使用AutoGPT和Qdrant从您的数据中提取有价值的见解
本文介绍如何利用AutoGPT和Qdrant数据库从原始数据中提取有价值的见解的深度指南。
在数据科学不断发展的领域中,从海量数据集中提取有意义的洞见就像是在大海捞针。但如果我们能将这项艰巨的任务转变成一个直观、高效和出奇简单的探索之旅会怎样呢?欢迎来到我对AutoGPT和Qdrant的探索,这两个革命性的工具重新塑造了我们与数据的互动和理解方式。
无论您是经验丰富的数据科学家、好奇的初学者,还是介于两者之间,本探索旨在点亮从数据中提取有价值洞察的道路。因此,请系好安全带,一起踏上这个激动人心的冒险吧!
在本文中,我们将赋予GPT自主提示功能,并开发一个类似聊天的系统,用于与大型数据文件进行交互。我将使用Langchain作为AutoGPT和Qdrant之间的接口,用于检索任务和作为云向量存储。这是一个令人印象深刻的技术堆栈,为现代生态系统的数据剖析、检索和生成任务提供无缝集成。
让我们首先来看看AutoGPT,并了解它执行复杂任务的能力。
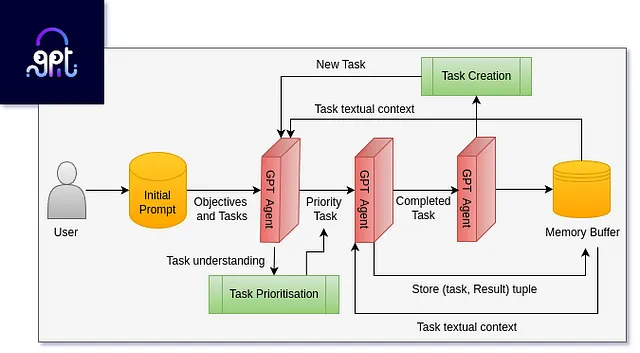
AutoGPT:使用自主任务执行强化GPT-4
AutoGPT代表了自动化领域的一次创新飞跃,超越了传统独立模型的界限。这是一个开创性的实验,有效地利用了像GPT-4和GPT-3这样先进的大型语言模型的令人印象深刻的能力。AutoGPT的核心目标是通过利用这些模型内嵌的广博知识和理解来自动化各种任务。它通过从LLM生成一系列指令,并执行它们来实现这一目标,主要集中在涉及编程逻辑和逐步执行的任务上。
为了将其放在透视中,以数据集的探索性数据分析(EDA)任务为例。AutoGPT 使用一种逻辑的、逐步的方法来处理这个复杂的过程。首先,它识别数据集并了解所需的分析类型。然后,它开始编写并执行一个 Python 脚本来导入数据,通常是从 CSV 或 Excel 文件中。接下来,AutoGPT 执行各种数据清洗步骤,如处理缺失值或异常值,然后执行一系列的命令进行数据可视化,例如创建直方图、箱线图或散点图,以理解数据的分布和关系。这种方法简化了数据科学中基本的复杂的 EDA 过程。
AutoGPT的真正亮点不仅在于自动化这些分析步骤,而且还在于它能够动态创建和调整适合数据集和分析目标的Python脚本,使探索过程既高效又有洞察力。
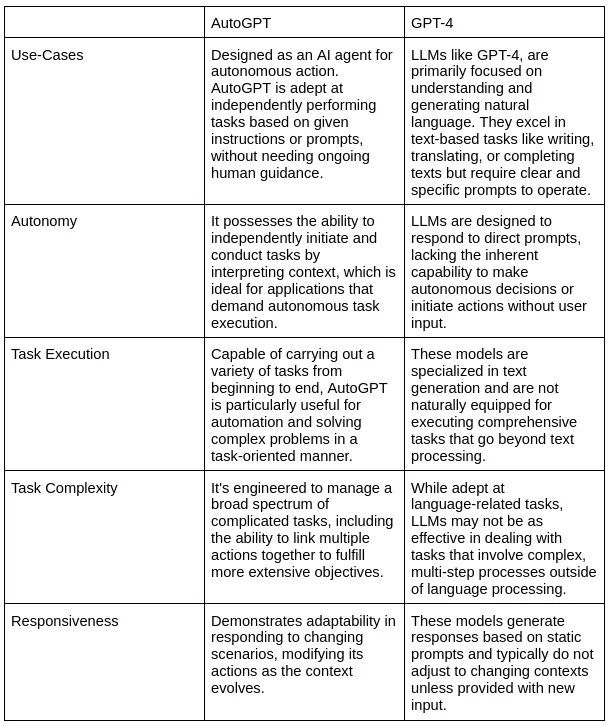
好的,现在我们已经了解了AutoGPT的框架以及它与ChatGPT之类的LLM有哪些不同。现在是时候更深入地了解它的工作原理和当前的界面了。此外,让我们执行一些自定义任务以进行更好的评估。
在AutoGPT上执行生成式语言建模任务
我们可以在Google Colab中轻松使用官方的AutoGPT代理程序。在这里,我们将使用AutoGPT进行推理任务;首先,让我们拉取官方的GitHub仓库Significant-Gravitas/AutoGPT。请准备好您的Open-AI API密钥以进行AutoGPT环境配置。
!git clone https://github.com/Significant-Gravitas/Auto-GPT.git -b stable --single-branch
%cd Auto-GPT/
!pip install -r requirements.txt
%cd Auto-GPT/
!cp .env.template env.txt
编辑“env.txt”文件并添加您的API密钥,现在使用以下命令将此新配置添加到环境中:“!cp env.txt .env”。我们将使用下面的命令初始化AutoGPT CLI界面。
!python -m autogpt # If you have GPT-4 accessible keys
!python -m auto-gpt –gpt3only # If you do not have GPT-4 keys
# We can also use the --continuous argument for recursive agent execution.
在这里,我们不设置连续模式:启用,在非递归查询复杂任务中实例化AutoGPT代理。

