Neo4j x LangChain:深入研究新的向量索引实现
学习如何自定义LangChain的Neo4j向量索引包装器

Neo4j是处理结构化信息的理想选择,但由于其蛮力方法,它在语义搜索方面遇到了一些困难。然而,随着Neo4j在版本5.11中引入了新的向量索引,这种困扰已成为过去。该向量索引的引入使得Neo4j能够高效地执行对无结构文本或其他嵌入式数据模态的语义搜索。新增的向量索引使得Neo4j非常适合大多数RAG应用,并且现在能够很好地处理结构化和无结构化数据。
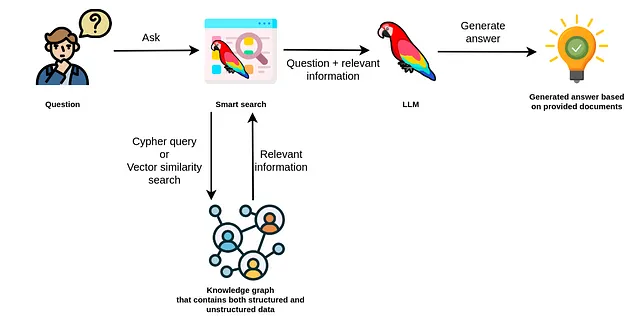
这篇博客文章旨在为您介绍LangChain中Neo4j Vector Index实现中的所有定制选项。
这段代码可以在GitHub上找到。
Neo4j环境设置
您需要设置一个Neo4j 5.11或更高版本才能跟随本博客文章中的示例。最简单的方法是在Neo4j Aura上启动一个免费实例,该实例提供Neo4j数据库的云实例。或者,您还可以通过下载Neo4j桌面应用程序并创建一个本地数据库实例来设置Neo4j数据库的本地实例。
示例数据集
为了这篇博客文章的目的,我们将使用WikipediaLoader从巫师页面获取文本。
from langchain.document_loaders import WikipediaLoader
from langchain.text_splitter import CharacterTextSplitter
# Read the wikipedia article
raw_documents = WikipediaLoader(query="The Witcher").load()
# Define chunking strategy
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(
chunk_size=1000, chunk_overlap=20
)
# Chunk the document
documents = text_splitter.split_documents(raw_documents)
# Remove the summary
for d in documents:
del d.metadata["summary"]Neo4j 向量索引定制化
每个文本块都以单个隔离的节点的形式存储在Neo4j中。
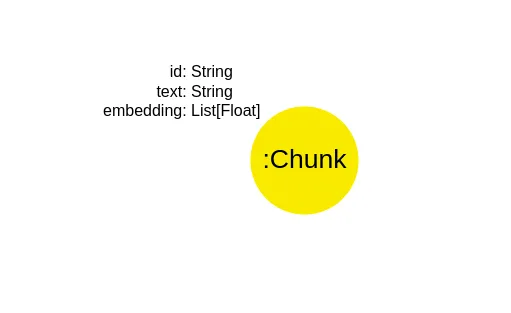
默认情况下,LangChain 中的 Neo4j 向量索引实现使用 Chunk 节点标签表示文档,其中的 text 属性存储文档的文字内容,embedding 属性保存文本的向量表示。该实现允许您自定义节点标签、text 属性名称以及 embedding 属性名称。
neo4j_db = Neo4jVector.from_documents(
documents,
OpenAIEmbeddings(),
url=url,
username=username,
password=password,
database="neo4j", # neo4j by default
index_name="wikipedia", # vector by default
node_label="WikipediaArticle", # Chunk by default
text_node_property="info", # text by default
embedding_node_property="vector", # embedding by default
create_id_index=True, # True by default
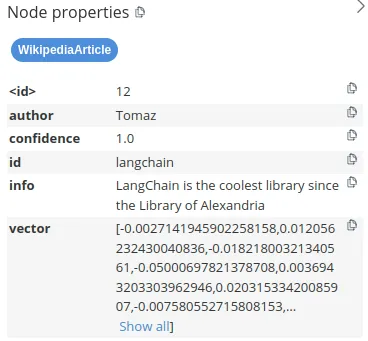
)在此示例中,我们指定了我们希望将文本块存储在WikipediaArticle节点标签下,其中info属性用于存储文本,vector属性保存文本嵌入表示。如果您运行上述示例,您应该在数据库中看到以下信息。
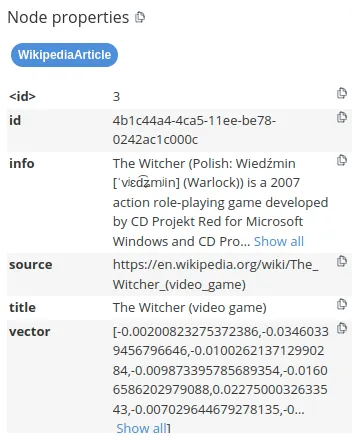
如上所述,我们将info属性定义为包含文本信息的属性,而vector属性用于存储嵌入。源和标题等其他属性被视为文档元数据。
默认情况下,我们还会在指定节点标签的id属性上创建一个唯一节点属性约束,以加快导入速度。如果您不想创建唯一约束,可以将create_id_index设置为false。您可以使用以下Cypher语句验证约束是否已创建:
neo4j_db.query("SHOW CONSTRAINTS")
#[{'id': 4,
# 'name': 'constraint_e5da4d45',
# 'type': 'UNIQUENESS',
# 'entityType': 'NODE',
# 'labelsOrTypes': ['WikipediaArticle'],
# 'properties': ['id'],
# 'ownedIndex': 'constraint_e5da4d45',
# 'propertyType': None}]正如你所期望的那样,我们还创建了一个向量索引,这将使我们能够进行快速的近似最近邻搜索。
neo4j_db.query(
"""SHOW INDEXES
YIELD name, type, labelsOrTypes, properties, options
WHERE type = 'VECTOR'
"""
)
#[{'name': 'wikipedia',
# 'type': 'VECTOR',
# 'labelsOrTypes': ['WikipediaArticle'],
# 'properties': ['vector'],
# 'options': {'indexProvider': 'vector-1.0',
# 'indexConfig': {'vector.dimensions': 1536,
# 'vector.similarity_function': 'cosine'}}}]LangChain 实现创建了一个名为 wikipedia 的向量索引,该索引索引了 WikipediaArticle 节点的向量属性。此外,提供的配置告诉我们向量嵌入的维度为1536,并使用余弦相似度函数。
加载更多文件
