一个灵活的问答聊天应用,使用langchain、Streamlit和chatGPT来选择您的文档。
为什么你应该阅读这篇文章:
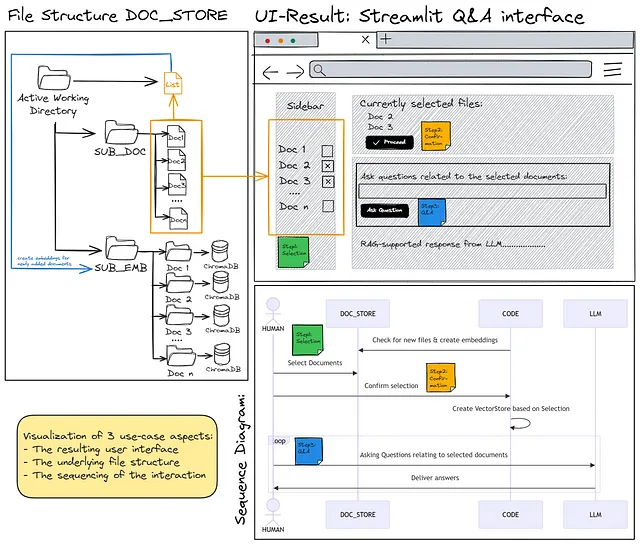
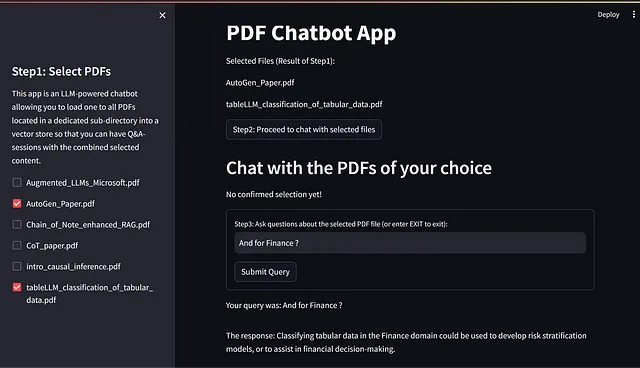
只需两个图片:如果您想要实现一个类似上图的解决方案架构,并且拥有下图所示的界面,可以灵活地从给定的文档集合中查询您选择的一个或多个文档的内容。
而且,如果您在您的集合中使用较大的文档,不断为每次使用重新创建嵌入会让您的时间和财务预算受到影响,所以您应该阅读它。
最后:如果你想看到一个使用Langchain、Streamlit和openAI-API实现这一目标的实际示例。
动机与用例
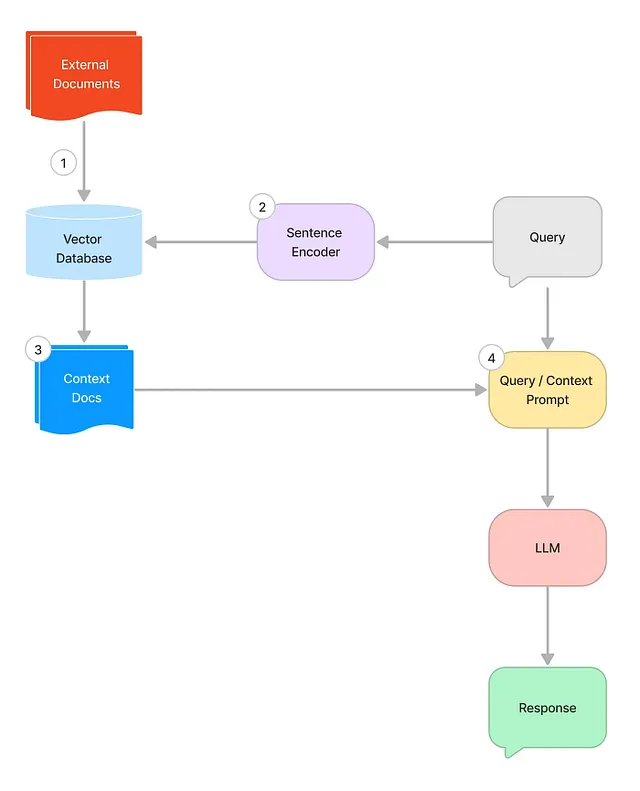
在Medium和其他地方已经有很多文章,解释了“如何与你自己的文档进行聊天”,从而克服了LLM的“一般性问题”,通过在提问时向LLM的上下文窗口输入附加和特定的信息。这些相关信息是从一个(向量)数据库中检索出来的,该数据库包含具有LLM尚未拥有的特定信息的文档的嵌入,并且基于一个相似性搜索,返回承诺持有最相关信息以回答手头问题的文本块。
我从几个来源获得启发,其中最重要的我将稍后提及一点。但对于那些对这个主题真正陌生的人来说,在这里有一个很好的流程图,解释了所谓的RAG过程(检索增强生成)的基本要素,也就是用户查询如何通过从一个单独的知识库中获得的附加上下文信息来加强。
但是,当仔细观察所有提出的解决方案时,我发现了一些重要的缺点(我稍后会解释),这使它们不适用于我所考虑的所有实际用例。因此,我决定更深入地研究并找出是否能提出满足我自己需求的解决方案(剧透:成功了!)