一旦启动了该工作流程,AutoGPT首先会询问当前的基础任务,在本场景中为"生成"。基于这个主要任务,AutoGPT灵活地分配一个特定于任务需求的GPT模型。对于生成任务,AutoGPT自动指定GenGPT代理,这是一个专门设计用于此目的的模块。

GenGPT代理使用四个关键组件,每个组件在生成过程中扮演着独特的角色:
- 思考:这是GenGPT的核心创意生成组件。它涉及收集和处理与任务相关的信息。该组件从其训练有素的知识库中综合数据,并将其与当前请求的上下文整合,从而形成回应背后的“思考”。
- 推理:在这里,GenGPT对手头的信息进行逻辑分析和批判性思考。这一步骤对于确保回答不仅仅基于数据,而且在逻辑上合理和符合语境至关重要。这是代理人评估信息的不同方面,检查一致性并形成连贯的论据或解释的地方。
- 批评:在这个阶段,GenGPT参与了一个自我评估过程。它对其形成的回答进行了批判性评估,寻找潜在的缺陷、偏见或错误。这种内部审查机制是保持回答质量和可靠性的关键,确保它们符合高标准的准确性和相关性。
- 说话: 最后一个组成部分就是回应的传递。"说话"涵盖了GenGPT表达其回应的方式,确保以一种清晰、连贯和用户友好的方式进行。这不仅涉及语言方面,还包括根据用户的查询风格和平台的要求来定制回应。
通过这些组件的结合,GenGPT能够生成不仅知识丰富和逻辑合理,而且具有批判性思维和高效沟通的回答,展示了AutoGPT在处理生成任务方面的先进能力。
爱丽丝梦游仙境


标题:“爱丽丝在钟表花园中的奇幻之旅”
在达灵顿这个古朴村庄中,以她无尽的好奇心而闻名的年轻的爱丽丝,在古老森林的中心发现了一个被青苔覆盖的隐藏门。推开门,她踏入了一个与众不同的世界——一个发条花园,在那里时间本身似乎在舞蹈和旋转。在这个奇幻的土地上,树木是由闪烁的齿轮组成的,花朵"滴答"地开放,与时间的节奏同步。爱丽丝受到了发条兔的欢迎,它是一只着装入时,胸口嵌有一只怀表的潇洒生物。“快点,爱丽丝,时间看守者的庆典即将开始,”它催促着,带领她穿过一片齿轮和弹簧的迷宫。他们在旅途中遇见了发条毛虫,它懒散地躺在由齿轮制成的蘑菇上,给爱丽丝提供关于时间本质的谜语和智慧。更远处,他们遇见了发狂的发条修补匠,一个奇特的发明家,与机器人和自动人形举办了一个无尽的茶会,庆祝着瞬息即逝的美丽。发条花园的中心由嘀嗒女王统治,她身穿编织银丝制成的长袍,守护着大时钟,控制着花园中时间的流动。然而,大时钟出现故障,导致时间失控。凭借她与生俱来的聪明才智和新结交的朋友的帮助,爱丽丝踏上了修理大时钟的旅程。通过一系列的冒险,从攀爬秒针塔到穿越时间迷宫,爱丽丝学会了时间那精巧的舞蹈和它珍贵的价值。
喝彩!!!我们制作了我们的第一个AutoGPT代理,并使其运行起来,生成了一篇关于“爱丽丝奇幻时钟花园之旅”的美妙故事。
在接下来的部分中,我们将解释如何改进使用Qdrant向量数据库的AutoGPT的检索能力。

将AutoGPT与Qdrant矢量数据库相结合。
Qdrant是一款创新的向量数据库,旨在高效处理复杂的高维数据。Qdrant的核心专注于存储和索引向量嵌入,使其成为在需要快速准确地检索相似项的任务中不可或缺的工具,例如推荐系统或图像搜索。Qdrant的优势在于其用户友好的API,简化了将高级搜索功能集成到各种应用程序的过程。此外,Qdrant提供了一项独特的功能,可以根据附加元数据来过滤结果,提高搜索结果的相关性和精确性。作为其他向量数据库(如Pinecone)的开源替代方案,Qdrant不仅易于访问,而且处于技术的前沿,提供了最先进的最近邻搜索速度。其处理向量数据的方法和持续改进的承诺使其成为处理复杂数据场景的开发者和组织的卓越选择。
在AutoGPT-DA集群中创建集合
现在,让我们开始在 Qdrant 云上构建一个云向量数据库集群。首先,我们将为实验目的创建一个免费的云集群。您可以根据具体用例和需求进行配置调整。
如果您是第一次使用Qdrant Cloud数据库,请查看我之前关于设置Qdrant Cloud集群和使用Thunder-HTTP客户端监控向量数据库的帖子。
让我们使用Python qdrant客户端检查AutoGPT-DA集群的状态,我们需要安装以下依赖项并将必要的API密钥导出到环境中:
!pip install qdrant-client
!export OPENAI_API_KEY="sk-SpCU2Iz2aoBEKS7F5QzDT3BlbkxxxxxxxxxxuyPX1hRCklJy" #Your API Key