您可以使用add_documents方法将额外的文档加载到实例化的向量索引中。
neo4j_db.add_documents(
[
Document(
page_content="LangChain is the coolest library since the Library of Alexandria",
metadata={"author": "Tomaz", "confidence": 1.0}
)
],
ids=["langchain"],
)LangChain允许您向add_document方法提供文档ID,这可以用于在不同系统之间同步信息,并更容易地更新或删除相关文本块。
加载现有的索引
如果您在Neo4j中有一个已存在具有填充数据的向量索引,您可以使用from_existing_method方法连接到它。
existing_index = Neo4jVector.from_existing_index(
OpenAIEmbeddings(),
url=url,
username=username,
password=password,
index_name="wikipedia",
text_node_property="info", # Need to define if it is not default
)首先,from_existing_method会检查数据库中是否存在使用提供的名称的索引。如果存在,它可以从索引配置映射中检索节点标签和嵌入节点属性,这意味着您不必手动设置它们。
print(existing_index.node_label) # WikipediaArticle
print(existing_index.embedding_node_property) # vector然而,索引信息不包含文本节点属性信息。因此,如果您使用除默认属性(文本)之外的任何属性,请使用text_node_property参数进行指定。
自定义检索查询
由于Neo4j是一种本地图形数据库,LangChain中的向量索引实现允许返回信息的自定义和丰富化。然而,该功能面向更高级的用户,因为您需要负责自定义数据加载和检索。
检索查询参数允许您从相似搜索中收集、转换或计算任何您希望返回的附加图形信息。为了更好地理解它,我们可以查看代码中的实际实现。
read_query = (
"CALL db.index.vector.queryNodes($index, $k, $embedding) "
"YIELD node, score "
) + retrieval_query从代码中,我们可以观察到向量相似度搜索是硬编码的。然而,然后我们有选择添加任何中间步骤并返回额外的信息。检索查询必须返回以下三列:
- 这通常是与已检索到的节点相关联的文本数据。这可以是节点的主要内容,名称,描述或任何其他基于文本的信息。
- 分数(Float):这表示查询向量与返回节点关联向量之间的相似度得分。该得分量化了查询与返回节点的相似程度,通常在0到1的范围内。
- 元数据(字典):这是一个更灵活的列,可以包含有关节点或搜索的其他信息。它可以是一个包含各种属性或特性的字典(或映射),为返回的节点提供更多的上下文。
我们将添加一个关系到WikipediaArticlenode以演示这个功能。
existing_index.query(
"""MATCH (w:WikipediaArticle {id:'langchain'})
MERGE (w)<-[:EDITED_BY]-(:Person {name:"Galileo"})
"""
)我们已经在具有给定id的WikipediaArticle节点中添加了EDITED_BY关系。现在让我们测试一下自定义检索选项。
retrieval_query = """
OPTIONAL MATCH (node)<-[:EDITED_BY]-(p)
WITH node, score, collect(p) AS editors
RETURN node.info AS text,
score,
node {.*, vector: Null, info: Null, editors: editors} AS metadata
"""
existing_index_return = Neo4jVector.from_existing_index(
OpenAIEmbeddings(),
url=url,
username=username,
password=password,
database="neo4j",
index_name="wikipedia",
text_node_property="info",
retrieval_query=retrieval_query,
)我不打算过多涉及Cypher的细节。您可以使用许多资源来学习基本语法,例如Neo4j Graph Academy等。要构建有效的检索查询,您必须知道相关节点从向量相似性搜索中可在节点引用变量下获得,而相似性度量值可在得分引用下获得。
让我们试试看。
existing_index_return.similarity_search(
"What do you know about LangChain?", k=1)
#[
# Document("page_content=""LangChain is the coolest library since the Library of Alexandria",
# "metadata="{
# "author":"Tomaz",
# "confidence":1.0,
# "id":"langchain",
# "editors":[
# {
# "name":"Galileo"
# }
# ]
# }")"
#]您可以观察到元数据信息中包含了编辑器属性,该属性是根据图形信息计算而来的。
摘要
新添加的Neo4j向量索引实现使其能够支持依赖于结构化和非结构化数据的RAG应用程序,使其完美适用于高度复杂和连接的数据集。
代码可在GitHub上找到。