LBPE得分:评估人工智能LLMs的新视角
评估了9个AI模型后,ChatGPT在许多没有常见基准覆盖的领域中表现出色,超过了Gemini和其他模型。Mistral AI正在逐渐接近OpenAI。
较早时,我分享了关于在Gemini Pro中感受到的一种差距:没有支持证据,我们可能会高尚地改变主意,或陷入确认偏见,为我们的信念突出或创造新证据。猜猜我选择了哪条路?LBPE分数:评估我关心的事情上模型表现的基准。

我分析了39个基准和数据集以避免重复造轮子。
- 一般知识:BoolQ,DROP,ENEM,GLUE,LAMBADA,MMLU,NaturalQuestions,SQuAD和SuperGLUE;
- 数学:GSM8K,数学,MathVista,MBPP和MGSM;代码生成和编程:Codeforces,EvalLM,HumanEval和Natural2Code。
- 语言和翻译:BLEU,METEOR,ROUGE,TydiQA,Wikilingua和WMT23;
- 音频和语音理解:CoVoST、FLEURS、多语种Librispeech和VoxPopuli;
- 图像理解:AI2D,ChartQA,DocVQA,Infographic VQA,TextVQA和VQAv2。
- 视频理解:ActivityNet-QA、NextQA、Perception Test MCQA、VATEX和YouCook2。
我重视这些话题,但我想探索新的话题。
方法学
我将为不同主题生成和评估多个提示集。然后,我将根据这些集合中模型的表现来计算每个主题的得分。
GPT-4将创建提示,并为了确保没有重复,我将使用具有shingle标记过滤器的Elasticsearch。GPT-4还将为评估进行评分。我将使用多个插件的Ruby Nano Bots。
此外,我还将重现MMLU和ENEM测试,进行性能和成本方面的比较,并对API进行评估。
详细数据和数学将会公开提供。
模型和提供商
满足LBPE分数的一个基本要求是可重现性和接受挑战的开放性。因此,我将仅包括通过API在全球范围内可用的模型,确保任何具备计算机、互联网和银行卡的人都能够复制这些结果。
以下供应商和型号已被选中:
- 凝聚 指令
- 凝聚指挥光
- Google Gemini Pro 谷歌双子座专业版
- Maritaca MariTalk 麦丽塔卡玛丽聊库
- Mistral Medium (微風中等)
- 迷斯卓小号
- 迷思特尔微型
- OpenAI GPT-4 Turbo OpenAI GPT-4 Turbo是一个使用了最新技术的自然语言处理模型。它由OpenAI公司研发并推出,是GPT系列模型的最新版本。OpenAI GPT-4 Turbo在语言理解和生成方面表现出色,能够产生高质量、流畅的文本。 该模型采用了深度学习和强化学习技术,具备强大的语义理解和上下文分析能力。它通过对大量文本数据进行训练,能够理解和学习多种语言表达方式,包括常见的口语和书面语。 OpenAI GPT-4 Turbo广泛应用于各种领域,例如自动化客户服务、内容创作和语言翻译等。它能够帮助企业提高客户满意度,加快内容创作进度,并且提供快速精准的语言翻译服务。 OpenAI GPT-4 Turbo是一项重要的自然语言处理技术创新,它在实现人机交互、语言深入理解和自动化处理等方面具有巨大潜力。随着技术的进一步发展,OpenAI GPT-4 Turbo将继续提升自身能力,为人们提供更多实用的功能和服务。
- OpenAI GPT-3.5 Turbo 文字版
Google尚未向公众发布Gemini Ultra,并且Anthropic限制了Claude只在某些国家可用;因此,两者都不符合测试要求,需要全球可用性。
尽管Hugging Face上有成千上万种模型,我只考虑了那些具有终端用户HTTP API的模型,而无需Transformers、Python、TensorFlow等。
方法和选定模型已经建立,接下来:这39个现有基准中缺少了什么?
- 来回对话
- 工具(功能)
- 多语能力
- 流媒体
- 延迟
- 定价
来回对话
我立即发现双子座在来回对话中表现更好。以下是验证我的假设的测试:
我用信息促使模型。
我星期三有一个牙医的约会。
然后,我立即就共享的信息提出了一个问题:
我的牙医约会安排在什么时候?
