Sure, here's the translation in simplified Chinese: ```html 语言模型的校准技术:提升概率评估标题> ```
Sure, here's the translation in simplified Chinese: ```html
语言模型,尤其是大型语言模型(LLMs),通过其理解和生成类人语言的能力,彻底改变了人工智能领域。这些模型不仅能够在零-shot设置或通过定制提示的情况下执行各种任务,而且它们的灵活性和多样性使它们在多个领域都异常有用。
``` Let me know if you need anything else!Sure, here is the translated text in simplified Chinese while keeping the HTML structure: ```html 然而,尽管它们的有效性,但经常仍然面临挑战的一个关键方面是这些模型的校准 — 确保它们提供的关于各种输出的概率真正反映了这些输出正确的实际可能性。 ```
这篇文章探讨了对LLM进行校准的必要性,确定了围绕其概率评估的核心问题,并探讨了实现更好模型校准的现代方法。
Sure, here's the translation of "Why Calibration is Crucial for LLM Models" in simplified Chinese while keeping the HTML structure: ```html 为什么校准对LLM模型至关重要 ```
以下是将英文文本翻译成简体中文并保留 HTML 结构: ```html
LLM 的核心在于处理和生成基于语言的输出,这些输出不仅准确无误,而且还分配了正确的置信水平。校准 —— 或将模型的置信与准确性对齐的过程 —— 是不可或缺的,因为:
```Certainly! Here's the translated text in simplified Chinese, keeping the HTML structure: ```html
值得信赖的人工智能决策:正确校准的置信度分数可以让用户信任并依赖人工智能所做的决定,了解模型何时可能正确或错误。
```Sure, here's the translated text in simplified Chinese: ```html
风险管理:
在安全关键的应用中,如医疗诊断或自动驾驶,过于自信但不正确的预测可能导致灾难性的结果。
```Sure, here's the translated text in simplified Chinese: ```html ``` This HTML comment maintains the structure while providing the translated text in simplified Chinese.
Sure, here's the text translated into simplified Chinese while maintaining the HTML structure: ```html
在校准LLM概率方面的挑战
```在翻译这段文字之前,我需要确认一下,你是想让我把英文文本翻译成简体中文并保留 HTML 结构吗?
封闭模型约束:许多LLM以黑盒子的形式运行,直接访问对数概率的能力有限,使理解和调整置信度得以复杂化。
在训练中的错位:使用诸如人类反馈强化学习(RLHF)等技术细化的模型可能会变得天真地未校准。根据文献[1],最广泛使用的LLM经过人类反馈强化学习(RLHF-LLM)进行了微调。一些研究表明,RLHF-LLM产生的条件概率非常糟糕地校准。研究结果表明,RLHF-LLM可能优先考虑紧密遵循用户偏好而不是产生良好校准的预测,可能导致校准不良。这展示了一个关键挑战,即通过RLHF训练的模型可能缺乏准确和可靠输出所需的概率校准。
任务特定的校准需求:通常情况下,对LLM的通用训练并不会针对特定任务或领域进行调整,需要额外的校准来使其与特定需求或应用程序保持一致。
高级LLM校准方法
Sure, here's the translation of your English text into simplified Chinese while keeping the HTML structure: ```html
为了解决校准挑战,我们可以尝试以下讨论的各种技术:
``` This HTML code will display the translated text in simplified Chinese while maintaining the structure of your HTML document.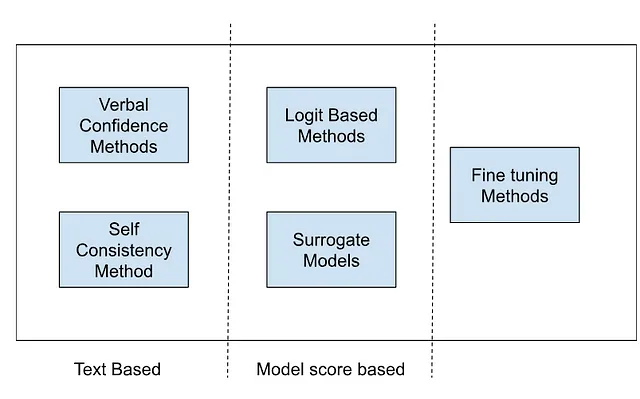
Sure, here's the translation in simplified Chinese, while keeping the HTML structure: ```html 口头表达的信心 ```
“口头表达的自信”指的是语言模型(LLM)不仅提供答案,而且明确评估其回答的信心的技术。这种方法涉及使用某些方法来获得模型对其答案的信心的更可靠评估。
基本实施
Sure, here's the translated text in simplified Chinese within an HTML structure: ```html
