幻觉检测对于生成式语言模型的重要性 —— 第一部分

在语言模型幻觉检测系列的第一部分中,我们将深入研究理论和数学方面。随后的部分,即第二部分和第三部分,将重点介绍检测幻觉的实验方法。
让我们开始吧:
大型语言模型(LLMs)在各种生成任务中展示出了卓越的性能;然而,偶尔会出现虚构的情况。
这里出现的问题是-

我是不是幻觉了吗?
什么是LLMs中的幻觉?
- 生成的文本与输入提示不一致,缺乏忠实度:所以,当你给模型一个生成文本的指令时,你知道会发生什么吗?如果生成的文本偏离了你在提示中指定的内容,离题了,我们就说它缺乏“忠实度”。似乎模型没有遵守你给它的指示。
- 生成的文本在世界知识方面并不正确:当我们说生成的文本在世界知识方面并不准确时,我们指的是文本中呈现的信息与在现实世界中被广泛认为是真实的相矛盾。基本上,文本中包含的错误或不准确之处与已知事实或常识相矛盾。这是一个重要的问题,特别是当我们希望生成的内容有益且准确时。
我已经问ChatGPT这个问题。
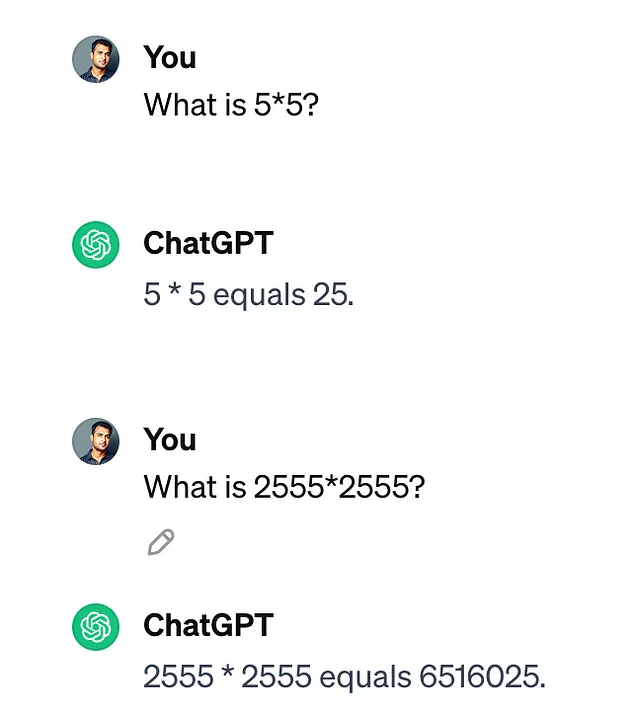
如下所示,2555*2555的乘积计算出错了,正确答案是65,28,025。
为什么大型语言模型(LLMs)会产生幻觉?
大型语言模型中出现幻觉的原因有两个明显的因素:
预训练数据:在这种情况下,幻觉可能是由于用于训练语言模型的大规模和多样化的数据集中包含的不同和常常相互矛盾的信息。该模型会从各种来源中学习,并存在于预训练数据中的相互矛盾或不正确的信息可能导致其在未来任务中对输入提示的回应发散,从而引发幻觉。
解码策略:语言模型的自回归性在解码过程中具有重要影响,可能导致产生幻觉。在自回归模型中[我们稍后将会讨论],文本按顺序生成,每一步都依赖于前面的上下文。这种顺序生成有时会添加想象力丰富或不准确的信息,从而产生幻觉。此外,解码过程中事实验证的困难也是造成这种情况的原因之一。模型可能难以成功检查生成信息的准确性,从而产生偏离事实正确性的结果。自回归生成和事实验证问题的混合对于幻觉的产生具有关键作用。
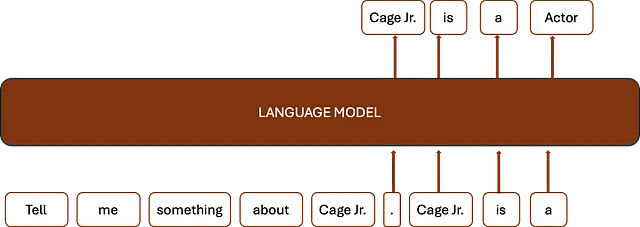
什么是自回归语言模型?自回归语言模型是一种机器学习模型,它使用自回归算法根据前面的词语预测一系列词语中的下一个词。这种方法在许多应用中都很有用,包括自然语言处理和机器翻译,因为它根据前面的词语提供的上下文来预测下一个词。
自回归语言模型的方程式:
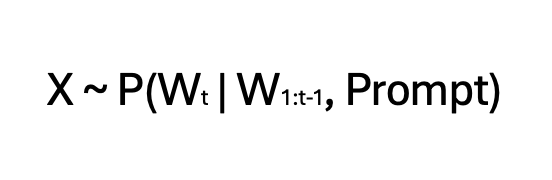
这个方程表示了在时间 t(Wt)时给定从W1到Wt-1的词序列的条件概率。自回归语言模型通过计算这个概率来预测序列中最有可能的下一个词。
确定性 vs 随机性:在语言模型的背景下,确定模型在创建下一个标记时是应该以确定性还是随机性的方式进行。在确定性模式下,模型严格遵循之前定义的规则,对于相同的输入提供相同的结果。相反,在随机性模式下,模型融入了不可预测性,即使是相同的输入也能产生多种结果。这种随机行为经常受到称为“温度”的变量的影响。调整温度可以影响生成文本中的独创性程度,较低的温度会产生更集中和可预测的结果,而较高的温度会产生更多样化和混乱的回复。
教师强制训练:教师强制训练,也被称为序列生成,是在训练循环神经网络(RNNs)和自回归模型(如语言模型)中经常使用的技术。在教师强制训练期间,模型会接收来自训练数据集的真实标记(或单词),而不是自己的输出。这种方法确保模型在训练过程中获得准确的输入,同时稳定学习过程。
好的,但是在这里的挑战是什么?
这里的挑战是值得注意的是,教师强迫训练会产生曝光偏差,通常被称为训练-推理差异。在训练期间,模型在每个阶段都接收到适当的输入,使其能够生成准确的预测。然而,在推理过程中,当模型自己创建输出时,它依赖于可能错误或嘈杂的先前阶段的预测。训练和推理之间的不匹配可能会导致错误和较差的表现。
现在让我们从数学角度来谈谈,这将给我们更深入的理解:

在训练过程中,模型的目标是最大化地真实序列的可能性。
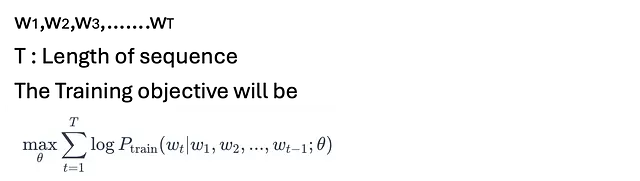
其中θ代表模型的参数。我们想要找到使θ最大化的值。
在推理过程中,模型独立构建序列,从自己预期的分布中进行抽样。

该模型旨在最大化生成序列的可能性。
由于曝光偏差,推断分布P-Inference可能与P-train不同,导致训练和推断之间存在差异。
为了减少曝光偏差,可以使用包括定期抽样、课程学习和基于强化学习的方法等策略。这些策略试图通过在训练过程中逐渐让模型接触自己的预测,或直接优化推理目标,来弥合训练和推理之间的差距。
检测自然语言生成中的幻觉
A) 自然语言生成(NLG)活动中已经出现了幻觉,尤其是在摘要生成中。幻觉是指模型生成的文本偏离了事实内容或上下文的现象,在自然语言生成(NLG)任务中被视为难题,尤其容易出现在摘要生成中。
让我们数学上讨论一下:
让H代表由模型生成的幻觉令牌集合
对于给定的参考摘要Sr和生成的摘要Sg,幻觉得分HS可以定义为:
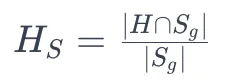
- 分子代表了生成摘要Sg和幻觉标记集H中同时存在的幻觉标记的数量。
- 分母代表了生成概要 Sg 中的总词数。
幻觉得分HS的范围为0至1,其中:
- HS=0表示生成的摘要中没有幻觉。
- HS = 1表示完全幻觉,即生成的摘要中的所有词汇都是虚构的。
B) 在总结过程中,生成的摘要会与原始文本进行比较,以确保其正确性和在收集重要信息方面的有用性。这种评估技术分析了总结模型在保持核心信息的同时能否压缩信息的能力。通过使用各种评估指标和方法来衡量生成的摘要与源文本之间的对齐程度,从而提供有关总结模型能力的信息。
让我们用数学的方法来连接这些点:
让我们将生成的摘要称为S,原始文本称为T。为了评估生成的摘要和原始文本之间的相似度,我们可以使用诸如余弦相似度之类的相似性度量。
两个向量v和u之间的余弦相似度定义为:
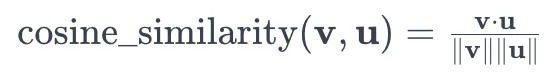

在摘要评估的背景下,我们可以将源文本和生成的摘要表示为向量t和s,向量的每个元素表示文本中某个单词或标记的出现频率。
源文本向量t和输出摘要向量s之间的余弦相似度可以如下确定:
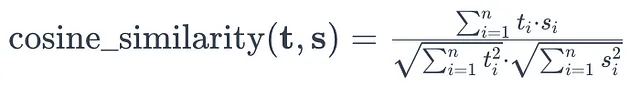
总词汇表中独特标记的总数用 n 表示,而 (t i) 和 (s i) 分别反映了源文本中第 (i) 个标记的频率和生成的摘要的频率。
这个余弦相似度度量计算了生成的摘要和源文本之间的相似程度,值越接近1表示相似度越高,值越接近0表示相似度越低。
现有的自然语言生成中衡量忠实度的方法包括很多技术:
- 文本重叠:该类别涵盖N-gram方法,如ROUGE / BLEU,以及基于嵌入的测试,如BERTScore。
- 基于信息提取:将Triple(源)与Triple(摘要)进行对比。该技术将从源文本中检索到的三元组(Triple(源))与从生成的摘要中提取出的三元组(Triple(摘要))进行比较,以确定摘要与原始材料的相似程度。比较可以包括确定两组三元组之间的重叠、相似性或差异,这将提供有关创建的摘要准确性的信息。
- 基于问答的方法:QAGS、QuestEval和MQAG等技术通过询问有关内容的问题来评估忠实度。
- 语言模型分数:BARTScore 是一种衡量语言模型性能的统计指标。
- 自然语言推理(NLI):该方法使用蕴含模型来评估源文本和摘要的一致性。
现在就这些了 :)
在第2部分和第3部分中,我们将讨论更多内容并开发一段代码。
保持HTML结构,将以下英文文本翻译为简体中文: ===============================================================
请随时通过 LinkedIn 与我联系:https://www.linkedin.com/in/tushitdave/

保留HTML结构,将以下英文文本翻译成简体中文: ============================================================ Hello, my name is John. How are you today? I hope you are doing well. Let's have a great day!
参考文献:
- BERT得分
- 深度学习.ai