我期望模型能够提供一个合理的答案:提到或者关联到“星期三”的事物。
这很重要,因为我喜欢追踪问题、完善我的推理和编码,并确保在使用语音助手时有一个流畅的体验。例如,如果我说“把灯关掉”,然后说“哦,我改变主意了”,它应该推断出我现在想把灯打开。
生成了四组100个提示:
- BaFC A: 提供了一条信息,然后提出了一个与之相关的问题。
- 保持HTML结构,将以下英文文本翻译成简体中文: BaFC B: BaFC A,但所提供的信息避免了个人数据或常识,迫使模型进行推理并消除了隐私顾虑。
- BaFC C:第一条消息提供了一些细节;接下来的两条消息改变了主题,可能会“困惑”模型,然后问了一个关于第一条消息的问题。
- 将英文文本翻译为简体中文时保持HTML结构:
BaFC D: BaFC C,但所提供的信息避免个人数据和常识,强迫模型进行推理并消除隐私顾虑。
综合结果:
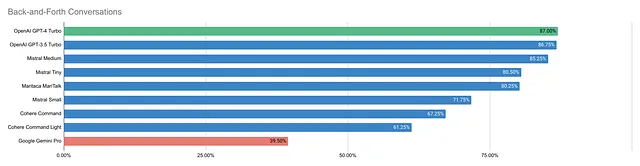
GPT-4以87%的成功率领先,略高于GPT-3.5的86.75%,而Mistral Medium紧随其后,达到85.25%。Mistral Tiny和Maritaca MariTalk的得分略高于80%。Cohere Command模型位于较低的位置,而Google Gemini Pro得分最低,仅为39.5%。
如果你想知道失败案例是什么样子,这里是Gemini Pro评估的一个样本。
用户:我对《星夜》这幅画印象深刻。
双子座 Pro:文森特·梵高的《星夜》是一幅令人着迷的杰作,持续引发人们的兴趣。。
用户:最近有哪幅画给我留下了深刻印象?
双子座Pro: 作为一个AI语言模型,我没有个人经历或能力参观博物馆或画廊。因此,我无法拥有一副最近给我留下深刻印象的绘画作品。不过,我可以分享一些最近创作的绘画作品...
工具(功能)
模型现在可以调用工具(函数),这是我通过纳米应用程序来探索的功能。这是真实的东西。工具提供了一个基础建设模块和强大抽象的主要特征:无尽的用例,其应用无法预测。
我向模型提出了一个请求:
计算 250 的 110%。
模型意识到计算器工具的存在,并执行以下功能:
执行功能
简单计算器 {"表达式":"250 * 1.10"}
功能输出
275.00 两百七十五元整
然后回答说:
110% 为250 的话则为275。
这个测试为模型提供了使用GNU bc来解决数学问题的Nano App规范。模型必须了解除了仅仅使用工具之外的流行软件。
生成了两组各包含100个提示的内容:
- 工具A:可以使用计算器的直接数学问题。
- 工具 B:隐含数学问题;可能需要推测是否需要使用计算器。
如果模型推断需要计算器并正确使用它来回答问题,那么它成功;否则,它失败。
结果:
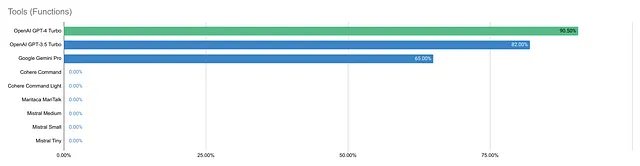
双子座Pro的成功率为65%,GPT-3.5为82%,而GPT-4以90.5%的成功率领先。其他所有模型因缺乏函数调用支持而获得零分。
我想要对比各种纳米应用程序,以查看未来是否会有性能差异。也许某个模型在处理计算器应用方面擅长,但在音乐播放器或天气信息方面需要帮助吗?
多语言主义 Note: "Polyglotism" in English refers to the ability to speak or understand multiple languages. The translated term "多语言主义" captures the same meaning, emphasizing the concept of embracing and promoting multilingualism.
