大型语言模型(LLM)如何工作?
大型语言模型(LLMs)如ChatGPT、Bing的新“Sydney”模式和Google的Bard正在占据头条。本文将探讨这些模型的运作方式,包括它们获取数据的来源以及使它们能够生成令人信服的逼真文本的基本数学原理。

机器学习101
LLMs是一种机器学习模型,就像许多其他模型一样。为了理解它们的运作方式,让我们首先了解机器学习的基本概念。
提醒:有很多在线的优秀视觉资源可以更详细地解释机器学习,也比我讲得更好 — 我推荐你去看看!不过,我将在这里介绍基本概念。
最简单的理解基础机器学习模型的方法是通过思考预测:基于我已经知道的,一个新情境中可能会发生什么?这类似于你的大脑工作的方式。
假设你有一个总是迟到的朋友。你正在计划一个聚会,所以你期望他会再次迟到。虽然不确定,但考虑到他的记录,你认为有很大的可能性。如果他准时到达,你会感到惊讶,并记住下次;也许你会调整对他迟到的期望。
你的大脑不断地运行着许多这样的模型,但现在,我们还不完全了解它们在内部是如何工作的。在现实世界中,我们必须依靠算法——有些简单,有些非常复杂——它们从数据中学习,并对新情况下可能发生的事情进行预测。通常,模型被训练来执行特定任务(如预测股票价格或创建图像),但它们开始变得更加多才多艺。

一个机器学习模型有点像一个API:它接收输入,并且你通过教它产生特定的输出。下面是整个过程:
1. 收集训练数据:收集关于你想建模的大量数据。 2. 分析训练数据:查看数据以寻找模式和细节。
3. 选择一个模型:选择一个算法(或几个算法)来理解数据及其运作方式。
4. 训练:运行算法,它会学习并储存所发现的内容。
5. 推理:向模型提供新的数据,它会提供自己的想法。
您创建模型的接口,根据其需要完成的具体工作决定其接收和返回的信息。
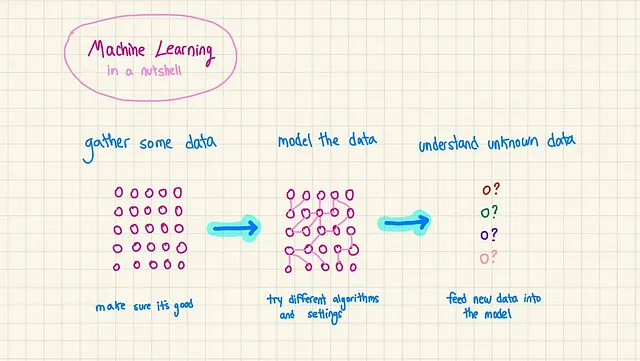
你问算法做什么?嗯,把它想象成一个超级聪明的分析员。它能发现你提供的数据中的连接,这些连接通常对你来说太棘手而无法自己发现。这些数据通常包含一些X方面的东西——比如特征、设置、细节——还有一些Y方面的东西——实际发生的事情。如果你正在查看这些数据:
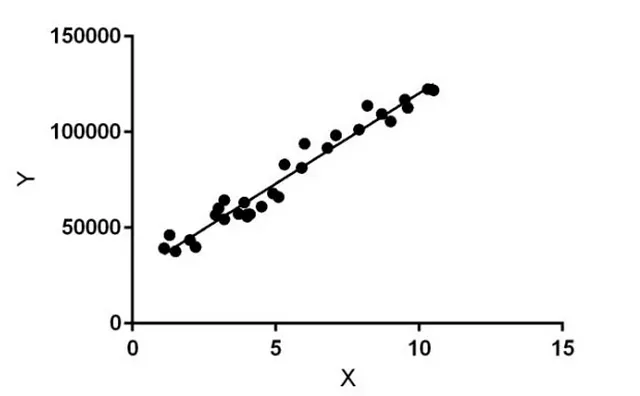
你不需要机器学习告诉你,当X为15时,Y大约为150,000。但是如果有30个不同的X物品怎么办?或者数据看起来都很奇怪?或者是文本?机器学习正是处理我们人类所无法解决的棘手情况。就是这样。
这就是为什么机器学习算法可以像统计学中的线性回归一样简单,也可以像有数百万个节点的神经网络一样复杂。最近新闻中的超级先进模型相当复杂,需要大量人员和多年的研究。但在许多公司,数据科学家使用简单的算法仍然可以获得良好的结果。
🔍深入了解🔍