!export Qdrant_API_KEY="ZcnKdbf9617SH5sy-wklOxxxxxxxxxvs3vsPeSo0_Zv3cOjQbg" #Your API Key
现在,我们将导入qdrant python客户端,并创建我们的集合以将向量嵌入作为数据点存储在集合中。
import os
from qdrant_client import QdrantClient
from qdrant_client.http import models
from qdrant_client.models import Distance, VectorParams
qdrant_client = QdrantClient(url="https://9444ba5f-a4a1-xxxx-xxxx-b24c6d459624.us-east4-0.gcp.cloud.qdrant.io",
api_key=os.getenv("Qdrant_API_KEY"),
)
vectors_config = models.VectorParams(size=768, distance=models.Distance.COSINE)
qdrant_client.recreate_collection(
collection_name="autogpt-collection",
vectors_config=vectors_config,
)
上述Python脚本初始化了Qdrant的向量配置,指定向量大小为1536,并将余弦距离定义为比较的距离度量。该配置设置了将在Qdrant系统中使用的向量的特征,确定了它们的大小以及用于测量向量之间距离或相似性的特定度量标准。
现在我们已经创建了我们的集合,我们需要一些嵌入以存储在我们的向量数据库中。

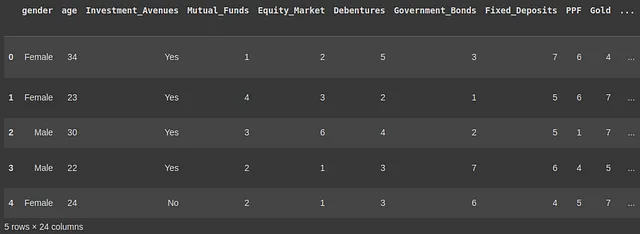
创建表格数据集的矢量数据库现在我们已经创建了我们的集合,我们将根据矢量配置将数据点追加为矢量化嵌入。在本文中,我将从Kaggle选择一个与股票市场相关的金融数据集。让我们来看一下我们数据集的初始格式。
import pandas as pd
import openai
file_path = "/content/Finance_data.csv"
df = pd.read_csv(file_path)
selected_columns = ['gender', 'age', 'Investment_Avenues', 'Expect', 'Avenue', 'Reason_Equity', 'Reason_Mutual', 'Reason_Bonds', 'Reason_FD', 'Source']
df['concatenated_text'] = df[selected_columns].astype(str).agg(' '.join, axis=1)
openai.api_key = "sk-SpCUxxxxxxxxJCw44h5sOuyPX1hRCklJy"
def get_embedding(text):
try:
response = openai.Embedding.create(input=text, engine="text-similarity-babbage-001")
return response['data'][0]['embedding']
except Exception as e:
print(f"Error in getting embedding: {e}")
return None
df['content_vector'] = df['concatenated_text'].apply(get_embedding)
final_df = pd.DataFrame({
'title_vector': list(df.index),
'content_vector': df['content_vector']
})
output_file = 'title_content_embeddings.csv'
final_df.to_csv(output_file, index=False)
上面的Python脚本创建了一个向量化的数据集,包含两列:“title_vector”用于存储行的索引,“content_vector”用于存储行的OpenAI嵌入。