多语能力并不是关于语言理解或翻译;这些方面已有相应的评估标准。它关乎一个模型在我选择的语言中的应用能力。我会用一种语言提供对话开端,然后模型必须以该语言进行回应。我从权威语言指数中选择了10种语言,分别是阿拉伯语、英语、法语、德语、印地语、日语、普通话、葡萄牙语、俄语和西班牙语。
结果:
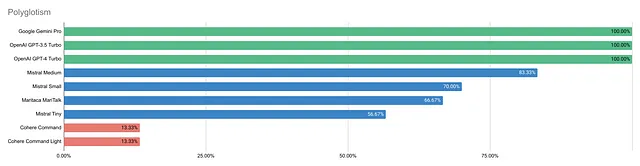
双子座 Pro、OpenAI GPT-3.5 和 GPT-4 分别得到了100%的最高分,领先其他模型。Mistral Medium 排在第二位,得分为83.33%。Cohere的模型得分为13.33%,严重偏向英语。
流媒体
流媒体使交互更流畅。
- 您可以在模型偏离您期望的情况下停止运行。
- 为语音助手创造流畅体验;
- 给我们喜欢的"与您同时打字"的感觉。
结果:
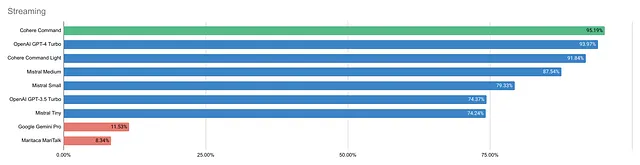
Cohere Command以95.19%的得分提供最佳的流媒体体验,其次是OpenAI GPT-4 Turbo,得分为93.97%。OpenAI GPT-3.5 Turbo和Mistral Tiny的结果最低,略高于74%。