与您的YouTube视频聊天
RAG和语义搜索的力量
简介
2023年无可否认是人工智能的一年,许多模型和相应的应用程序成为了头条新闻。一个受到重视的话题是RAG,即检索增强生成。在本文中,我们将探讨RAG是什么以及如何使用它与YouTube视频进行互动,为用户创造更具活力和信息丰富的体验。
什么是RAG?
RAG(检索增强生成)是 Retrieval Augmented Generation 的缩写。RAG 的核心理念是让 AI 能够利用自己的数据集回答问题。当你向普通的聊天机器人提问时,它会试图根据自己所学习的内容进行回答。然而,这些回答可能不总是准确或全面的,因为 AI 可能缺乏某个特定主题的必要信息。RAG 通过允许你通过提示方式提供 AI 参考来源来解决这个限制,帮助 AI 生成更具见解的答案。
嵌入
虽然向AI提供源数据的概念很简单,但在处理庞大的数据集时,会面临一些挑战。想象一下,你对一本书的内容有一个问题,你希望将整本书作为你的资源来回答。这就是第一个问题出现的地方,因为这些模型一次只能处理一定长度的上下文。为了解决这个问题,你需要向AI呈现源数据的相关段落。这种方法涉及以下步骤:
- 识别源资料中的相关段落。
- 将这些段落包含在提示中。
- 指示AI根据这些文章回答问题。
然而,找到正确的段落可能具有挑战性,因为用户的问题不一定包含您要搜索的关键词。这就是嵌入模型发挥作用的地方。嵌入将文本的意义编码为向量。为了实现这一点,您必须将整本书分割成文本段落,计算这些段落的嵌入,并将它们存储在向量数据库中。当您有一个问题并想要找到相关段落时,您可以为该问题计算嵌入,并使用结果向量在数据库中搜索类似的向量。一旦您有了类似的向量,您也就有了与该问题相关的相应段落。这是关于RAG、语义搜索和嵌入的简化解释。
使用RAG和YouTube视频
现在,让我们深入探讨一下如何应用这种方法来通过提出与视频内容相关的问题与YouTube视频互动。
- 创建视频的文字记录,包括时间戳。
- 将文本转录分成有意义的片段(使用最大词阈值)。
- 计算这些片段的嵌入并将它们存储在向量数据库中。
- 接收用户的问题并计算其嵌入。
- 利用问题的嵌入来在数据库中搜索相关的片段(转录部分)。
- 利用人工智能根据转录部分回答问题。
- 使用时间戳来导航到相应的视频部分。
使用Streamlit实现
整个代码可以在GitHub上找到:https://github.com/sabania/ChatWithYoutube.git
在这里,我们将按照上面列出的要点,逐一阐述重要的段落。
提供的代码片段是创建YouTube视频的转录的一部分,包括时间戳。让我们逐步分解代码:
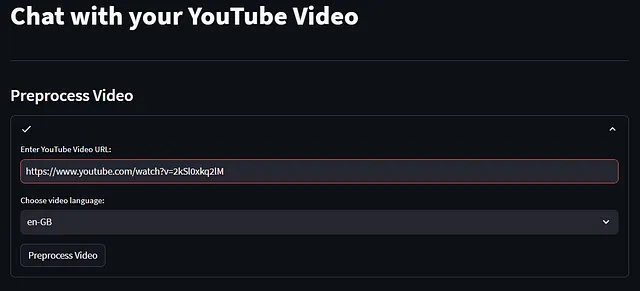
- 检查YouTube URL并提取视频ID该代码首先检查是否提供了URL。如果存在URL,则继续使用extract_video_id函数提取视频ID。如果未找到视频ID,则显示错误消息。
def extract_video_id(url):
regex = r"(?<=v=)[^&#]+"
match = re.search(regex, url)
return match.group(0) if match else None
with st.status("", expanded=st.session_state.expanded_preprocessing) as status:
url = st.text_input("Enter YouTube Video URL:")
if url:
video_id = extract_video_id(url)
if not video_id:
st.error("Invalid YouTube URL!")