索引数据
在Qdrant中,一个用于向量搜索的数据管理系统,数据被组织成称为“集合”的结构。每个集合都充当多个对象的容器,每个对象由一个或多个向量表示。这些向量实质上是捕捉对象特征本质的多维数据点,以数值形式呈现。此外,对象可以附带“负载”,这些负载是提供有关对象的额外上下文信息的元数据。
在您特定的情况下,您在Qdrant中建立了一个名为'autogpt-collection'的集合。这个集合独特之处在于,其中的每个对象都由两种不同类型的向量来描述:一种代表“标题”,另一种代表“内容”。这种双重向量的方法可以更加细致和详细地表示每个对象,提高了集合内搜索结果的准确性和相关性。
from qdrant_client.http import models as rest
vector_size = len(article_df["content_vector"][0])
qdrant_client.recreate_collection(
collection_name="autogpt-collection",
vectors_config={
"title": rest.VectorParams(
distance=rest.Distance.COSINE,
size=vector_size,
),
"content": rest.VectorParams(
distance=rest.Distance.COSINE,
size=vector_size,
),
}
)
接下来,我们将使用以下脚本将向量负载进行添加或更新操作,放入我们的集合中:
qdrant_client.upsert(
collection_name="autogpt-collection",
points=[
rest.PointStruct(
id=k,
vector={
"title": v["title_vector"],
"content": v["content_vector"],
},
payload=v.to_dict(),
)
for k, v in final_df.iterrows()
],
)
现在我们已经将所有的向量嵌入作为点插入了,我们可以开始将向量数据库与AutoGPT集成。
通过Qdrant向量数据库增强AutoGPT
我们可以通过将“env.txt”文件更新为来自OpenAI和Qdrant的密钥,轻松地将Qdrant与Autogpt集成起来。然后通过更新环境来完成。
!cp env.txt .env
现在我们将使用来自Langchain的AutoGPT集成,并使用向量存储作为代理的内存来装备向量存储嵌入。首先,让我们安装一些所需的依赖项:
!pip install langchain google-search-results openai tiktoken
蓝链-Quadrant整合
我们目前在云中设置了一个向量存储,可以被我们的任何应用程序访问。只需适当的访问凭据,我们可以轻松连接到该存储,而无需每次重新生成嵌入。我们下一步是将这个向量存储与我们的应用程序集成,使AutoGPT能够在问答任务中使用它进行查询处理。
from langchain.embeddings import OpenAIEmbeddings
from langchain.docstore import InMemoryDocstore
from langchain_community.vectorstores import Qdrant
from langchain.vectorstores import Qdrant
from langchain.llms import OpenAI
from langchain.chains import RetrievalQA
embeddings_model = OpenAIEmbeddings()
text:str
embedded_query = embeddings_model.embed_query(text)
vector_store = Qdrant(
client=client,
collection_name="autogpt-collection",
embeddings=embeddings,
)
Langchain-SerpApi集成