Google Gemini Pro和Maritaca MariTalk无法提供有效的流媒体;MariTalk仍需进行改进。Gemini Pro的“流媒体”主要是等待,然后才有大量活动,不是真正的流媒体。
看看这个演示:
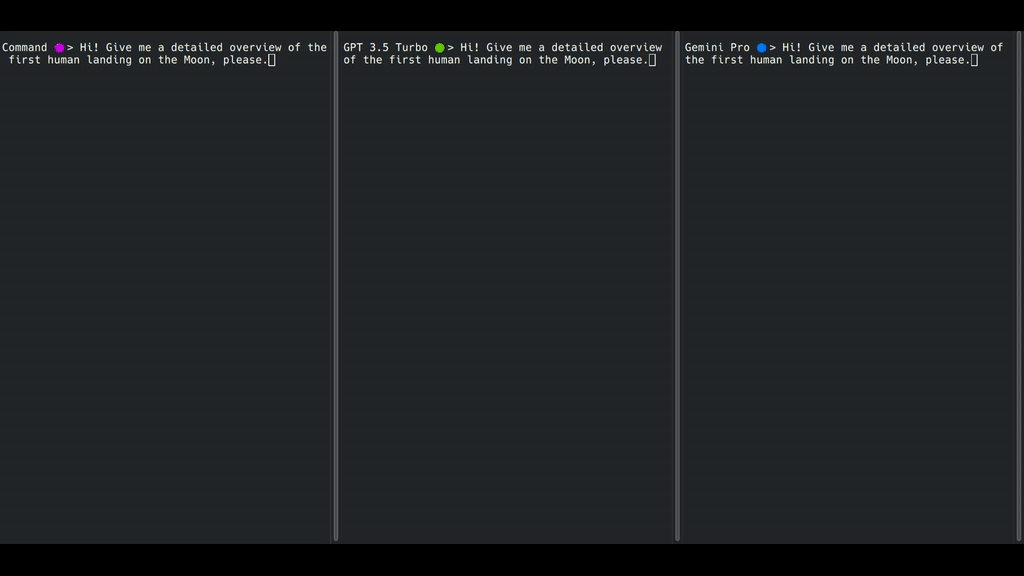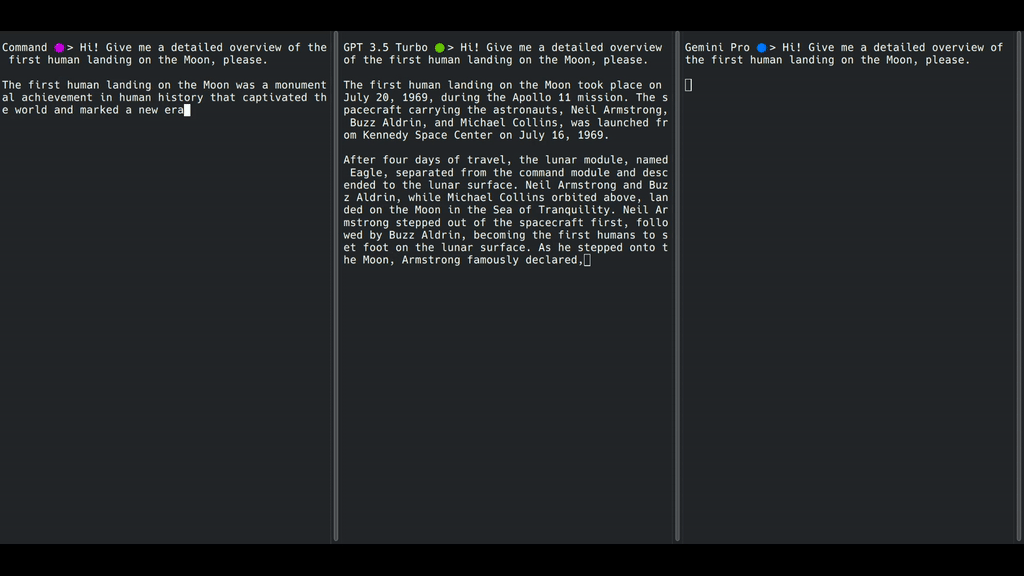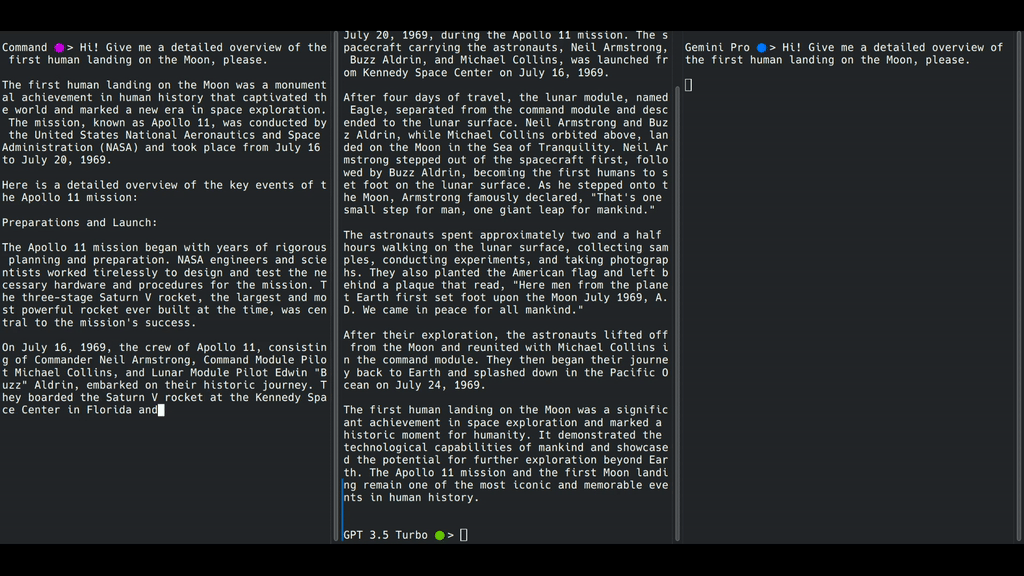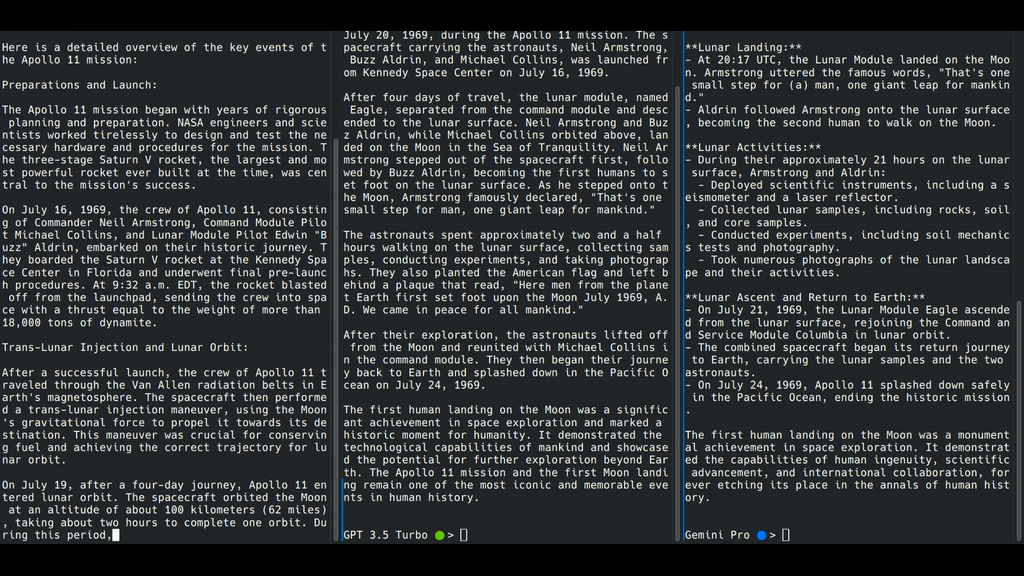
双子座Pro(右)不进行流式传输。OpenAI GPT-3.5 Turbo(中间)逐字进行流媒体传输,而Cohere Command(左侧)逐字进行字符流媒体传输。
延迟
为了评估该模型的速度(每秒字符数),我测量了获取最终输出所需的时间,忽略了流式传输能力。
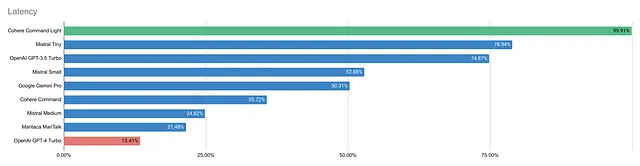
Cohere Command 以速度领先,其次是 Mistral Tiny 和 OpenAI GPT-3.5。OpenAI GPT-4 Turbo 是最慢的。