从头开始构建强大的机器学习模型是一个非常专业的领域。一些数据科学家和机器学习工程师使用诸如PyTorch和Tensorflow等工具来创建模型,而其他人则增强现有的开源模型。您还可以选择将整个模型开发过程外包并使用其他人创建的现成模型。
🔍深入了解🔍
创建模型就像是一个试错的过程。除非你的数据非常直接简单,否则在你的模型开始有意义之前,你可能需要测试不同的方法并不断进行调整。这是科学、数学、艺术和一点点随机性的结合。
语言模型和生成文本
当您的数据具有时间要素,例如预测未来股票价格或理解即将到来的选举,模型的运作方式就很明确了。它使用过去来预测未来。然而,许多机器学习模型,如语言模型,根本不处理时序数据。
语言模型只是处理文本数据的机器学习模型。你可以用一个被称为“语料库”(或者简称为“文本体”)的东西对它们进行训练,然后你可以用它们来完成各种任务,比如:
- 回答问题
- 搜索
- 总结
- 转录
语言模型的概念已经存在了一段时间,但是随着神经网络深度学习的近期兴起,这变成了一件大事;我们将讨论这两者。
概率语言模型
在简单的术语中,概率语言模型就像是一个针对单词或单词组的概率地图。在英语中,它会检查一段文本并分析哪些单词出现了,它们何时出现,频率如何,以及它们的顺序等等。所有这些信息都以统计的方式进行捕捉。
现在,让我们快速制作我们自己的语言模型。
以下是两个句子,可能或可能不表达我真正的想法:
“最好的曼哈顿鸡尾酒配方使用两盎司的Van Brunt Empire Rye威士忌,一盎司的Cocchi Di Torino甜味苦艾酒,一滴Angostura苦艾酒和一滴橙子苦艾酒。我在混合玻璃杯中搅拌大约60次,倒入冷冻的Nick and Nora玻璃杯,再加一个玛斯奇诺樱桃作为装饰。”
为了创建一个简单的概率语言模型,我们将收集n元组,这是一个用来表示词组的高级统计术语。让我们将n设为1,这意味着我们只会计算单词出现的频率。
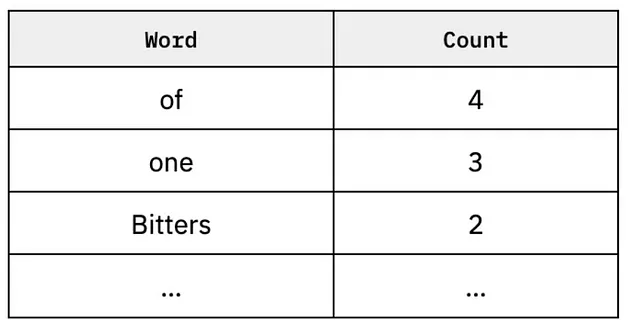
如果n=2:
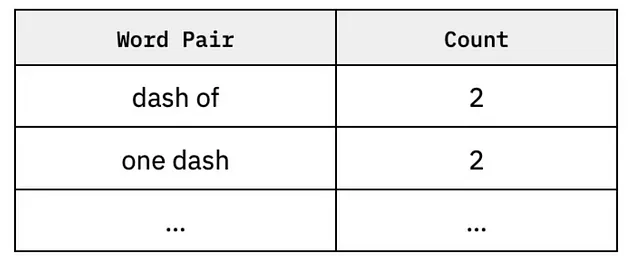
模型的作用是创建一系列的n-gram,注意单词们如何一起出现以及其顺序。
😰 不要为细节而烦恼 😰
我只是通过n-gram练习来展示许多模型所做的事情实际上并不是那么复杂(尽管对某些人来说可能是)。所以,如果你没有理解上面的所有细节,不要焦虑。
😰 不要为细节烦心 😰
一旦你把这些信息存储起来,你可以预测下一个可能出现的词汇。如果我们从我们的两个鸡尾酒句子中创建一个新的句子,我们会按照之前的方式将单词组合在一起。
神经网络与语言模型
概率语言模型已经存在了几十年。但最近,使用神经网络——一种更复杂的算法——进行语言模型的方式变得更加流行。这些网络通过使用称为嵌入的东西以更有意义的方式了解正在发生的情况。模型直接从单词中学习是棘手的,但对它们来说,从这些单词的数学表示学习要容易得多。