elseelse:
try:
transcript_list = YouTubeTranscriptApi.list_transcripts(video_id)
available_transcripts = {
transcript.language_code: transcript for transcript in transcript_list
}
selected_language = st.selectbox(
"Choose video language:",
list(available_transcripts.keys())
)
# function used to create and dictonary with medat data for each transcript part
# we have here the video id, the langauge of the tanscript, the url and
# start and end end time
# all the meta data are passed to the Document object before its embeddings
# are calculted. Whenever we retrieve a relevant document we have all the
# required metadata which are required to get the corresponding video segment.
def create_metadata(transcript, start_time=None, end_time=None):
metadata = {
'video_id': transcript.video_id,
'language': transcript.language,
'language_code': transcript.language_code,
'video_url': f"https://www.youtube.com/watch?v={transcript.video_id}",
'start': start_time,
'end': end_time
}
return metadata
# Function used to fetch the transcript text
# and split into parts (based on word_limit)
def split_transcript(transcript, word_limit):
# Fetch the transcript text for the video
transcript_text = transcript.fetch()
parts = []
current_content = []
current_word_count = 0
start_time = None
for entry in transcript_text:
# Split the transcript entries into words
words = entry['text'].split()
# Calculate the word count of the entries we have already added to the current part
new_word_count = current_word_count + len(words)
if start_time is None:
start_time = entry['start']
if new_word_count < word_limit:
# Add the entry to the current part if it doesn't exceed the word limit
current_content.append(f"\n+{entry['start']} + \t{entry['text'].strip()}")
current_word_count = new_word_count
else:
end_time = entry['start']
# Create metadata for the current part using start and end times
metadata = create_metadata(transcript, start_time, end_time)
# Create a Document with the concatenated content and metadata
parts.append(Document(page_content=''.join(current_content), metadata=metadata))
# Reset the current content and word count for the new part
current_content = [f"\\n+{entry['start']} + \t{entry['text'].strip()}"]
current_word_count = len(words)
start_time = entry['start']
if current_content:
# Handle any remaining content at the end of the transcript
end_time = transcript_text[-1]['start']
metadata = create_metadata(transcript, start_time, end_time)
parts.append(Document(page_content=''.join(current_content), metadata=metadata))
return parts
# When the "Preprocess Video" button is clicked
if st.button("Preprocess Video"):
