多代理人自动生成与函数 - 带有代码示例的逐步指导
通过AutoGen 改变与AI的互动
AutoGen作为一个开创性的多智能体对话框架,彻底改变了基础模型的利用方式。这个创新平台拥有灵活、可对话的智能体,能够通过自动化智能体聊天融合大型语言模型(LLM)、工具和人类洞察力。AutoGen的独特方法不仅简化了复杂的LLM工作流程,还最大限度地发挥了它们的性能,标志着下一代LLM应用开发的重大飞跃
AutoGen的本质:可对话和可定制的机器人
在AutoGen的核心是其代理,其设计考虑了对话。这些代理可以无缝交换信息,通过代理之间的对话为协作任务解决铺平道路。这些代理可根据需要进行定制,可以结合LLM、人类输入或两者兼顾,体现了灵活性和适应性。该框架具有内置代理,如AssistantAgent和 UserProxyAgent,每个代理都具有独特的功能。AssistantAgent利用LLM能够自动生成Python代码和建议,而UserProxyAgent作为人类代理可以在必要时执行代码并触发基于LLM的响应。
简化任务自动化与人际互动
AutoGen的卓越之处在于其能够在保留人类干预选项的同时自动化多代理通信。这种双重方法确保任务能够高效处理,无论是通过自治代理的交互还是人工指导。该框架的工具调用功能进一步提高了其效率,使代理能够有效地与外部工具和API进行交互。
赋予动态对话力量
AutoGen的多功能性扩展到支持各种对话模式,从完全自主的对话到人在循环问题解决。这种适应性在需要动态响应和复杂问题解决策略的应用中至关重要。
要更详细地了解AutoGen及其功能,请访问官方AutoGen文档。
逐步代码示例:
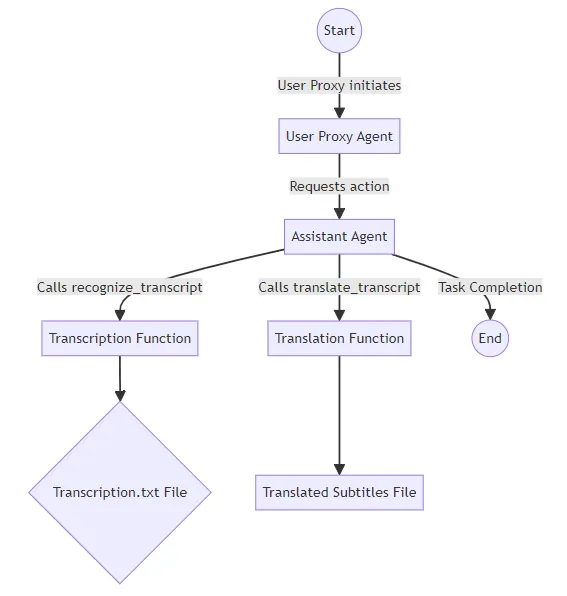
在我们即将进行的应用案例中,我们将探索将Whisper和GPT-4与AutoGen的AssistantAgent和UserProxyAgent集成起来。这次演示将侧重于处理视频文件,我们的目标是使用Whisper识别和转录口语。随后,我们将利用GPT-4的翻译能力将转录转换成另一种语言。最终目标是生成时间戳的字幕,展示AutoGen在媒体翻译和辅助功能增强方面的实际应用。
步骤一:安装必要的库
为了开始,我们需要确保我们的环境具备所有必需的Python库。以下是在你的笔记本中运行的命令,安装每个库:
- OpenAI:这是OpenAI的官方库,让我们能够与他们的API服务进行交互。
- openai-whisper:一个专门用于音频处理的库,特别针对使用OpenAI的Whisper模型进行转录。
- moviepy:一个多功能的视频处理库,可用于视频编辑任务。
- pyautogen:AutoGen的核心库,用于支持多代理对话式人工智能。
要安装这些库,在你的笔记本中运行以下命令:
%%capture --no-stderr
!pip install moviepy~=1.0.3
# !pip install openai-whisper~=20230918
!pip install openai-whisper
!pip install openai~=1.3.5
!pip install "pyautogen>=0.2.3"
确保您正在运行支持Python 3.8或更高版本的笔记本环境,因为这是AutoGen框架所必需的。
步骤2:设置您的API终点
在使用API密钥时,安全性和便利性至关重要。为了安全地设置您的OpenAI API密钥,请在您的笔记本中使用以下代码。将'your-api-key'替换为您实际的OpenAI API密钥。
import os
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
%env
通过这种方式设置API密钥,使得您的代码能够与OpenAI的服务进行无缝的认证,以进行任何后续的API调用,例如转录视频音频或翻译文本。
记住,在代码片段中提供的 API 密钥是一个占位符。在运行笔记本之前,请用您真实的 OpenAI API 密钥来替换它。
步骤3:导入库文件并进行配置设置
既然我们的环境已经设置好,下一步是导入所需的库并为我们的任务进行配置。
- 音频转录的耳语
- moviepy.editor用于处理视频文件。
- 使用openai来访问OpenAI功能。
- autogen 作为我们的对话式人工智能框架。
这就是实现这个功能的代码:
import os
import whisper
from moviepy.editor import VideoFileClip
from openai import OpenAI
