超越ChatGPT: 对NLP中基于检索增强生成的深入研究
为什么对所谓的LLMs如此炒作?ChatGPT是2023年最大的新闻,也是人们最喜欢的创新。许多企业家都对将其应用于他们的GenAI应用程序感兴趣,但我们如何要求ChatGPT对新数据或我们自己从未见过的数据进行回应呢?这难题不就是最大的挑战吗?虽然LLM模型在生成文本方面很有创意,但可能缺乏上下文。LLMs内部的这个挑战引发了一个关键问题:如何在不牺牲其创造能力的情况下提高LLMs的准确性?
检索模型是什么?
检索模型始于检索与给定查询相关的一组排名靠前的文档。这种检索不仅仅是对关键词进行基本搜索,而是一个复杂的过程,涉及理解用户的问题/查询的含义,并试图从整个数据源中获取更多相关信息。
什么是RAG?
检索增强生成(RAG)因为其突破性发展而引人瞩目。RAG在当今起到非常关键的作用,通过填补检索相关信息和生成具有上下文意识的回应之间的差距,RAG为一度被认为是自动化系统难以达到的可能性开启了新的大门。
检索方法和基因人工智能的婚姻
基于检索的模型在从预定义的知识库中获取相关信息方面表现出色。它从非常基本的关键词搜索方法开始,逐渐发展为GenAI,并且现在已经发展到诸如BAAI/bge-large-en-v1.5等非常知名的模型。
RAG架构简单来说是检索模型和生成模型的结合。这是一个典型的两步过程;→检索机制首先从知识库中识别相关信息。→然后生成模型利用这些信息生成连贯并具有上下文意识的回答。
为什么我们需要RAG?
为了生成有意义的回应,系统首先必须理解上下文,然后可以访问相关信息。LLMs(例如ChatGPT)的准确性和能力高度依赖于模型的预训练数据,而RAG智能地从外部数据集中提取更多相关信息(在运行时不在LLM的训练数据中),以确保更准确、与上下文对齐和可靠的输出。
举例来说,ChatGPT3.5 的数据限制在2022年1月之前,如果我们用以下方式查询ChatGPT,它无法提供相关信息。那么解决方案是什么呢?RAG登场....!!!! RAG 可以从互联网来源中提取出最相关的背景信息。然后这些有上下文意识的文本可以在像ChatGPT这样的生成模型中使用,以获得有意义的回应。
LLMs本身非常强大,但是;
💵 预训练 LLM 需要大量的数据和数百万的计算成本(图形处理器)。
👥 对助手进行微调或训练以获得一个基础模型只需付出一小部分成本,然而这需要人类生成的带有标签的数据或指令集。
🔦 通过编写提示,我们与LLM进行互动。除了我们的主要问题或任务外,我们经常通过提供一些示例或指导LLM来传递上下文。这可以提高LLM的性能,但对于更复杂的任务来说,这仍然不够。
为什么GenAI应用程序停留在概念验证阶段?
使用第三方API或类似llama2的开源模型构建低代码演示并不能保证其可靠性和安全性。 GenAI被吹得如此火热,但实际产品与炒作相去甚远。原因是许多供应商倾向于频繁更新他们的API,这导致使用这些API构建的应用在时间推移中性能发生变化且难以监控。这些API不支持域外查询,稍微调整我们的查询可能会导致响应不确定。此外,GenAI应用程序没有实时保护。
现实世界的应用
增强对话代理:
用RAG技术可以显著提升会话代理的性能,使其能够访问庞大的知识库,并生成既符合上下文又基于准确信息的回复。
信息综合:
在需要信息综合的情况下,例如内容创作或新闻文章生成,RAG 可以起到关键作用。它确保生成的内容不仅富有创意,而且事实准确。
医疗信息检索
RAG模型被用于检索和生成相关的医疗信息。在医疗应用中,准确和最新的信息对于决策、诊断和患者教育至关重要。
法律文件分析
在法律领域中,RAG模型有助于分析和总结法律文件。通过检索相关案例法律并生成简明摘要,这些模型可帮助法律专业人员快速理解和处理复杂的法律信息。
财务分析和报告
在金融领域,RAG模型有助于检索和总结相关的财务数据。这对分析师和投资者来说是非常有价值的,能够快速评估市场趋势、公司表现和财经新闻。
如何建立您的RAG-LLM应用程序?简单流程;
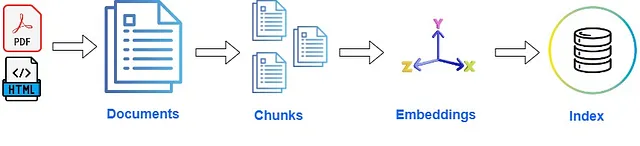
⚡文档:对于大多数应用程序,数据集通常以HTML文件或PDF文件的形式存在。我们对其进行解析、清理,并将其加载到S3桶中,例如。⚡块:一旦我们从PDF文件中提取文本,但是目前无法将此提取的文本传递给我们的RAG应用程序。每个部分的文本长度各不相同,许多都是相当大的块。对于每个文档,我们将其分割为多个块。⚡嵌入:我们使用嵌入模型(如BAAI/bge-large-en-v1.5)为每个块生成嵌入。⚡索引:使用索引将嵌入和块数据存储在一个向量数据库中。
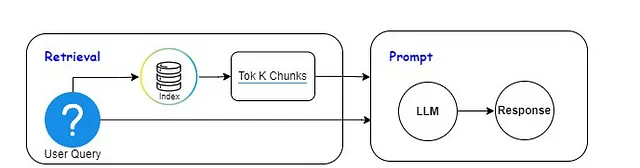
⚡检索:数据存储在vectorDB中并附带索引后,我们对该索引进行检索。我们将用户查询与索引进行匹配,并提取与查询相似度最高的前k个数据块。⚡LLM:随后,我们将与用户查询最相似的前k个数据块以及用户查询一起传递给LLM的提示,以生成响应。
总结一下,RAG的理念是通过在运行时从LLM的训练数据之外的数据源中获取相关信息,为提示添加更多相关背景。