在其最简单的形式中,口头表达的自信涉及用一个问题和任何相关的背景来提示LLM,然后明确地要求一个自信度评分。这种直接的方法为更复杂的技术奠定了基础。
```高级技巧,增强口头表达信心
- Sure, here's the translated text in simplified Chinese: ```html 链式思维(CoT)提示:链式思维提示涉及在模型提供答案之前引出逐步推理过程。这种方法不仅可以增强模型回答的清晰度和丰富性,还可以通过观察推理步骤中的逻辑一致性来改善对置信水平的估计。 ```
- Sure, here's the translated text in simplified Chinese, keeping the HTML structure: ```html 多步置信引导:此技术通过在推理或解决问题过程的各个步骤捕获置信分数来精细化置信度测量。最终的置信水平是由所有个体置信分数的乘积得出的,提供了一个复合的确定性度量。 ```
- 顶K个回答和置信度评分:模型不再生成单一的回答,而是生成多个可能的答案(顶K个回答),每个答案都附带一个独立的置信度评分。然后选择具有最高置信度评分的回答作为最终答案。这种方法反映了涉及评估多个假设的决策过程。
- Sure, here is the simplified Chinese translation of your text, while keeping the HTML structure intact:
```html
多样的提示技术:利用各种提示可以导致更准确的信心估计。提示的多样性可以来自不同的措辞、背景或概念角度,使模型的评估对偏见或信息不足的回应更加健壮。``` This HTML structure will preserve the content while allowing for proper formatting and rendering on a webpage.
- Sure, here's the translated text in simplified Chinese while keeping the HTML structure:
```html
数值概率与语言表达:在某些情况下,模型通过直接与正确性可能性相关联的数值概率来表达其信心。相反,像“很可能”或“可能不”这样的语言表达也可以使用。
``` - 在多个假设的情况下进行提示:最初,模型会生成多个答案候选项,没有置信度评级。在随后的交互中,它们评估每个答案的正确性概率。研究表明,以这种方式评估多个假设会显著改善校准。
以下是在不同模型结构和代的某些变化中有效表达信心的能力会有所不同。
自洽性基础置信
Sure, here is the translated text in simplified Chinese: ```html
基于自一致性的置信度方法是一种评估语言模型置信度的复杂方法,通过对相同查询生成多个响应并分析这些响应之间的一致性来实现。这种技术依赖于一个观点,即在不同条件下高一致性表明响应准确度高。
```Sure, here's the translation while maintaining the HTML structure: ```html Generating Multiple Responses 生成多个响应 ```
要从模型获得一系列答案,采用了几种策略:
Sure, here's the text translated into simplified Chinese while keeping the HTML structure: ```html 自我随机化:这涉及将相同的问题多次输入,但在不同的设置下。在这里,调整“温度”参数是一种常见的方法,它通过改变输出的预测性或随机性来操纵模型响应的多样性。 ```
Sure, here's the translation: ```html
提示扰动:通过改写问题的措辞以引发不同角度的回答。这测试了模型的健壮性,检查其是否在概念上类似但措辞不同的提示中保持一致性。
```Here's the translation of the text into simplified Chinese while keeping the HTML structure: ```html 误导性线索:在提示中引入故意的错误或误导性暗示,以评估模型的稳定性。类似于人类测试,这种方法观察模型是否像自信的人一样,能够忽略误导性信息并坚持正确或一致的回答。 ```
Sure, here's the translation: 聚合策略
保持HTML结构,将以下英文文本翻译为简体中文: 为了综合研究结果并确定最终的置信度评分,可以考虑不同的聚合策略:
一致性度量:这检查模型在不同条件下提供相同答案的一致性程度,反映了稳定性和可靠性。
平均置信度(平均置信度):计算加权平均值,对具有较高一致性和个人置信度分数的答案给予更多权重,提供了对整体置信度的精细测量。
Sure, here's the translation: ```html
配对排序策略:在使用模型的前K个预测的场景中特别有用,此策略强调模型预测的排名信息,有助于评估最可能和一致的响应。
```Sure, here's the translation:
```html
基于Logit的方法
```
```html
对数几率校准是改善大型语言模型(LLMs)产生的概率预测可靠性的关键技术。当模型输出原始分数(例如对数概率)时,它们通常不能直接转换为真正的概率分布。校准技术调整这些对数以反映更准确的概率,这对于实际应用中的健壮决策至关重要。以下是一些用于基于对数几率的校准的方法:
```在标记之间平均置信度
要得出语言模型预测的信心更一致的估计,常用的方法是对各个标记的信心(对数概率)进行平均。这可以对所有标记或选择性子集进行,具体取决于特定应用或数据集的特征。结果是模型确定性更平滑、更可推广的度量,减少了任何单个标记变化的影响。
Sure, here is the translation: ```html 2. Platt 缩放(Sigmoid) ```
Sure, here's the translated text in simplified Chinese: ```html
Platt缩放,或S形校准,是应用于原始模型输出logits的逻辑回归模型。通过拟合S形函数到logits上,这种方法将它们转换为校准后的概率。校准涉及学习两个参数,通常表示为“A”和“B”,它们缩放和平移logits以更好地与实际观察到的概率对齐。这种方法特别适用于二元分类任务,因为它简单而有效。```
Sure, here's the translated text in simplified Chinese while keeping the HTML structure: ```html
等渗回归
```Sure, here is the translated text in simplified Chinese, while maintaining the HTML structure: ```html
与普拉特缩放不同,保序回归不假设对数和概率之间的任何函数形式。它是一种非参数方法,将非递减函数拟合到预测概率与目标概率一致。这种分段常数函数具有灵活性,可以更准确地反映某些情景中的真实分布,特别是当对数和概率之间的关系更复杂或非线性时。
```温度缩放
温度缩放是一种后处理技术,它调整模型的置信度而不改变其预测。它涉及将逻辑值除以称为“温度”的常数,然后应用softmax函数将其转换为概率。通常通过在验证数据集上最小化交叉熵损失来确定最佳温度。这种方法吸引人之处在于对校准过程的最小影响,保持了原始逻辑值的相对顺序。
代理模型或微调方法
在HTML结构中保持不变,将以下英文文本翻译为简体中文: 微调,一种高级的校准方法,通过特定的数据和目标来微调模型,以更好地为特定任务做准备。让我们探索几种创新的方法,帮助微调这些模型,提供更可靠和精确的置信度评分。
Sure, here is the translated text in simplified Chinese while preserving the HTML structure: ```html 通过替代模型进行信心评估 ```
Sure, here's the translated text in simplified Chinese while maintaining the HTML structure: ```html 一个迷人的方法[2]使用第二个、通常更简单的模型来评估主模型(如 GPT-4)的答案可信程度: ```
Sure, here's the translated text in simplified Chinese while keeping the HTML structure intact: ```html 它的作用:例如,可以使用LLAMA2这样的次要模型,通过提供相同的提示并提取GPT-4模型响应的分数,来获取其他模型(如GPT-4)生成的答案的对数概率。 ```
令人惊讶的效果:尽管次要模型可能不那么强大,但与仅使用语言线索相比,该方法已被证明在产生更好结果(通过曲线下面积,即AUC)方面效果更佳。
识别不确定性:R调优
Sure, here's the translation in simplified Chinese: ```html
R调优教会了模型何时可以说:“我不知道” —— 认识到自己的局限性。微调过程包括以下步骤:
```识别不确定性:通过进行预测并将其与实际情况进行比较,在训练集中找到模型答案可能不确定或值得怀疑的情况。
在确定性训练中:然后使用标记为“确定”或“不确定”的示例来教授模型,确保它从这些区别中学习。在训练过程中使用诸如“我确定”或“我不确定”之类的短语来表达信心水平,重点是从令牌生成开始学习,以降低错误。
Sure, here's the text translated into simplified Chinese, while keeping the HTML structure: ```html LITCAB:小变化,大影响 ```
LITCAB 介绍了一个小巧而有效的校准层:
Sure, here's the text translated into simplified Chinese while keeping the HTML structure: ```html 简单添加:它在模型末尾添加一个单一的线性层,根据输入文本微调每个响应的预测可能性。 ```
Here's the text translated into simplified Chinese while keeping the HTML structure: ```html 高效且有效:这个小调整增强了模型的判断能力,而且并未增加太多复杂性 —— 原始模型大小变化不到 2%。 ```
Sure, here's the translation of "ASPIRE: Smarter Model Responses" in simplified Chinese while maintaining the HTML structure: ```html ASPIRE: 更智能的模型响应 ```