import autogen
config_list = [
{
"model": "gpt-4",
"api_key": os.getenv("OPENAI_API_KEY"),
}
]
通过导入这些库,我们使得我们的笔记本能够转录和处理视频内容,并与OpenAI强大的语言模型进行交互。config_list是至关重要的,因为它指定了要使用的模型(在此情况下为gpt-4)以及在先前步骤中我们已经在环境变量中设置的API密钥的位置。
有了这个设置,我们现在可以开始使用视频和音频内容了。
步骤4:创建转录和翻译的功能和配置
让我们深入了解我们应用程序的核心功能。我们将定义两个必要的函数:
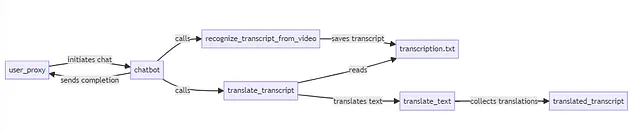
- 识别来自视频的转录:此函数接受从视频提取的音频文件路径,并使用Whisper模型将音频转录为文本。它处理音频片段以构建包含时间戳的转录。
- 这个函数将转录的文本发送到OpenAI的API,具体使用gpt-4模型,请求从源语言直接翻译到目标语言的适用于视频字幕的翻译。
我们的AutoGen代理、聊天机器人和用户代理的配置是通过llm_config字典来进行的。在这里,我们定义了我们的代理将使用的函数,并设置了通信参数,如系统消息和代码执行配置。
最后,我们启动用户代理和聊天机器人之间的聊天,并指示它们识别给定视频文件中的语音并将转录件翻译成所需的语言。
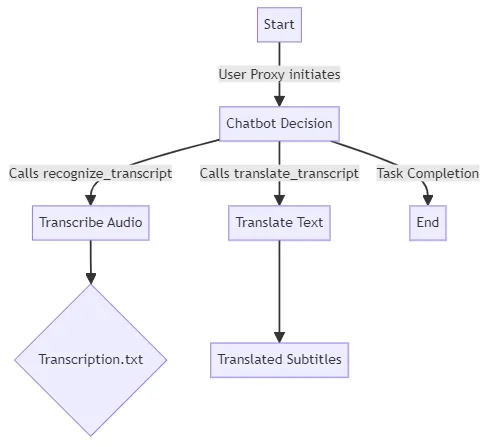
提供的代码将是这些操作的框架,您可以根据具体需求进行扩展和定制。以下是初始化和聊天开始的示例:
def recognize_transcript_from_video(audio_filepath):
try:
# Load model
model = whisper.load_model("small")
# Transcribe audio with detailed timestamps
result = model.transcribe(audio_filepath, verbose=True)
# Initialize variables for transcript
transcript = []
sentence = ""
start_time = 0
# Iterate through the segments in the result
for segment in result["segments"]:
# If new sentence starts, save the previous one and reset variables
if segment["start"] != start_time and sentence:
transcript.append(
{
"sentence": sentence.strip() + ".",
"timestamp_start": start_time,
"timestamp_end": segment["start"],
}
)
sentence = ""
start_time = segment["start"]
# Add the word to the current sentence
sentence += segment["text"] + " "
# Add the final sentence
if sentence:
transcript.append(
{
"sentence": sentence.strip() + ".",
"timestamp_start": start_time,
"timestamp_end": result["segments"][-1]["end"],
}
)
# Save the transcript to a file
with open("transcription.txt", "w") as file:
for item in transcript:
sentence = item["sentence"]
start_time, end_time = item["timestamp_start"], item["timestamp_end"]
file.write(f"{start_time}s to {end_time}s: {sentence}\n")
return transcript
except FileNotFoundError:
return "The specified audio file could not be found."