嵌入是一种将具有大量维度的数据(例如包含许多离散单词和组合的庞大文本体)进行数学表示并减少数据量的方法,而且不会丢失太多细节。对于一个机器学习模型来说,处理来自于100篇涉及调酒制作的博客文章,每篇文章包含1,500个词(总计15万个词!)的文本是非常困难的。但是,如果我们能够将这些信息转化为一组数字,那么我们就走在了正确的轨道上。
配备了更用户友好的单词和文本表示方法,神经网络能学习关于文本的重要信息,如:
- 单词之间的语义关系
- 带入更多的背景(一个单词或句子之前和之后的句子)
- 弄清哪些单词是重要的,哪些不重要。
这东西变得相当复杂。 但目标很简单:建立一个强大的模型,能够在预测下一个词、句子或段落时考虑到大量的上下文,就像我们的大脑所做的一样。
大型语言模型现在
ChatGPT及其衍生产品基本上是巨大的语言模型(这就是它们被这样称呼的原因)。它们是建立在过去十年的先进技术层面之上的。包括:
- Word2Vec模型
- LSTM(长短期记忆)模型
- 循环神经网络 (RNN)
- 变形金刚(是的)(也被称为“基础模型”)
你真的不需要知道这些东西的每一个是什么。关键是要意识到这些大型语言模型并不是突然的科学突破。研究人员多年来一直在稳步进展,每一次新的发展都在达到现在这一点时起到了至关重要的作用。当LSTMs在2019年获得关注时(尽管概念在90年代就被引入),曾经有过一个大炒作周期,对这一切都是如此。研究有点奇怪!
ChatGPT和LLMs生成整段文本的方式是不断玩一个猜词游戏。
这里是概述:
1. 您给模型提供一个提示(这是“预测”短语)。 2. 它根据提示预测一个单词。 3. 它根据第一个单词预测第二个单词。 4. 它根据前两个单词预测第三个单词。 5. ...
当你将它分解开来,它其实相当基础。但是事实证明,当你的模型在整个互联网上的所有文本上训练时,猜词游戏可以变得非常强大。数据科学家经常说机器学习模型的原话是:“垃圾进,垃圾出”——这意味着你的模型只能和你用来训练它的数据一样好。通过与微软合作,OpenAI能够利用大量计算资源收集这些数据,并在强大的服务器上训练这些模型。
保持HTML结构,将以下英文文本翻译为简体中文: 在整个网络作为语境的情况下,语言模型(LLMs)可以产生的句子很少偏离某种“正常”情况,这与旧模型不同。如果网络上不存在短语“I Angostura my cocktail with Manhattan ice around glass twist”,那么模型很可能不会生成它。而这个简单的真理正是这些模型如此出色的一个重要原因。

这引发了一个关键问题:这些LLM真正掌握他们所提供的答案吗?弄清楚这个问题涉及到数学、哲学和语义的结合("理解"到底意味着什么?)。