什么是文本和代码嵌入?Open AI嵌入模型。
嵌入是将概念转换为数字序列的数值表示,使计算机更容易理解这些概念之间的关系。这些嵌入在3个标准基准测试中表现优异,包括代码搜索上的相对改进达到20%。
嵌入(Embeddings)对于处理自然语言和代码非常有用,因为它们可以轻松地被其他机器学习模型和算法消耗和比较,如聚类或搜索。
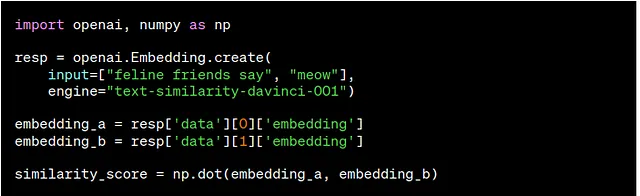
具有相似数值的嵌入向量也具有相似的语义。例如,“canine companions say”的嵌入向量与“woof”的嵌入向量之间的相似度更高,而与“meow”的嵌入向量之间的相似度较低。
新的端点使用神经网络模型,这些模型是GPT-3的后代,将文本和代码映射到矢量表示中,将它们“嵌入”到高维空间中。每个维度捕捉输入的某个方面。
新的/embeddings端点在OpenAI API中使用几行代码提供文本和代码的嵌入。
Open AI发布了三个系列的嵌入模型,分别针对不同功能进行了优化:文本相似度、文本搜索和代码搜索。这些模型可以接受文本或代码作为输入,并返回一个嵌入向量。

文本相似度模型
文本相似度模型提供了捕捉文本片段的语义相似性的嵌入。这些模型对于许多任务都很有用,包括聚类、数据可视化和分类。
以下互动可视化展示了来自DBpedia数据集的文本样本的嵌入。
来自文本相似性模型text-similarity-babbage-001的嵌入,应用于DBpedia数据集。我们从数据集中随机选择了100个样本,涵盖5个类别,并通过/embeddings端点计算了嵌入。不同的类别在嵌入空间中呈现出5个明显的聚类。为了可视化嵌入空间,我们使用PCA将嵌入的维度从2048降低到3。如何在三维空间中可视化嵌入空间的代码是可用的。
为了比较两段文本的相似性,您可以在文本嵌入上使用点积操作。结果是一个介于-1和1之间的“相似度得分”,有时被称为“余弦相似度”,其中较高的数字表示更大的相似性。在大多数应用中,嵌入可以预先计算,然后进行点积比较非常快速。
一种常见的嵌入使用方式是将它们作为机器学习任务(如分类)中的特征。在机器学习文献中,当使用线性分类器时,这个分类任务被称为"线性探测"。Open AI文本相似性模型在SentEval(Conneau等,2018)上实现了线性探测分类的最新最好结果,SentEval是一个常用的用于评估嵌入质量的基准。
线性探测分类在7个数据集上进行
文本搜索模型
文本搜索模型提供了嵌入,这些嵌入使得大规模搜索任务成为可能,比如在给定文本查询的情况下,在一组文档中查找相关文档。文档和查询的嵌入是分别生成的,然后使用余弦相似度来比较查询和每个文档之间的相似度。
基于嵌入的搜索可以比传统关键词搜索中使用的词重叠技术更好地进行泛化,因为它捕捉到了文本的语义含义,并且对确切短语或单词不太敏感。我们在《BEIR》(Thakur等,2021年)搜索评估套件上评估了文本搜索模型的性能,并获得了比先前方法更好的搜索结果。Open AI文本搜索指南提供了有关使用嵌入进行搜索任务的更多详细信息。
在BEIR的11个搜索任务中的平均准确率
代码搜索模型
代码搜索模型为代码搜索任务提供代码和文本嵌入。给定一系列代码块,任务是找到与自然语言查询相关的代码块。Open AI在CodeSearchNet(Husain等人,2019)评估套件上评估了代码搜索模型,Open AI的嵌入结果比以前的方法明显更好。请查看代码搜索指南以了解如何使用嵌入进行代码搜索。
6种编程语言的平均准确率
嵌入API的实例演示
JetBrains研究
JetBrains Research的宇宙粒子物理实验室分析诸如天文学者的电报和NASA的GCN通告等数据,这些报告包含了传统算法无法解析的天文事件。
凭借OpenAI对这些天文报告的嵌入技术,研究人员现在能够在多个数据库和出版物中搜索类似"蟹状脉冲星爆发"的事件。通过k-means聚类,嵌入技术在数据源分类上还实现了99.85%的准确率。
智能优化学习
FineTune Learning 是一家为学习构建混合人工智能解决方案的公司,例如自适应学习循环,帮助学生达到学术标准。
OpenAI的嵌入式系统极大地改善了根据学习目标查找教科书内容的任务。OpenAI的文本搜索Curie嵌入模型取得了89.1%的前五准确率,超过了之前的方法如Sentence-BERT(64.5%)。虽然人类专家仍然更胜一筹,但FineTune团队现在能够在几秒钟内标记整本教科书,而不像专家那样需要几个小时。
参考-Open AI博客页面