现有解决方案的不足之处
为什么还需要另一篇关于“与您的文档聊天”的文章?我在Medium和其他地方看到的所有“快速”解决方案都有相似的缺点: - 要么它们只能用于一个文档……要么用于多个文档。但是没有一种解决方案能够灵活地选择文档(除了可能复制并粘贴所需文档到文件夹中)。 - 几乎所有的解决方案都需要每次运行代码时重新运行文档嵌入,这样会浪费您的时间和金钱。而那些建议仅一次存储现有嵌入的解决方案只能一次存储一个(也就是说,它是一种“要么这样要么那样”的方法,不能同时检索和查询多个文档的嵌入)。 - 要么它们向您展示了一个真实的聊天——但不是在Streamlit这样的GUI中。要么它们向您展示了一个简单的问答。关于这些原因,下面的“经验教训”中有详细的解释。
为什么这很重要?我有过这样的情况,我收集特定主题的PDF文件,但并非所有文件在寻找特定问题的答案时都具有相同的相关性。让我举两个例子:- 地方政治:你有一系列议程、议定书、决策备忘录、党纲等文件。如果你在寻找特定决策,只需查询议程或者更好的是会议议定书,就足够找到你要找的内容了。包含党纲或非常具体的备忘录是没有必要的。然而,如果你想深入研究一个非常具体的主题,包括所有议程和议定书可能没有帮助,搜索应该仅限于与该特定问题相关的备忘录,其中包含你想要的详细信息。- AI研究:如果你尝试跟上人工智能领域的最新进展(如果可能的话),你可能只有一个许多研究论文的资源库。涵盖广泛的主题当然是好的。但是,如果你想从这个集合中找到特定的问题答案,为什么不直接深入到最相关的论文呢?例如,如果你想了解更多关于代理人或Chain-Of-xxxx技术的知识,为什么不仅仅选择那些根据名称已经专注于你的主题的论文呢?