定价
我将所有价格标准化为每个代币的美元,从而得到了一个涵盖输入和输出成本以及冗长程度的衡量指标。
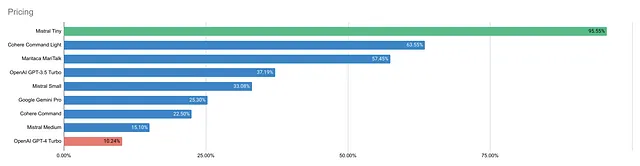
Mistral Tiny的价格最低,每百万个令牌价格为0.46美元,而GPT-4 Turbo则最贵,售价为30.00美元,高出6300%以上。
热门基准
我选择了两个测试与LBPE的分数进行比较。另外,我想要将公司报告的数字与我自己的发现进行比较。
第一个是MMLU,这是用于报告模型能力的最流行的基准。
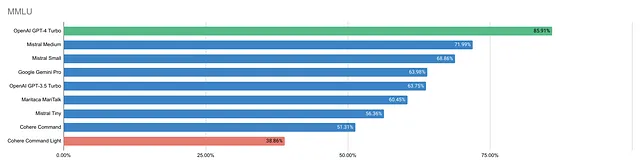
OpenAI的GPT-4 Turbo以85.91%的得分位居首位,紧随其后的是Mistral的中型和小型模型,分别为71.99%和68.86%。Cohere的模型效果最差,其中Command Light的得分为38.86%。
第二个是巴西大学入学考试(ENEM),用于测试非英语语言的模型。
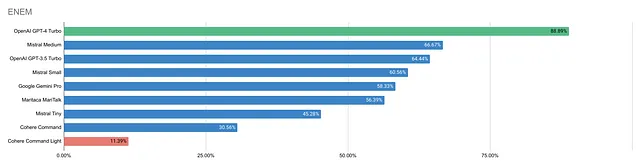
再次,OpenAI的GPT-4 Turbo以88.89%的得分领先,而Command Light以11.39%的得分落后。
