Mixtral 8x7B:稀疏专家模型的突破性进展
简介
近年来,自然语言处理领域取得了显著的进展,像GPT-3.5和Llama 2这样的模型刷新了新的纪录。然而,这些模型的局限性,如计算成本和延迟,促使开发出更高效的替代方案。
Mixtral 8x7B是这些问题的一个开源解决方案。它不仅在多个基准测试中成功击败了Llama 2(甚至是GPT-3.5),而且它所使用的权重数量更少。它不仅拥有更小的权重总数,而且通过每次只选取14B,其计算效率更高。而且,如果这还不够,它的上下文长度为32k个标记!
理解混合体系结构
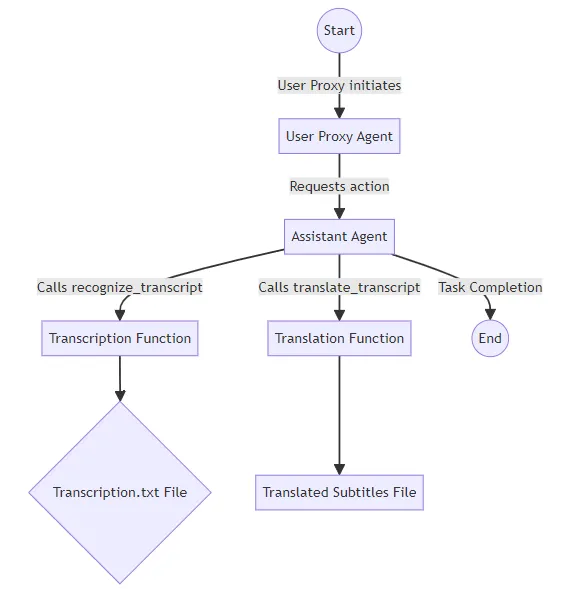
Mixtral是一种稀疏的专家混合(MoE)网络,专门设计为一个仅有解码器的模型,具有一个独特的前馈模块,可以从8个不同的参数组中选择。一个路由网络决定哪两个组("专家")将处理令牌,并将它们的输出以加权和的形式组合起来。这种方法显著增加了模型的参数数量,同时通过仅对每个令牌使用参数的子集,保持对成本和延迟的控制。
模型是使用32k令牌的多语言数据进行训练的。Mixtral使用4096维和32层。
路由器网络
对于每一层和每一个令牌,Mixtral使用一个“路由器”或“门控网络”来选择两个专家。
Mixtral 使用一个由线性层和 softmax 组成的路由器来为其 8 个专家生成权重。其中前 K 个被选中(设置 K=2),其余的权重为 0(在 softmax 之后)。
当权重为0时,Mixtral跳过对这些专家的计算。
专家层的混合
每个专家层每次接收一个令牌。这个令牌被传递回路由器,然后发送到下一层(也许是不同的专家!)。
这样可以让模型在单个查询中利用许多不同的专家(这样权重就不会浪费)- 每个层的每个标记都可以由不同的K个专家处理。
MoE(Mixture of Experts)层替换了变换器块中的前馈(FFN)子块。Mixtral使用与专家函数Ei(x)相同的SwiGLU体系结构,并设置K = 2。这意味着每个标记将被路由到两个具有不同权重集的SwiGLU子块。
在该系列的n-1个项中,只有2个项是非零的,而其余项的SWiGLU无需计算。
稀疏的专家混合模型
Mixtral 的核心在于它的稀疏专家混合(MoE)层。该层的输出由专家网络的输出加权和确定,权重由门控网络的输出提供。门控向量的稀疏性通过避免计算具有零门控的专家的评估,实现了高效计算。Mixtral采用了一种精密的门控策略,即 Softmax(TopK(x · Wg)),以选择每个标记的前 K 个专家。
结果和比较
Mixtral已经在各种基准测试中与Llama 2 和GPT-3.5进行了评估,包括常识推理、世界知识、阅读理解、数学和代码生成。
特别值得注意的是,Mixtral在推理过程中使用的活动参数显著减少,从而在成本和性能方面更高效。评估结果与Llama 2 70B进行了比较,展示了Mixtral仅利用部分参数就能超越或与其性能相匹配的能力。
由Sumedh Chatterjee、Ryan Jacob George和B Shabarish编写,AI Club,CFIIIT马德拉斯的协调员。