旅程就是目的地
如果您只对结果感兴趣,请直接跳到“代码”部分。
因为我不是一个程序员,但我对不同形式和规模的人工智能潜力着迷,解决问题的过程对我来说与结果同样重要。我只是对编程的细节以及人工智能及其不断发展的技术栈有很多学习。而且由于我从别人分享他们的发现经验中获益良多,我觉得回馈一些这种经验分享是个好主意。
灵感
对于这篇文章来自Medium上的几篇文章,特别是:https://towardsdatascience.com/4-ways-of-question-answering-in-langchain-188c6707cc5a https://ibrahimsaidi.com.au/question-answering-over-your-pdf-files-in-langchain-1d0c85e65aa5 https://medium.com/@onkarmishra/using-langchain-for-question-answering-on-own-data-3af0a82789edhttps://medium.com/international-school-of-ai-data-science/efficient-information-retrieval-with-rag-workflow-afdfc2619171
点击此处查看此YouTube视频,并查看使用Eightify制作的转录文本(链接:点击此处)。您可以在Pastebin上找到相关代码(链接:点击此处)。
学习
除了纯粹的编码结果之外,我从这个案例研究中学到了以下几个方面的知识,并希望与读者们分享,对他们可能会有所帮助。
学习使用集成开发环境(IDE)
我不得不学习使用真正的集成开发环境(选择了PyCharm)来工作。直到现在,我一直使用Jupyter Notebooks或者Lab进行工作。Jupyter真的非常棒和直观 - 但是在应用人工智能和通过LLM提供者的API进行流式传输时,这个概念会遇到问题。如果您想添加自己的图形用户界面,那就完全没戏了。我曾经在玩autoGen和BabyAGI时早先就碰到这个问题 - 不得不学习到在本地应用程序和LLM之间的交互底层和“官方”输出之间有很大的区别。如果您想同时跟踪这两方面,使用集成开发环境开发和运行代码似乎是更好的解决方案。
一个有代价的解决方案:更高的复杂性!对于新手编码者来说,找到正确的设置和按钮来产生所需的结果并不是一件容易的事情。与此相比,Jupyter通过简单的逐步执行和即时反馈真正友好于初学者。一个很好的例子是花费了相当长的时间来制作简单的环境变量工作清单:我不想让我的 API 密钥出现在代码中。在理论上很简单,可以从环境变量中加载它,但在实际操作中,我遇到了很多奇怪的问题。最后,安装了一个 PyCharm 插件解决了这个问题,但我更愿意将时间花在更多与人工智能相关的问题上。
领域的发展速度非常快
另一个了解是亲身经历了行业发展的迅速。根据几个月前的代码示例采用了一些方法,我发现有些包中参数的定义或数据类型已经发生了重要变化,导致与它们需要配合工作的其他包不兼容。官方文档也没有提供太多帮助,大多数文档要么是幼稚简单的入门指南,让使用某个包看起来简单到欺骗人,要么是超技术的API和对象定义,很难理解。
简而言之:

为了克服这些困难,AI-support和stackoverflow都非常有帮助。我不得不说,stackoverflow似乎仍然是更可靠的来源(考虑到条目的发布日期!)。在AI方面,我经历了真正的“代码幻觉”,AI建议的代码使用的方法在给定的软件包中根本不存在(……但乍一看似乎完全合理)。
一個很好的不相容性例子是Chroma套件(用於程式碼的向量資料庫):我花了很長時間才發現該套件與在langchain中實現的openAI-API在某個版本號過後變得不相容...這使我有機會學習如何在IDE中重新安裝舊的套件版本(...上面提到的)。拯救我免於絕望的信息來自stackoverflow上的一行回應。
学习:FAISS vs. Chroma
选择一个特定的向量数据库来存储本地文档的嵌入(即它们的翻译成LLM的向量语言)是一个非常重要的步骤。我阅读的大部分文章都选择了两个开源的替代方案之一:FAISS(来自 meta)或 Chroma。我主要受到启发的那篇文章使用了FAISS。这篇文章让我感到主要是因为嵌入被保存在pickle文件中以便复用。然而,该示例只能同时处理一个文件进行聊天。我曾经试图找到一种方法将多个pickle文件提供给FAISS,以创建一个仅包含某些选定文件的嵌入的向量数据库,并将它们之前创建的嵌入作为pickle文件保存到磁盘上,但是却徒劳无功。
所以我尝试了Chroma。并且这也花了一些时间,但是,再次感谢stackoverflow上一个非常简洁的答案,我找到了使其工作的代码。这是我为解决方案设想中的架构实现过程中的一个非常重要的步骤(即:一个子目录,将嵌入保存到向量数据库中,用于根据用户文件选择进行实际查询)。
