揭开AI准确性的秘密:Alani vs. Perplexity及其他LLMs
引人入胜的AI准确度实验——Sunny Madra
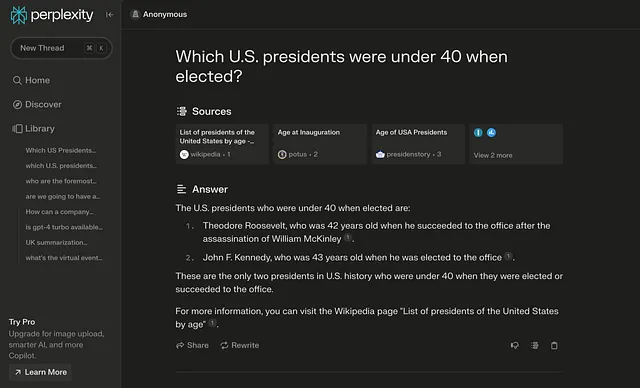
最近,Sunny Madra在Twitter/X发布了一篇文章,突出了各种大型语言模型(LLMs)在回答一个简单问题时的准确性:“哪些美国总统在40岁以下当选?” 这个实验的结果是令人震惊的,尤其是Alani和Perplexity.ai这两个模型的表现形成了鲜明对比,它们使用了相同的数据源,但却产生了不同的结果。
人工智能幻觉现象
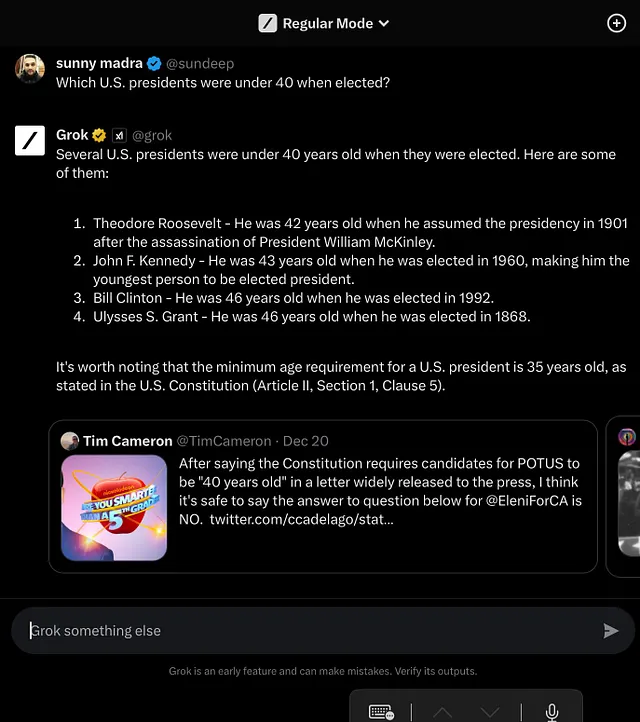
无论是 Grok、Bard、Gemini Pro 还是 Perplexity,多个 LLM 均反馈了一项普遍的人工智能难题:幻觉。该术语用于描述人工智能模型生成了看似合理但实际上错误的信息的情况。在这种情况下,这些模型错误地将西奥多·罗斯福和约翰·F·肯尼迪等美国总统认定为在40岁以下就当选的情况。
Alani:准确数据解读的案例
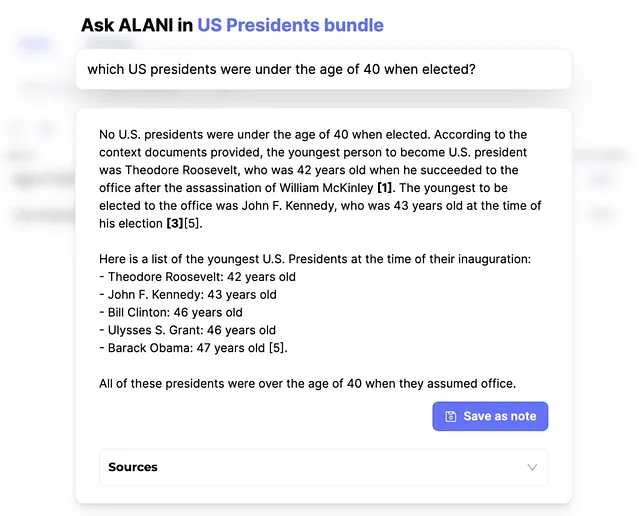
与这些不准确之处形成鲜明对比的是,Alani成为可靠性的典范。尽管使用与Perplexity.ai相同的信息源,Alani成功地提供了正确的答案:没有一位美国总统是在40岁以下当选的。这凸显了人工智能性能的一个关键方面:准确解释和应用来源数据的能力。
阿拉尼对困惑:数据利用研究
关于 Alani 和 Perplexity 的主要区别在于它们的数据利用策略。虽然两个模型都获得了相同的信息,但只有 Alani 正确地处理和解释了这些数据。这种差异凸显了人工智能数据处理算法的质量与数据本身的质量一样重要。
与其他LLMs相比的阿拉尼和困惑度比较
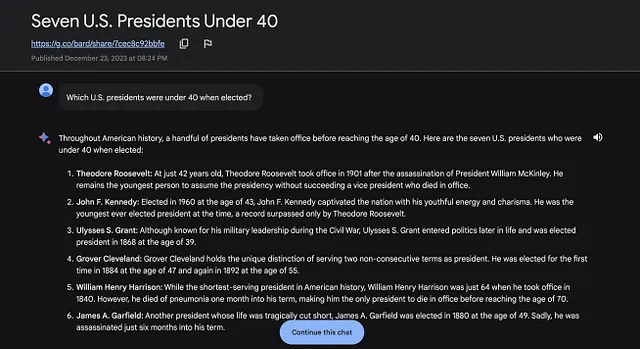
尽管Alani在准确性方面表现出色,但其他LLM(灵感语言模型),包括ChatGPT,在回答问题方面却各有不同。像Alani一样,ChatGPT正确回答了问题,展示了其强大的数据处理能力。然而,像Grok、Bard和Gemini Pro这样的模型,尽管拥有先进的算法,却陷入了AI幻觉的陷阱中,突显了人工智能发展中持续存在的挑战。
AI数据处理的含义
这个实验强调了人工智能技术的一个关键方面:AI模型处理和解释数据的能力与数据本身同样重要。虽然获取准确和相关的信息是基础,但是模型的算法及其实施在确保输出可靠性方面起着决定性作用。
以批判的视角拥抱人工智能
随着人工智能在各个领域的普及,这个实验提醒我们批判性评估由人工智能生成的信息的重要性。它强调了改进人工智能算法的持续性需求以及在需要高度事实准确性的情境中验证人工智能输出时人类监督的重要性。
结论:追求可靠人工智能之旅
阿拉尼、迷失、以及其他LLM在回答总统年龄问题上的表现不同,说明了人工智能发展的不断演进。了解这些模型的优势和限制是有效利用它们能力的关键。在追求更可靠的人工智能方面,结合技术创新和明智审查的平衡方法是必不可少的。








