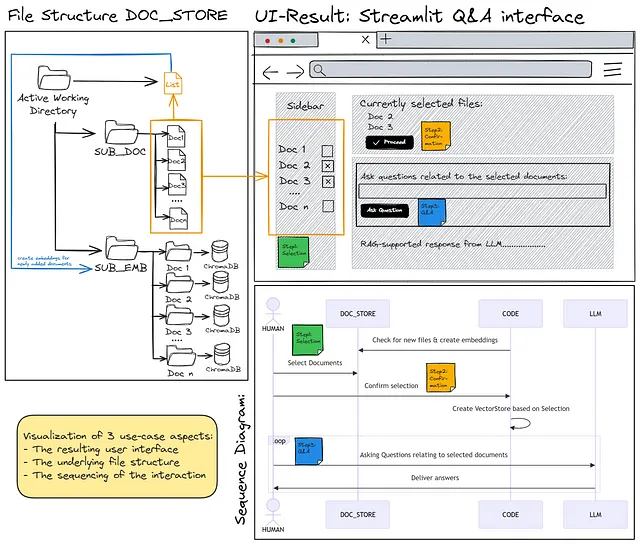
掌握上下文提取,用于微调GPT模型
从OpenWebText数据中提取领域特定的上下文

生成预训练变形器(GPT)模型是用于自然语言处理任务的大型语言模型。GPT模型通过对各种文本数据进行训练而开发出来。通过从广泛的文本数据中学习,GPT模型能够根据提示中提供的术语生成与上下文相关的内容。这些模型能够通过称为变形器的架构来实现这些自然语言任务。变形器架构使GPT模型能够在给定一个词或词组的序列中识别和加权重要的关键词。这些模型能够可靠地理解语法结构、语义和整体语言模式。
GPT模型的应用
GPT模型在各个行业中有着广泛的应用,这些应用的数量太多,无法在一篇文章中总结。建立在GPT模型之上的最流行应用是ChatGPT,该应用由OpenAI在2022年发布。自发布以来,ChatGPT迅速发展成为一个现代化的搜索引擎,拥有超过1.8亿活跃用户。仅在过去的十月份,ChatGPT就记录了17亿次访问量。由于ChatGPT作为一个搜索引擎,它的用途非常广泛。包括文档摘要、查找知名文档概念、生成代码等等。
目前,OpenAI有公开可用的GPT 3.5版本和付费版本GPT-4。公开版本可以免费使用,付费版本每月订阅价格为20美元。付费版本是多模式的,更准确。具体而言,您可以通过输入基于文本的提示或直接向工具发声来生成文本、图像或音频输出!
鉴于ChatGPT的极大成功,许多公司已表示强烈兴趣开发针对特定行业的ChatGPT版本。这是通过使用特定于行业的基于文本的数据对基础GPT模型进行微调,并将微调后的模型部署到应用程序中来实现的。例如,许多金融机构要么重新训练,要么对金融专业知识库中的GPT模型进行微调。这是一种有用的方式,可以更新与其业务用例相关的金融专用术语的权重。一个具体的例子是通过对金融新闻数据对GPT模型进行微调,以提高编写财务报告所生成输出的质量。
有几个公共数据选项可用于调整GPT模型以适用于特定行业的用例。建立GPT的最知名的公共数据来源之一是OpenWebText数据库。
什么是OpenWebText?
OpenWebtext是OpenAI开放源代码版本的webtext语料库。它包含从Reddit获取的网络数据,其中优先考虑高质量的文本。具体来说,OpenAI使用Reddit上至少具有3个Karma值的提交作为评估质量的启发法。该数据是通过从Reddit提交数据集中提取URL生成的。
Openwebtext数据已被广泛用于各种研究和行业应用。这些应用包括发展预训练的LLM模型,生成特定行业内容,语言翻译,实体命名识别,文本摘要等等。
访问OpenWebText数据
您可以通过访问OpenWebTextCorpus网站来访问数据集。在下载12GB压缩的.tar文件后,您可以使用以下命令提取文件:
tar -xf path/to/files/openwebtext.tar.xz - C path/to/files/
这将导致一个名为OpenWebText的目录,并且其中包含.XZ文件。
如果我们进入其中一些文件,我们可以看到以下内容:
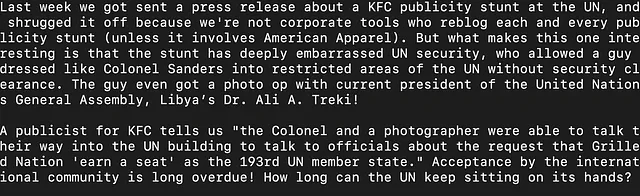

我们还可以提取包含特定关键词的文本。这对于像GPTs这样的任务非常有用。您可以轻松编写一个Python脚本,遍历这些.xz文件,提取与关键词相关的上下文,并将上下文写入一个.txt文件。让我们提取与关键词“财务”相关的上下文。下面是结果.txt文件的快照:
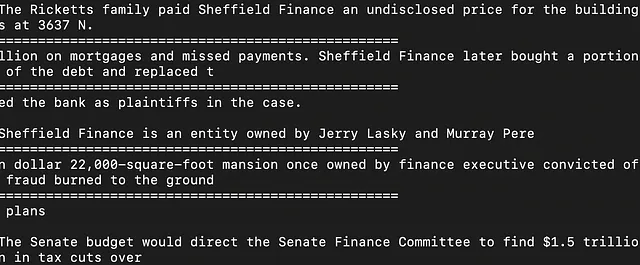
这个文件包含与金融相关的相对广泛的文本信息。通过包含更多具体的关键词或更具体的关键词,可以进一步细化。例如,您可以尝试提取与“股票市场”相关的内容。
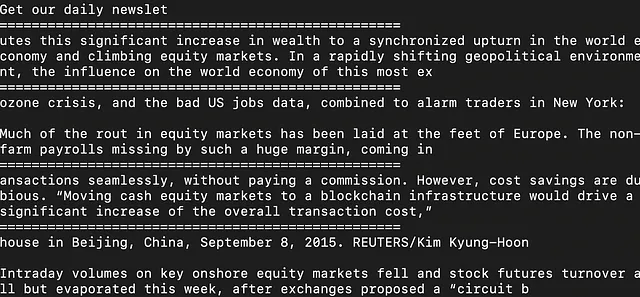
这可以用来微调用于生成股票市场新闻情绪得分的GPT模型。这可以作为交易员、投资者和金融分析师的决策支持。具体来说,情绪得分可以用于帮助关于股票情绪相关性的决策过程。
另一个例子是“固定收益”。让我们提取一些与“固定收益”相关的上下文。

这个上下文可以用来微调一个GPT模型,根据用户的个人资料和财务目标生成固定收益投资建议。
在DataFabrica可以找到用于提取与关键词相关上下文的脚本。您可以在这里访问该脚本。
结论
在这篇文章中,我们讨论了如何利用公共数据源OpenWebText来生成特定领域的上下文,以便用于改进LLMs的微调。我们首先讨论了如何通过OpenWebText网站访问数据。然后我们展示了如何解压下载的.tar文件并提取.xz文件。最后,我们讨论了一些上下文相关的文本以及如何利用它们来改善GPT模型的输出。您可以在这里访问上下文提取脚本。