except Exception as e:
return f"An unexpected error occurred: {str(e)}"
def translate_text(input_text, source_language, target_language):
client = OpenAI(api_key=key)
response = client.chat.completions.create(
# model="gpt-3.5-turbo",
model="gpt-4",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": f"Directly translate the following {source_language} text to a pure {target_language} "
f"video subtitle text without additional explanation.: '{input_text}'",
},
],
max_tokens=1500,
)
# Correctly accessing the response content
translated_text = response.choices[0].message.content if response.choices else None
return translated_text
def translate_transcript(source_language, target_language):
with open("transcription.txt", "r") as f:
lines = f.readlines()
translated_transcript = []
for line in lines:
# Split each line into timestamp and text parts
parts = line.strip().split(": ")
if len(parts) == 2:
timestamp, text = parts[0], parts[1]
# Translate only the text part
translated_text = translate_text(text, source_language, target_language)
# Reconstruct the line with the translated text and the preserved timestamp
translated_line = f"{timestamp}: {translated_text}"
translated_transcript.append(translated_line)
else:
# If the line doesn't contain a timestamp, add it as is
translated_transcript.append(line.strip())
return "\n".join(translated_transcript)
llm_config = {
"functions": [
{
"name": "recognize_transcript_from_video",
"description": "recognize the speech from video and transfer into a txt file",
"parameters": {
"type": "object",
"properties": {
"audio_filepath": {
"type": "string",
"description": "path of the video file",
}
},
"required": ["audio_filepath"],
},
},
{
"name": "translate_transcript",
"description": "using translate_text function to translate the script",
"parameters": {
"type": "object",
"properties": {
"source_language": {
"type": "string",
"description": "source language",
},
"target_language": {
"type": "string",
"description": "target language",
},
},
"required": ["source_language", "target_language"],
},
},
],
"config_list": config_list,
"timeout": 120,
}
source_language = "English"
target_language = "Spanish"
key = os.getenv("OPENAI_API_KEY")
target_video = "/content/LiquidSyllabus.mp4"
chatbot = autogen.AssistantAgent(
name="chatbot",
system_message="For coding tasks, only use the functions you have been provided with. Reply TERMINATE when the task is done.",
llm_config=llm_config,
)
user_proxy = autogen.UserProxyAgent(
name="user_proxy",
is_termination_msg=lambda x: x.get("content", "") and x.get("content", "").rstrip().endswith("TERMINATE"),
human_input_mode="NEVER",
max_consecutive_auto_reply=10,
code_execution_config={
"work_dir": "coding_2",
"use_docker": False,
}, # Please set use_docker=True if docker is available to run the generated code. Using docker is safer than running the generated code directly.
)
user_proxy.register_function(
function_map={
"recognize_transcript_from_video": recognize_transcript_from_video,
"translate_transcript": translate_transcript,
}
)
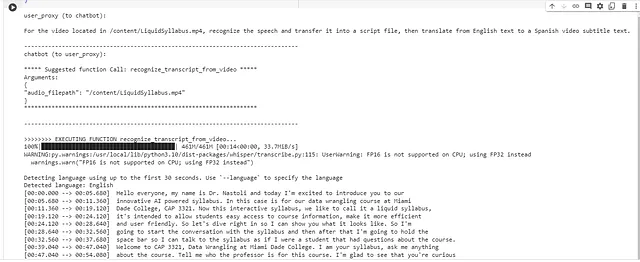
user_proxy.initiate_chat(
chatbot,
message=f"For the video located in {target_video}, recognize the speech and transfer it into a script file, "
f"then translate from {source_language} text to a {target_language} video subtitle text. ",
)

结论
总结起来,我们所踏上的旅程展示了AutoGen多代理对话框架的强大力量,利用尖端人工智能将原始视频内容转化为易于获取和翻译的字幕。通过利用Whisper进行转录和GPT-4进行翻译,我们弥合了不同语言和媒体之间的鸿沟,展示了人工智能在实际和变革性应用方面的能力。这个案例很好地说明了用户代理和助手等代理如何协同工作以自动化复杂任务,为内容本地化和易于获取性领域的创新解决方案铺平了道路。随着人工智能的不断发展,这种技术使全球交流更具包容性和连接性的潜力是无限的。