综合结果
所有模型的结果以热图表格显示:
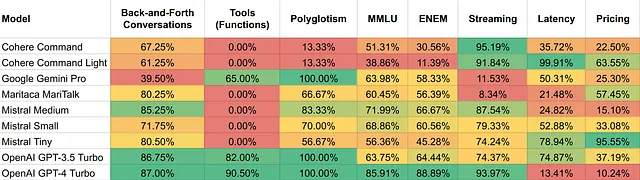
可在此处查看表格和CSV文件的可访问版本。
一旦我获得了模型的结果,我将使用雷达图来对每个模型进行分析。这样可以避免绝对排序,而是突出各个模型的优点和缺点,以便进行权衡。
OpenAI GPT-4 Turbo:
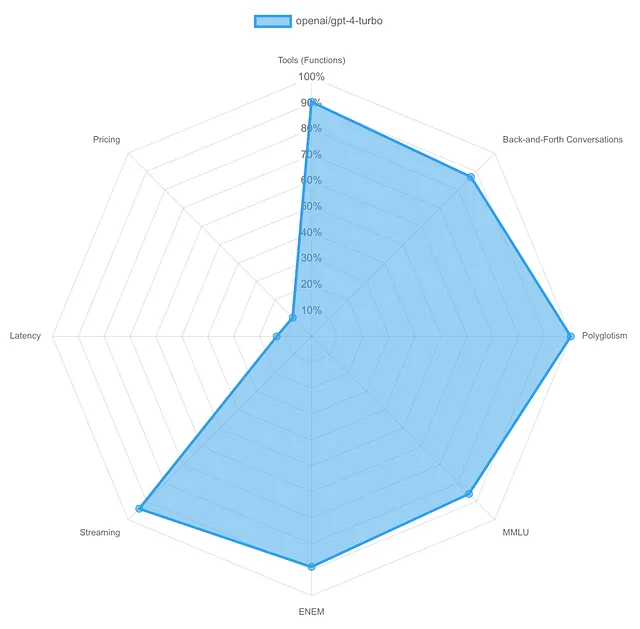
该模型在大多数方面都提供了最佳性能;它的缺点是延迟,这会给流媒体造成偏差,以及高昂的价格。
在https://gbaptista.github.io/lbpe-score/上,探索雷达图和所有模型的得分详情。
见解
这些数据提供了许多见解;我将重点强调对我来说最引人注目的那些。
OpenAI GPT-4 Turbo仍然是我关心的事物的最佳模型。
将GPT-3.5 Turbo与Google Gemini Pro进行比较,可以揭示出我感受的基础。
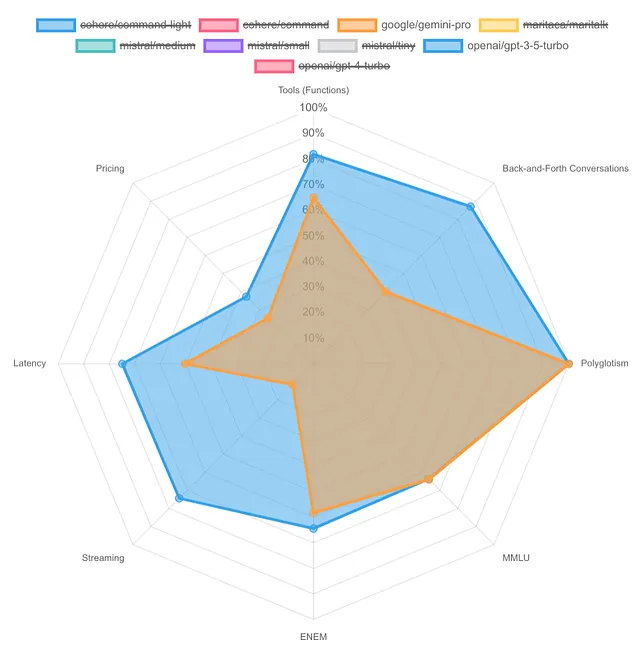
我特别喜欢来回对话和实时流媒体,这是Gemini Pro需要赶上GPT-3.5的地方。谜底揭开了。