我们将使用API进行搜索引擎结果页面(SERP)查询。让我们使用Langchain作为语言处理代理设置工具如下:将SerpAPIWrapper初始化为一个搜索工具,包装一个用于搜索引擎结果页面(SERP)查询的API。
- 工具列表已创建,包括多个工具实例,每个实例都专为特定功能而设计。
- 一个名为“搜索”的搜索工具被添加,并具有针对当前事件的问题回答功能,通过定向查询进行定制。
- 此外,工具列表中还包括了写入文件的工具(WriteFileTool())以及读取文件的工具(ReadFileTool()),进一步增强了代理的文件管理能力。
import os
os.environ['SERPAPI_API_KEY'] = "b5eafbade1f9a4423fxxxxxxxxxx006ace4f1c9c408f1f3f22f5705513e186050"
os.environ['OPENAI_API_KEY'] = "sk-SpCU2Iz2aoBEKS7F5QzDT3BlbkxxxxxxxxxxuyPX1hRCklJy"from langchain.utilities import SerpAPIWrapper
from langchain.agents import Tool
from langchain.tools.file_management.write import WriteFileTool
from langchain.tools.file_management.read import ReadFileTool
search = SerpAPIWrapper()
tools = [
Tool(
name = "search",
func=search.run,
description="useful for when you need to answer questions about current events. You should ask targeted questions"
),
WriteFileTool(),
ReadFileTool(),
]
Langchain-AutoGPT集成
我们将使用ChatOpenAI模型,并使用特定配置初始化AutoGPT代理。
from langchain.experimental import AutoGPT
from langchain.chat_models import ChatOpenAI
agent = AutoGPT.from_llm_and_tools(
ai_name="AutoEDA",
ai_role="Analyst",
tools=tools,
llm=ChatOpenAI(temperature=0),
memory=vectorstore.as_retriever()
)
# Set verbose to be true
agent.chain.verbose = True
- agent = AutoGPT.from_llm_and_tools(...) 创建一个AutoGPT代理的实例,通过一组工具和语言模型进行配置。
- 代理人名为“自动EDA”,并被赋予“分析师”的角色,表明其目的或功能。
- 使用的语言模型是ChatOpenAI,温度设置为0,这控制了模型响应的随机程度。
- 代理的记忆链接到一个向量存储库(vectorstore.as_retriever()),使其能够从该存储库检索信息。
此外,line agent.chain.verbose = True 将代理设置为详细模式,可能会启用其操作的详细日志记录或输出。
噢耶!我们成功开发了一个AutoGPT代理程序,可以理解用于问答任务的大型原始数据集。我希望这个过程能够带给你启发,特别是在理解向量数据库、LangChain和OpenAI方面。继续关注更多令人兴奋的博客文章。
结论
在通过AutoGPT和Qdrant的旅程中,我探索了这些创新工具如何将数据分析转化为直观高效的过程。AutoGPT通过其自主任务执行与Qdrant向量数据库无缝配对,能够有效处理复杂的高维数据。这种组合简化了探索性数据分析等任务,确保回答不仅基于数据,还具有语境合理性。我对它们在现实世界场景中的整合和应用的探索凸显了它们在现代数据生态系统中的潜力,展示了自动化数据处理和洞察力提取的未来。
关注我的Twitter:@sidgraph
(注意:本博文与Superteams.ai合作完成。)