另一个所学之处是,默认情况下,Chroma仅创建一个内存中的向量存储,并且必须明确地将信息写入磁盘以进行后续重用。这个数据库是始终以同一名称写入到创建持久性数据库时指定的目录中。由于代码的目标是仅从当前选择的文件的嵌入中“组装”搜索向量数据库,这意味着需要创建大量的子目录(每个知识库中的文件1个),如构架可视化中所示。
学习:Gradio与Streamlit(以及其无状态概念)
对于Python初学者友好的GUI,似乎有两个基本选择,即gradio或Streamlit。我选择了Streamlit,因为它在整体上看起来更简单。但是在这里,我不得不了解到简单性也是有代价的。而且为什么我从另一篇文章中获得灵感时,只使用了简单的Langchain Q&A链:Streamlit本身是无状态的,只是不断重新运行同一段代码。这意味着它不会记住任何聊天历史记录。

简单的公式是,与文件聊天基本上就是一个带有附加记忆的问答,没有记忆的话,这种方法很难运作良好。因此,这里的学习重点是如何将显式状态集成到我在该主题上找到的示例代码中。
学习:分裂的兔子洞
在整个RAG过程中,一个非常重要的方面是如何将自己文档中的信息拆分并存入向量数据库。在代码中,我选择了一个简单直接的解决方案(使用固定块长度和重叠的递归字符文本拆分器)。特别是对于PDF文档,我认为改进“拆块”文档的方式是提高效能的最大杠杆,同时保留文档结构中的重要语义信息(例如通过标题或标题层次结构)。我希望在不久的将来能够研究这个问题,但为了使额外的努力值得,这种方法需要相似结构的文档。因此,这个问题是否能够成为议程的重点,要视我的用例是否涉及多样化的来源而定。
这个主题的一个很好的入门是这篇文章:https://medium.com/@chatdocai/revolutionizing-rag-with-enhanced-pdf-structure-recognition-22227af87442
代码
基本方法解释
我用建筑基础作为代码的图像进行重复,因为一张图片胜过千言万语。
PDF的知识库存储在一个子目录中。在代码中,PDF文件类型可以通过更改变量EXT(扩展名)来轻松更改为其他文件类型,如.txt或.docx。然而,在这种情况下,用于创建“文本”变量的代码部分必须根据新的文件类型进行适应。
同时,以一份.txt文件的形式在工作目录中保留了一个包含文件名的列表。在应用程序启动时,会遍历子目录以获取文件名,并识别出可能已添加的文件。只有对于这些新文件,才需要创建其内容的嵌入,并存储在进一步的子目录中(每个文件一个子目录),即SUB_EMB子目录中。
当用户通过点击按钮确认文件选择时,实际的主要代码将被执行:从所选文件的嵌入中创建一个向量数据库,构建用户界面并执行语言链 "ConversationalRetrievalChain",使用户能够 "与所选文件开始聊天"。
实际的代码
导入所需的包:
from PyPDF2 import PdfReader
import os
import streamlit as st
from dotenv import load_dotenv
from streamlit_extras.add_vertical_space import add_vertical_space
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.callbacks import get_openai_callback
from langchain.schema import Document
定义变量(例如基于所需的目录结构和知识库文档的文件类型),并初始化openAI-API,用于嵌入和查询。
# DEFINE VARIABLES
# Change these to match your specific directory and file extension
SUB_EXT = 'SUB_PDF'
SUB_EMB = 'SUB_EMB'
EXT = '.pdf'
EMB_EXT = '.pkl'
FILE_LIST = 'file_name_list.txt'
#_________________________________________
# Initialize openAI llm and embeddings:
load_dotenv() # requires .env-file containing the openAI key
openai_api_key = os.getenv("OPENAI_API_KEY")
if openai_api_key:
llm = OpenAI(openai_api_key=openai_api_key)
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Use llm in your Streamlit app
else:
st.error("OpenAI API key is not set. Please set the OPENAI_API_KEY environment variable.")
