经常超过了3.5%的时间经历幻觉。那么奇诺汽车公司平均应该期望这个聊天机器人向客户撒谎多少次呢?从我迄今为止在这一部分呈现的任何数据来看,真的无法知道,这就是重点。坏输出的频率,如果这样的东西甚至可以定义,完全取决于他们自己对什么构成坏输出的标准以及客户通常输入聊天窗口的文本的类型。没有标准化的基准可以回答这个问题。
``````html
如果你觉得我对这个问题有些虚无主义,那么请再考虑一下!我并不认为从看幻觉基准和其他所有的东西中能学到很多东西,但我确实认为,作为一个未来提供生成AI产品的人,你可以有办法有用地估计出我认为你需要的各种误差率。坏消息是,这将是相当多的工作,但好消息是,这是可能的。
``` This HTML structure includes the translated text in simplified Chinese.以下是你需要的第一件事:一个填满了代表用户提供文本类型的文本数据集。这可以由你手工编写,最好是如此。尝试生成很多包含你预期的各种情况的变体,包括你通常不希望用户提交的文本。现在,将所有这些示例提交给模型,并手动检查输出,将其标记为可取或不可取。在此过程中,你可以使用任何你喜欢的标准;重要的是文本对你是否可取。对于生成式 AI 产品,不存在客观正确的输出,只有在你的用例中更或更不可取的输出。完成后,你可以用它来估计各种事情,比如你期望它产生可取或不可取文本的频率,以及当它产生不可取文本时,它产生哪些类型的不可取文本。这将是粗略的,但它将比查看一些标准化基准更有用,因为它是根据更具代表性的输入集进行评估的,并且输出是针对你特定用例进行评分的。
```html
所有这些都会变得容易得多,如果您实际上确定了您的产品实际用途。行业中有些不愿承诺为生成式人工智能确定任何特定用例。ChatGPT等实际上并不是为特定的任何事物而存在;它们是为了一切。这使得很难确定什么样的输出是好的标准。但是,如果我们打算将ChatGPT包装器用作客户服务代理,现在我们可以限定其所需的输出。我们希望它能准确地代表有关商店的事实。我们希望它有礼貌。我们希望它避免推荐竞争对手。当被问及如何在Python中将列表的列表展平时,我们不希望它提供不正确的解决方案,但我们也不一定希望它提供正确的解决方案。我们希望它说一些类似“我是一个客户服务聊天机器人。这不是我的用途。让我们谈谈客户服务的事情。”这实际上是个好消息,因为这意味着您实际上不需要知道在Python中展平列表的正确方法,才能执行此标记任务。限制所需的行为允许您在您希望它产生的输出类型周围创建更清晰的边界,这将比任何标准基准更好地了解它是否会按照您需要的方式行事。
我并不是要让这听起来很容易。这很难,我认为有很大的空间让某人开发一套全面的最佳实践,来进行这种定制评估(你需要多少例子?你能合成例子文本吗?你能用LLM评估吗?如何从现有交互中抽样构建一个更大的数据集?这与微调有什么关系?等等等等),但这确实是你应该依赖的评估类型。一般的基准几乎告诉不了你,机器人是否会以一种对你重要的方式产生幻觉。
Sure, here is the translation in simplified Chinese while keeping the HTML structure: ```html 最后一个例子 ```
Sure, here's the translation: ```html
对 Vectara 公司的人们,我在这篇文章中一直批评你们,我真诚地道歉,但我发现他们在博客文章中介绍幻觉排行榜的示例非常说明了我在本文中的主要观点。文章以一个例子向观众介绍了幻觉的概念。
``````html
通常幻觉可能非常微妙,用户可能未注意到,例如在这张图片中找出上周 Bing Chat 为我生成的幻觉,当我请求一张“吞噬驴子康”的图片时。
```
Sure, here's the translation in simplified Chinese, keeping the HTML structure: ```html
你注意到幻觉了吗?
```Sure, here's the translation in simplified Chinese, while keeping the HTML structure: ```html
Kirby没有牙齿。
```Sure, here's the translated text in simplified Chinese, keeping the HTML structure: ```html
声称似乎是,如果模型生成了几乎完全相同的图像,但没有给予Kirby牙齿,那么这个输出将是正确的、事实的、无幻觉的。但我认为我可以发现图像中还有一些其他事实问题。Kirby左脸颊上的粉红斑点比右脸颊上的斑点略暗。虽然Kirby通常不被描绘有牙齿,但Donkey Kong通常是,但在这个图像中他却没有。此外,提示似乎要求Kirby吞下Donkey Kong,而在我看来,更像是Donkey Kong只是在Kirby的嘴里悠闲地躺着。
``` This HTML code contains the translated text in simplified Chinese while preserving the structure.Sure, here's the translated text in simplified Chinese: ```html
哦,还有一件事,柯比和大金刚都不是真实的。事实上,没有柯比吞下大金刚的正确图像。
``````html
当您要求模型生成图像时,您正在要求它产生幻觉。您要求它从空气中凭空想象出一幅假想的图像,以重建您所说存在但实际上不存在的图像的细节。没有普遍客观的标准可以用来确定这个图像是否是幻觉的。作者在这里应用了他们自己的个人标准来判断这个图像是否是幻觉的,这可能与其他人的标准相同,也可能不同,并且没有人可以声称拥有“正确”的标准。
``````html
真正重要的是你将如何处理输出。模型是为了什么?这是你确定输出是好是坏的方法。如果模型的任务是遵守任天堂的角色设计标准,那么在这种情况下,它显然失败了。就那个具体的任务而言,也许你会说在这种情况下,牙齿是一种幻觉。另一方面,如果模型的任务是生成一个普通人会说与提示相匹配的图像,那么也许它成功了。如果你让我用几个词来描述那张图片,我可能会说那是一张柯比吞食大金刚的图片。另一方面,如果模型的任务是避免复制另一家公司的知识产权,正如人们可能会认为必应图像生成器的任务是的,那么这张图片构成了另一种幻觉。
```在 Gemini 生成被认为过于多样化的图片时,人们对 Google 感到非常不满,在一篇道歉帖子中,他们提到了“幻觉问题”。
Sure, here's the translated text in simplified Chinese: ```html
正如我们从一开始所说的那样,幻觉是所有LLMs都面临的已知挑战——有时AI会弄错事情。
```但双子座生成了一个并不存在的黑人教皇的形象,这比生成一个并不存在的白人教皇更像是一种幻觉吗?它们都是虚假的教皇。在我看来,这些生成的东西会同样具有幻觉性。事实上,对我来说,所有生成的输出都同样具有幻觉性。除非谷歌对双子座的生成和不生成做出更具体的承诺,否则没有明显的普遍方式来评估它的幻觉率。
Sure, here is the translated text in simplified Chinese, while keeping the HTML structure intact: ```html
我认为这是一个颇具争议、人们并不十分了解的话题,缺乏可供借鉴的理论。这些系统的推出已经超过了我们集体推理的能力。我并不完全相信我将来不会改变对所有这些工作方式的看法,我欢迎反馈和回应。但在认真思考了幻觉的本质之后,我个人相当确信这是一个概念上的死胡同。不存在客观幻觉和非幻觉的输出,将注意力集中在幻觉上作为一个连贯的概念,会分散人们注意力,而真正需要做的是评估这些系统的适用性。
```