# Update the status to indicate that processing is ongoing
status.update(label="Processing...", state="running", expanded=True)
# Fetch the selected transcript based on the chosen language
transcript = available_transcripts[selected_language]
# Store the transcript in the session state for later use
st.session_state.transcript = transcript
# Split the transcript into smaller parts with a word limit of 100
st.session_state.transcript_parts = split_transcript(transcript, 100)
# Initialize embeddings using the OpenAIEmbeddings class and the OpenAI API key
embeddings = OpenAIEmbeddings(openai_api_key=openai_key)
# Create a vector store (FAISS index) from the transcript parts using the embeddings
st.session_state.vector_store = FAISS.from_documents(st.session_state.transcript_parts, embeddings)
# Update the status to indicate that processing is completed and users can start chatting with the video
status.update(label="Processing completed! You can start chatting with the video!", state="complete", expanded=False)
# Set the preprocessing expansion to False to hide the preprocessing section
st.session_state.expanded_preprocessing = False
现在,我们成功地准备了视频的转写并建立了一个强大的视频互动系统的基础,现在是时候进入行动的核心了——聊天界面。用户可以通过提问与视频内容互动,我们的人工智能驱动系统会以有益的回答进行回应。让我们来详细分析一下我们的聊天界面的组件和功能:
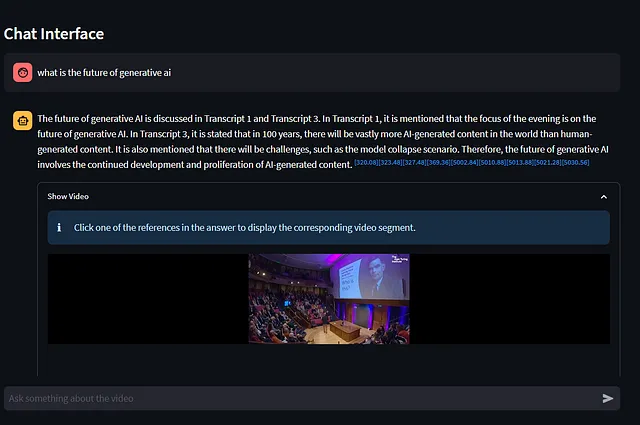
- 检查现有的向量存储:我们首先检查会话状态中是否存在向量存储。向量存储包含分段转录部分的嵌入,这对于语义搜索至关重要。
- 创建聊天区域:如果我们有向量存储器,我们将创建一个专门的聊天区域。这是魔法发生的地方,用户可以与视频内容互动。
- 聊天历史和用户输入:我们提供一个聊天历史视图,以显示之前的互动。用户可以查看正在进行的对话。如果聊天历史不为空,我们提供一个“清除聊天历史”按钮。点击此按钮可以清除聊天历史,使用户可以重新开始。为用户提供了一个聊天输入框,供他们输入他们对视频的问题或评论。
- 处理清除聊天记录:当按下“清除聊天记录”按钮(且聊天记录不为空)时,我们会清除聊天记录,但保留初始系统消息。这样可以确保对话始终从一个干净的起点开始。我们会触发一个实验性的重新运行应用程序,以相应地更新用户界面。
- 用户输入处理: 如果用户在聊天输入框中输入了一条消息或问题,我们将search_required设置为True。这表示我们需要执行一个语义搜索,根据用户的输入查找相关的转录部分。我们监控聊天历史的长度。如果聊天历史中至少有三条消息,我们检查用户的问题是否可以通过我们的AI模型直接回答。如果可以,我们将search_required设置为False,因为不需要进一步搜索。聊天历史和用户输入相应地进行更新。
- 语义搜索:我们使用vector_store执行语义搜索,根据用户的输入查找相关的讲稿片段。如果需要进行搜索,我们将搜索类型设置为“相似度”,并检索前25个结果。否则,我们将使用先前存储的搜索结果。相关的搜索结果将存储在search_result中,这将用于为我们的AI模型提供上下文。
- 与AI模型聊天:我们使用聊天功能与我们的AI模型(模型="gpt-3.5-turbo-16k")进行互动,根据用户的输入和可用的上下文。AI模型生成一个回应,然后将其添加到聊天历史中。我们还从AI模型的回应中提取和解析相关的内容。这些内容包括文本和可能的视频相关信息。解析后的内容将添加到聊天历史视图中。
- 更新用户界面:我们更新了聊天历史记录视图,确保对话实时显示。我们触发一个实验性的重新运行以反映更新后的聊天界面。
# prompt template to check wherther the question can be answered using
# existing info in chat history or new semantic search has to be performed
NEW_SEARCH_REQUIRED_TEMPLATE = '''Question: {question}
Can you answer the question above based on existing information from our conversation? If you can answer it, just say "Yes" or "No" only, no addtioninal output is required and do not answer the question!