定义各种辅助函数。第一个函数帮助文件解析,与现有的嵌入基础列表进行比较,最后创建新文档的嵌入。
def f_scan_directory_for_ext(directory, extension):
return [f for f in os.listdir(directory) if f.endswith(extension)]
def f_get_existing_files(file_name_list):
with open(file_name_list, 'r') as file:
return set(file.read().splitlines())
def f_update_file_list(file_name_list, new_files):
with open(file_name_list, 'a') as file:
for new_file in new_files:
file.write(new_file + '\n')
def f_create_embedding(new_file_trunk, new_file_pdf_path, file_persistent_dir_path):
print(f"Creating embedding for {file_persistent_dir_path}")
pdf_reader = PdfReader(new_file_pdf_path)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len)
chunks = text_splitter.split_text(text=text)
# workaround to stupid bug ?!? -> https://github.com/langchain-ai/langchain/issues/2877
new_chunks = [Document(page_content=chunk) for chunk in chunks]
db = Chroma.from_documents(
documents=new_chunks, embedding=embeddings, persist_directory=file_persistent_dir_path)
db.persist()
f_create_embedding是通过使用更复杂的文本分割技术来保留语义信息,从而实现潜在更好的聊天结果的入口点。
最后,在接下来的步骤中,定义MAIN函数,基本上是构建Streamlit GUI和执行langchain代码,从而启动用户、知识库和chatGPT 3.5(作为选择的LLM)之间的聊天,直到用户输入“EXIT”作为停止词。
以下是在下面的代码中值得一提的细节: - DB_final._collection.add()方法:这是Chroma方法,允许“粘合”一个可变数量的已存在的嵌入。 - streamlit中的st.session_state()方法,它帮助克服了其通常无状态方法的完全失忆问题;st.session_state()被用于控制按钮和聊天历史记录的状态。如果没有封装在该变量中的先前步骤的记忆,只能实现单个问题和回答对以及无法进行真正的与所选文档的对话。 - 有两个细节没有返回/显示在Streamlit GUI中,而是打印到终端,因为它们不是面向最终用户的,而是用于控制目的:get_openai_callback()调用的结果打印了令牌数量和价格到终端,以及正在进行的聊天的完整聊天历史记录,以便可以保存为文档目的。
def main():
# Initialize the Streamlit app
st.title('PDF Chatbot App')
# Step 4: Create a Streamlit sidebar with checkboxes
with st.sidebar:
st.title('Step1: Select PDFs')
st.markdown('''
This app is an LLM-powered chatbot allowing
you to load one to all PDFs located in a
dedicated sub-directory into a vector store
so that you can have Q&A-sessions with the
combined selected content.
''')
add_vertical_space(0)
selected_files = []
for file in files_in_directory:
if st.sidebar.checkbox(file, key=file):
selected_files.append(file)
# Display selected files or perform actions based on selection
st.write('Selected Files (Result of Step1):')
for file in selected_files:
st.write(file)
l_db_pathes_to_load =["No confirmed selection yet!"]