Sure, here is the translated text in simplified Chinese, keeping the HTML structure: ```html 分配置信度评分给预测,并允许选择性预测。ASPIRE包括三个阶段: ```
Sure, here's the translation: ```html
任务特定调整:它使用PEFT技术修改特定的适应参数,同时保持主模型不变,为特定任务优化响应。
Sure, here is the translation in simplified Chinese: 答案抽样:它使用这些调整来为每个问题生成几个潜在答案,它使用束搜索作为解码算法来生成高可能性的输出序列,并使用Rouge-L度量来确定生成的输出序列是否基于真实情况正确。
Sure, here's the translated text in simplified Chinese: ```html 3. 自我评估学习:最后,它介绍了另一组调整,帮助模型自行判断其回答是否正确,提高其自我评估能力。 ```
通过这些方法,语言模型不仅变得更加先进,而且更加符合用户的语境和期望,从而导致更可靠和具有上下文意识的交互。
结论
Sure, here's the translation in simplified Chinese, maintaining the HTML structure: ```html
校准大型语言模型是一个复杂但至关重要的努力,可以提高人工智能应用的可靠性和安全性。通过使用和结合上述讨论的各种创新方法,我们可以显著改善这些模型在各种情境下的理解和互动,为真正能够以高度自信和正确性做出决策的智能系统铺平道路。
```附录:
- Sure, here's the translation in simplified Chinese while keeping the HTML structure intact:
```html
```Katherine Tian, Eric Mitchell, Allan Zhou, Archit Sharma, Rafael Rafailov, Huaxiu Yao, Chelsea Finn, and Christopher D. Manning titled “Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback,”
- Sure, here's the translated text in simplified Chinese: "驼群知晓GPT无法展示的事实:置信度估计的替代模型,作者:Vaishnavi Shrivastava,Percy Liang,Ananya Kumar"
- Sure, here is the translation in simplified Chinese while keeping the HTML structure: ```html R-Tuning: Instructing Large Language Models to Say ‘I Don’t Know’张翰宁♠∗,刁诗哲♠∗ 等。 ```
- Sure, here's the translation in simplified Chinese within the HTML structure:
```html
LITCAB: 轻量级语言模型在短篇和长篇回答中的校准
Xin Liu,Muhammad Khalifa,Lu Wang
``` - Sure, here's the translation: 数字的力量:通过提示一致性估算大型语言模型的置信度 吉温斯·波蒂洛·怀特曼、亚历山德拉·德卢西亚和马克·德雷德兹
- Sure, here's the translated text in simplified Chinese, while keeping the HTML structure:
```html
能够LLMS表达他们的不确定性吗?LLMS中置信度引导的实证评估 缪雄1∗,胡志远1,陆新洋等。
``` - 介绍 ASPIRE 用于 LLMs 的选择性预测
- 在确认之前三思:通过对多个答案的反思进行大型语言模型的置信度评估 梅欣立,王文杰等
- 校准大型语言模型的长文生成 黄宇坤 刘一心等

Sure, here's the translated text in simplified Chinese within an HTML structure: ```html
这个故事是在生成式人工智能出版下发布的。
```Sure, here's the HTML structure with the text translated to simplified Chinese: ```html Connect with us on Substack, LinkedIn, and Zeniteq to stay in the loop with the latest AI stories. Let’s shape the future of AI together! ``` Translated text: ```html 通过Substack、LinkedIn和Zeniteq与我们联系,保持与最新的AI故事的联系。让我们共同塑造人工智能的未来! ```