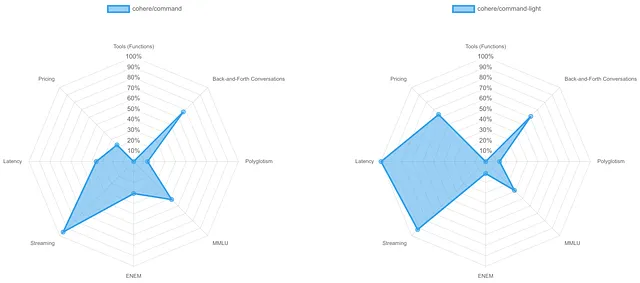
团结指令模型在多语言支持方面显著落后于其他模型,经常默认使用英文回复。
MariTalk在来回对话中超过了Gemini Pro,并且紧密匹配它的MMLU和ENEM得分。
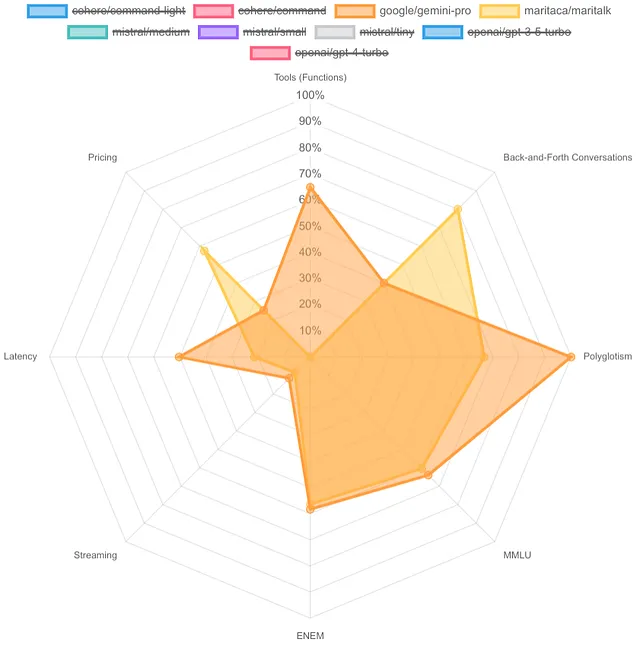
最后,Mistral AI 到底在做什么呢?我不知道 Gemini Ultra 是否已经实现,但就目前而言,若有人离 OpenAI 更近一步,那一定是 Mistral AI 伙计们。
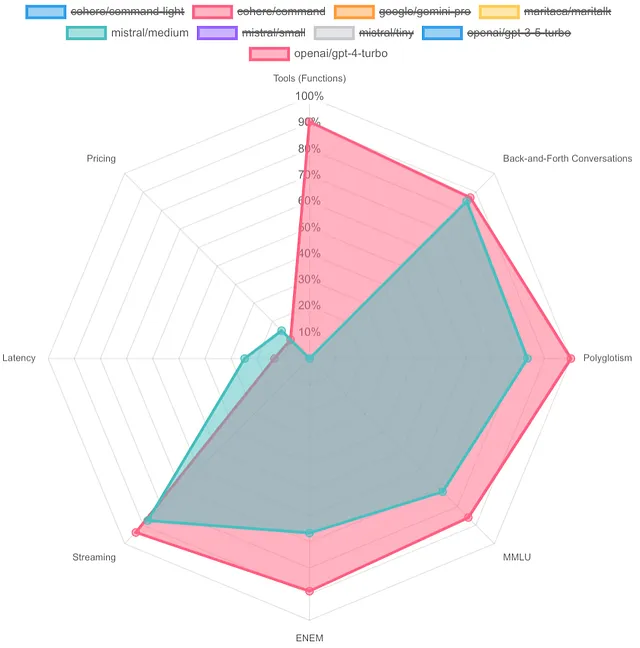
很遗憾他们目前还不支持函数调用。
无论如何,我将花时间探索Mistral的一些用例。它可能以更低的成本和更快的速度提供类似GPT-4的性能。
总结
LBPE分数提供了额外的洞察和补充,而不是替代常用的基准指标。它针对我关心的内容,可能与你关心的内容不同。
这个初始版本可能存在一些缺陷。所有源代码和数据都可供审查和复制,鼓励科学所需的审查。这里提供实时图表和结果的详细介绍。
我喜欢探索这些模型并理解自己的偏好。希望你也觉得这样有趣和有帮助。