# Button to signal the end of the selection process
if st.button('Step2: Proceed to chat with selected files'):
st.session_state['selected_files'] = selected_files
l_db_pathes_to_load = [os.path.join(SUB_EMB, filename[:-len(EXT)] ) for filename in st.session_state['selected_files']]
for pathname in l_db_pathes_to_load:
st.write(f"Selected: {pathname}")
st.header("Chat with the PDFs of your choice")
# Create a new, empty Chroma object to receive input based on the previous document selection
DB_final = Chroma(embedding_function=embeddings)
#loop to load all chorma embedding databases of selected files from disk to vector store
if l_db_pathes_to_load == ["No confirmed selection yet!"]:
for pathname in l_db_pathes_to_load:
st.write(pathname)
elif len(l_db_pathes_to_load) == 0:
st.write("At least 1 file must be selected")
else:
for db_path in l_db_pathes_to_load:
# Load the embeddings from the existing vector databases
DB_aux = Chroma(persist_directory=db_path, embedding_function=embeddings)
DB_aux_data = DB_aux._collection.get(include=['documents','metadatas','embeddings'])
DB_final._collection.add(
embeddings=DB_aux_data['embeddings'],
metadatas=DB_aux_data['metadatas'],
documents=DB_aux_data['documents'],
ids=DB_aux_data['ids'])
# Accept user questions/query via a button-confirmed form:
with st.form("query_input"):
query = st.text_input("Step3: Ask questions about the selected PDF file (or enter EXIT to exit):")
submit_button = st.form_submit_button("Submit Query")
# Initialize session_state if it doesn't exist
if 'chat_history' not in st.session_state:
st.session_state['chat_history'] = []
if query != "EXIT":
if submit_button:
st.write(f"Your query was: {query}")
retriever = DB_final.as_retriever(search_type="similarity", search_kwargs={"k": 4})
chain = ConversationalRetrievalChain.from_llm(llm, retriever, return_source_documents=True)
with get_openai_callback() as cb:
response = chain({'question': query, 'chat_history': st.session_state['chat_history']})
print(cb)
add_vertical_space(1)
st.write(f"The response: {response['answer']}")
add_vertical_space(1)
# Update chat_history in session_state
chat_tuple = (query, response['answer'])
st.session_state['chat_history'].append(chat_tuple)
else:
st.warning('You chose to exit the chat.')
st.stop()
# Print chat history to terminal (no GUI)
if 'chat_history' not in st.session_state:
pass
else:
p_chat_history = [entry for entry in st.session_state['chat_history']]
for entry in p_chat_history:
print('--------------')
print(entry)
最后是像之前描述的主程序。记住:这是一个Streamlit应用程序,所以您必须运行它。
运行streamlit ..\DocuChatBot.py
在您的终端中,如果您将整个代码保存为此名称的文件,然后Streamlit应用将在您的默认浏览器中启动。
## MAIN PROGRAM
# Step 1: Scan the SUB_EXT directory
files_in_directory = f_scan_directory_for_ext(SUB_EXT, EXT)
# Step 2: Check against the list in file_name_list.txt
known_files = f_get_existing_files(FILE_LIST)
new_files = [f for f in files_in_directory if f not in known_files]
new_files_trunk = [f[:-len(EXT)] for f in new_files ]
# Step 3: Process new files
# Path to the SUB_EMB directory
SUB_EMB_dir = os.path.join(SUB_EMB)
# Iterate over the list of names
for name in new_files_trunk:
# Construct the path to the sub-directory
subdir_path = os.path.join(SUB_EMB_dir, name)
# Check if the sub-directory exists
if not os.path.exists(subdir_path):
# If not, create it
os.makedirs(subdir_path)
for new_file in new_files:
new_file_trunk = new_file[:-len(EXT)]
#f_create_embedding(new_file_trunk, os.path.join(SUB_EXT, new_file), os.path.join(os.getcwd(), SUB_EMB, new_file_trunk))
f_create_embedding(new_file_trunk, os.path.join(SUB_EXT, new_file), os.path.join(SUB_EMB, new_file_trunk))
f_update_file_list(FILE_LIST, new_files)
# Step 4: call main function that contains all the rest
if __name__ == '__main__':
main()
结束语
展望与改进
如前所述,对于进一步改进或优化此代码及其结果而言,从知识库文件中分块文本的文本分割技术是一个很好的起点。在将这些分块的嵌入保存到向量数据库之前,这种"智能分割"方面的目标是尽可能地保留原始文档中的语义信息,似乎正在迅速发展成为一门学问。
然而,充分利用Langchain的可比性和替换链中的一个LLM以及尝试使用MISTRAL替代openAI的chatGPT作为聊天的基础LLM可能也是有趣的。这对我来说可能是下一步要采取的行动,因为我很好奇尝试与“openAI黄金标准”以外的另一个API一起工作的感觉如何。
喜欢你所阅读的吗?