Yes or No?:
'''
# Intial templates used when a new converstion starts.
# we injedt the the retrieved documents into prompt along with the user's question
INITIAL_TEMPLATE = """Transcripts:
{source_documents}
------------
Question:
{question}"""
DOCUMENT_TEMPLATE = """Transcript {document_number}:
{document_content}"""
def get_initial_template(source_documents, question):
doc_msg = "\n\n".join([DOCUMENT_TEMPLATE.format(document_number=i+1, document_content=doc.page_content) for i, doc in enumerate(source_documents)])
return INITIAL_TEMPLATE.format(source_documents=doc_msg, question=question)
# Function to parse the chat model's answer for video-related content
def parse_answer(text, video_id):
bracket_contents = re.findall(r'\[[^\]]+\]', text)
vid_content = ''
for content in bracket_contents:
numbers = re.findall(r'\d+\.\d+', content)
if numbers:
# Replace bracketed content with clickable timestamps linked to the video
replacement_text = "".join([
f'<a style="text-decoration: none;" href="https://www.youtube.com/embed/{video_id}?start={int(float(number))}&autoplay=1&mute=1" target="youtube_vid{number}" id="{number}"><sup>[{number}]</sup></a>'
for number in numbers
])
vid_content += "".join([f'<div><iframe width="100%" name="youtube_vid{number}" frameborder="0"></iframe></div>' for number in numbers])
text = text.replace(f'{content}', f'{replacement_text}')
return text, vid_content
# Chat Interface
if 'vector_store' in st.session_state:
# Display a horizontal line to separate the preprocessing section from the chat interface
st.markdown('---')
# Display a subheader to indicate the purpose of this section
st.subheader("Chat Interface")
# Create the chat area and display previous chat history
create_chat_area(st.session_state.chat_history_view)
# Display a "Clear Chat History" button if the chat history is not empty
clear_button = st.button("Clear Chat History") if len(st.session_state.chat_history_view) > 0 else None
# Accept user input in the chat input field
user_input = st.chat_input("Ask something about the video")
if clear_button:
# If the "Clear Chat History" button is pressed
# Clear the chat history while retaining the initial system message
st.session_state.chat_history = [st.session_state.chat_history[0]]
st.session_state.chat_history_view = []
# Trigger an experimental rerun to update the UI
if user_input:
search_required = True
# Determine if a semantic search is required based on the chat history
# If there are more than 3 messages, check if a question can be answered directly
if len(st.session_state.chat_history) >= 3:
search_required_msg = get_new_search_required_template(user_input)
temp_chat_history = st.session_state.chat_history.copy()
temp_chat_history.append({"role": "user", "content": search_required_msg})
# Check if the question can be answered using a chat model
question_can_be_answered = chat(temp_chat_history, 50, model="gpt-3.5-turbo-16k")
# Check if the answer indicates that a search is not required
if question_can_be_answered.lower().find('yes') != -1:
search_required = False
print('IS SEARCH REQUIRED: ', search_required)
# Perform a semantic search if required, else use the previous search result
search_result = st.session_state.vector_store.search(user_input, search_type="similarity", k=25) if search_required else st.session_state.current_search_result
st.session_state.current_search_result = search_result
current_msg_txt = get_initial_template(search_result, user_input)
# Create a version of the message without the search results
current_msg_txt_empt_sarch = get_initial_template([], user_input)
# Create a history with the current search result only for use by the chat model
sending_history = st.session_state.chat_history.copy()
st.session_state.chat_history.append({"role": "user", "content": current_msg_txt_empt_sarch})
st.session_state.chat_history_view.append({"role": "user", "content": user_input})
sending_history.append({"role": "user", "content": current_msg_txt})
print('chat history sending: ', sending_history)
# Engage with the chat model and get a response
gpt_answer = chat(sending_history, 1000, model="gpt-3.5-turbo-16k", temperature=0.0)
# Add the chat model's response to the chat history
st.session_state.chat_history.append({"role": "assistant", "content": gpt_answer})
# Parse the chat model's answer to identify and process video-related content
text, vid_content = parse_answer(gpt_answer, video_id)
# Add the parsed content to the chat history view
st.session_state.chat_history_view.append({"role": "assistant", "content": text, "vid_content": vid_content})
快乐编码!!!