双子座声称比ChatGPT更优越:我尝试复制他们的发现。
当我尝试过Gemini后,我并没有感觉到它的优越性,开始对它的声称产生了怀疑,这让我产生了一个问题:为什么呢?
如果你的第一个想法是,“他们在撒谎吗?”那是可以理解的;但是,我鼓励你不要继续沿着那样的思路去想。我相信Gemini的开发者们的诚信,质疑这一点并不是这个问题的关键所在。
等等,我们应该无条件相信他们的声明吗?
绝对不会;这就是科学的美妙之处:某人取得突破并发表论文后,其他人开始通过复制来验证研究结果。我们并不质疑个人的诚信;我们通过追求真理来推动科学的进步。
我会分析并试图复现MMLU基准测试,该测试用于展示Gemini在其网站上的优势。

分析MMLU基准结果
这是关于Gemini性能的技术报告:Gemini:一系列高度能干的多模态模型。
根据报告,在大多数任务中,吉米尼在页面7上的表格中表现优于GPT。
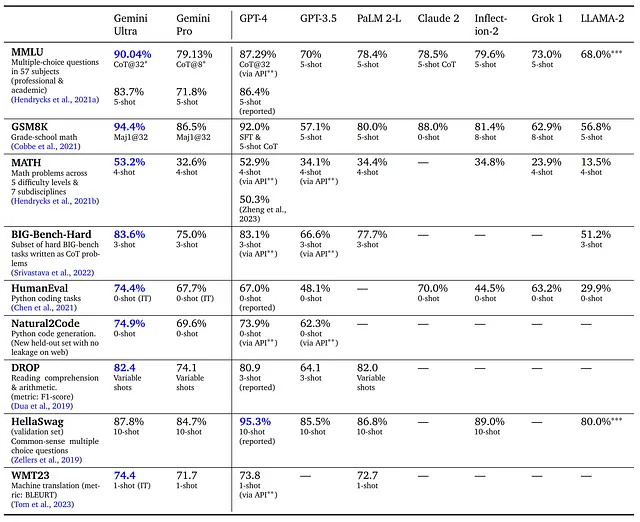
让我们解析MMLU的结果:该基准测试评估文本模型在数学、历史、计算机科学、法律等各种主题下的多任务准确性。高准确性要求模型具备广泛的知识和强大的问题解决能力:衡量大规模多任务语言理解。
测试详细信息位于GitHub上,可以从伯克利网站下载。问题遵循以下格式:
人体消化系统的哪个部分主要负责吸收水分?
A) 胃。B) 小肠。C) 大肠。D) 食道。
在开始测试之前,让我们先解释一些术语。
使用的工程技术,以提高答案的准确性:
- CoT: 链式思维促使模型逐步解释其推理过程。
- 五方案:少数样本提供了一个模型,在提问之前提供了一些例子和它们的预期答案。
结果的起源
- 报道:他们使用了其他来源的数字,而没有进行自己的测试。
- 通过API:通过API自行收集的结果。
让我们对每个术语中的* 星号也保持准确。
CoT@8 和 CoT@32:
该模型使用k=8或32个样本生成一系列思路。如果达成共识超过一个阈值(基于验证集划分选择),则选择该答案;否则,返回贪婪样本。请参阅附录9.1进行进一步分析。
通过API:
2023年11月,通过API自行收集的结果。
设计测试
这里有一些前提条件:
- Gemini Ultra 应该与 GPT-4 进行比较。
- 双子座 Pro 应与 GPT-3.5 进行比较。
- 两个模型的提示应完全一致。
- 结果应该是可复制的和开放接受挑战的。
- 使用可供终端用户访问的API来评估两者。
重现结果可能具有挑战性,原因如下:
- 我没有使用Gemini Ultra的权限,只能使用Gemini Pro。
- Google报告了Gemini Pro CoT@8与GPT-3.5 5-shot的结果。
- 我不明白为什么该网站将Gemini Ultra的CoT@32与GPT-4的5-shot进行比较,而没有与GPT-4的CoT@32进行比较,这似乎更合理。另外,不清楚为什么只有GPT-4有CoT@32的结果,而没有GPT-3.5。
让我们尽力而为,以我们所拥有的。
Translate English text to Simplified Chinese
Click the button below to translate the text.
我们将采用连锁思维方法来评估他们在MMLU测试中的表现。提示:
最初的
人体消化系统的哪个部分主要负责水的吸收?
A) 胃。B) 小肠。C) 大肠。D) 食管。
从解剖学的相关知识入手。分析每个选择,考虑解剖学的原则、事实和逻辑。为每个选择提供详细分析。
后续:
根据您的分析和推理,哪个选项似乎最合理,并且是正确答案?
最终
只给我正确答案选项的字母。
我们将使用纳米机器人来测试使用1,760个MMLU数据集问题的Ruby模型,对于正确回答的问题给予1分,对于错误或未回答的问题给予0分。GPT-4 Turbo(gpt-4-1106-preview)将评分模型的答案。
结果
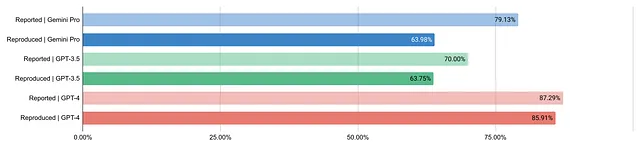
水平条形图显示 Gemini Pro、GPT-3.5 和 GPT-4 的报告和重复结果。
- 双子座 Pro:再现结果为63.98%,比报告结果的79.13%低。
- GPT-3.5:复现的结果为63.75%,低于报告的结果70.00%。
- GPT-4: 在87.29%的情况下,所报告的结果是三个中最高的,而再现的结果也非常接近,为85.91%。
双子座Pro和GPT-3.5的表现低于报告的数值,几乎相同,相差不到1%,而不是报告的9.13%。GPT-4的表现几乎与报告的数据相匹配,差异为1.38%。
你可以查看数据、分析细节并审核评估代码。
知识诚实
不信任我的结果并质疑它们的原因:
在API中,模型版本(gemini-pro、gpt-3.5-turbo-1106和gpt-4-1106-preview)可能与产生报告结果的版本不同。
应用的提示工程技术,将带有两个后续提示的思维链技术与报告中概述的CoT@8和CoT@32方法可能不同。
我相信GPT-4可以像AlpacaEval一样评估评价,但这种方法可能存在缺陷。人类同行评审会提供更可靠的评分。
测试模型可能会从MMLU数据集中污染数据。当模型从“泄漏”的测试数据中学习时,就会发生数据污染,从而扭曲结果,并导致模型复制答案而不是在新数据上进行推理。
根据包含13,709个问题的完整MMLU集,1,760个问题样本可能不足以得出结论。
我可能弄错了或者漏掉了一些东西。
结论
我的MMLU测试复现与GPT-4的结果相符,但与GPT-3.5和Gemini Pro的结果相矛盾,包括它们所报道的性能差距。目前仍在等待Gemini Ultra的访问权限,以检查其数据。为了科学的缘故,看到其他基准测试的复制将会很有趣。
无论如何,为什么我觉得GPT-3.5要比Gemini Pro好,尽管基准测试显示性能相似?好吧,这些基准测试可能不符合我的具体需求。
我正在设计一个新的补充性基准来展示我认为Gemini相对于GPT的位置,尽管我目前无法科学地证明: LBPE得分。
我很快就会分享关于它的信息。