….如果你喜欢的话,欢迎给我点赞或留言!
整个代码一次完成
当使用Jupyter和笔记本时,我将一份副本留在GitHub上,以配合以前的文章。在切换到PyCharm后,我可能只需在这里方便地保留整个代码的转储。
from PyPDF2 import PdfReader
import os
import streamlit as st
from dotenv import load_dotenv
from streamlit_extras.add_vertical_space import add_vertical_space
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import OpenAI
from langchain.chains import ConversationalRetrievalChain
from langchain.callbacks import get_openai_callback
from langchain.schema import Document
##########################################################################
## DEFINE VARIABLES
# Change these to match your specific directory and file extension
SUB_EXT = 'SUB_PDF'
SUB_EMB = 'SUB_EMB'
EXT = '.pdf'
EMB_EXT = '.pkl'
FILE_LIST = 'file_name_list.txt'
#_________________________________________
# Initialize openAI llm and embeddings:
load_dotenv()
openai_api_key = os.getenv("OPENAI_API_KEY")
if openai_api_key:
llm = OpenAI(openai_api_key=openai_api_key)
embeddings = OpenAIEmbeddings(openai_api_key=openai_api_key)
# Use llm in your Streamlit app
else:
st.error("OpenAI API key is not set. Please set the OPENAI_API_KEY environment variable.")
##########################################################################
## DEFINE FUNCTIONS
def f_scan_directory_for_ext(directory, extension):
return [f for f in os.listdir(directory) if f.endswith(extension)]
def f_get_existing_files(file_name_list):
with open(file_name_list, 'r') as file:
return set(file.read().splitlines())
def f_update_file_list(file_name_list, new_files):
with open(file_name_list, 'a') as file:
for new_file in new_files:
file.write(new_file + '\n')
def f_create_embedding(new_file_trunk, new_file_pdf_path, file_persistent_dir_path):
# Dummy function - replace with actual embedding logic
print(f"Creating embedding for {file_persistent_dir_path}")
pdf_reader = PdfReader(new_file_pdf_path)
text = ""
for page in pdf_reader.pages:
text += page.extract_text()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len)
chunks = text_splitter.split_text(text=text)
# workaround to stupid bug ?!? -> https://github.com/langchain-ai/langchain/issues/2877
new_chunks = [Document(page_content=chunk) for chunk in chunks]
db = Chroma.from_documents(
documents=new_chunks, embedding=embeddings, persist_directory=file_persistent_dir_path)
db.persist()
def main():
# Initialize the Streamlit app
st.title('PDF Chatbot App')
# Step 4: Create a Streamlit sidebar with checkboxes
with st.sidebar:
st.title('Step1: Select PDFs')
st.markdown('''
This app is an LLM-powered chatbot allowing
you to load one to all PDFs located in a
dedicated sub-directory into a vector store
so that you can have Q&A-sessions with the
combined selected content.
''')
add_vertical_space(0)
selected_files = []
for file in files_in_directory:
if st.sidebar.checkbox(file, key=file):
selected_files.append(file)
# Display selected files or perform actions based on selection
st.write('Selected Files (Result of Step1):')
for file in selected_files:
st.write(file)
l_db_pathes_to_load =["No confirmed selection yet!"]
# Button to signal the end of the selection process
if st.button('Step2: Proceed to chat with selected files'):
st.session_state['selected_files'] = selected_files
l_db_pathes_to_load = [os.path.join(SUB_EMB, filename[:-len(EXT)] ) for filename in st.session_state['selected_files']]
for pathname in l_db_pathes_to_load:
st.write(f"Selected: {pathname}")
st.header("Chat with the PDFs of your choice")
# Create a new, empty Chroma object to receive input based on the previous document selection
DB_final = Chroma(embedding_function=embeddings)
#loop to load all chorma embedding databases of selected files from disk to vector store
if l_db_pathes_to_load == ["No confirmed selection yet!"]:
for pathname in l_db_pathes_to_load:
st.write(pathname)
elif len(l_db_pathes_to_load) == 0:
st.write("At least 1 file must be selected")
else:
for db_path in l_db_pathes_to_load:
# Load the embeddings from the existing vector databases
DB_aux = Chroma(persist_directory=db_path, embedding_function=embeddings)
DB_aux_data = DB_aux._collection.get(include=['documents','metadatas','embeddings'])
DB_final._collection.add(
embeddings=DB_aux_data['embeddings'],
metadatas=DB_aux_data['metadatas'],
documents=DB_aux_data['documents'],
ids=DB_aux_data['ids'])
# Accept user questions/query via a button-confirmed form:
with st.form("query_input"):
query = st.text_input("Step3: Ask questions about the selected PDF file (or enter EXIT to exit):")
submit_button = st.form_submit_button("Submit Query")
# Initialize session_state if it doesn't exist
if 'chat_history' not in st.session_state:
st.session_state['chat_history'] = []
if query != "EXIT":
if submit_button:
st.write(f"Your query was: {query}")
retriever = DB_final.as_retriever(search_type="similarity", search_kwargs={"k": 4})
chain = ConversationalRetrievalChain.from_llm(llm, retriever, return_source_documents=True)
with get_openai_callback() as cb:
response = chain({'question': query, 'chat_history': st.session_state['chat_history']})
print(cb)
add_vertical_space(1)
st.write(f"The response: {response['answer']}")
add_vertical_space(1)
# Update chat_history in session_state
chat_tuple = (query, response['answer'])
st.session_state['chat_history'].append(chat_tuple)
else:
st.warning('You chose to exit the chat.')
st.stop()
# Print chat history to terminal (no GUI)
if 'chat_history' not in st.session_state:
pass
else:
p_chat_history = [entry for entry in st.session_state['chat_history']]
for entry in p_chat_history:
print('--------------')
print(entry)
##########################################################################
## MAIN PROGRAM
# Step 1: Scan the SUB_EXT directory
files_in_directory = f_scan_directory_for_ext(SUB_EXT, EXT)
# Step 2: Check against the list in file_name_list.txt
known_files = f_get_existing_files(FILE_LIST)
new_files = [f for f in files_in_directory if f not in known_files]
new_files_trunk = [f[:-len(EXT)] for f in new_files ]
# Step 3: Process new files
# Path to the SUB_EMB directory
SUB_EMB_dir = os.path.join(SUB_EMB)
# Iterate over the list of names
for name in new_files_trunk:
# Construct the path to the sub-directory
subdir_path = os.path.join(SUB_EMB_dir, name)
# Check if the sub-directory exists
if not os.path.exists(subdir_path):
# If not, create it
os.makedirs(subdir_path)
for new_file in new_files:
new_file_trunk = new_file[:-len(EXT)]
#f_create_embedding(new_file_trunk, os.path.join(SUB_EXT, new_file), os.path.join(os.getcwd(), SUB_EMB, new_file_trunk))
f_create_embedding(new_file_trunk, os.path.join(SUB_EXT, new_file), os.path.join(SUB_EMB, new_file_trunk))
f_update_file_list(FILE_LIST, new_files)
# Step 4: call main function that contains all the rest
if __name__ == '__main__':
main()