不断学习在人工智能领域的现状
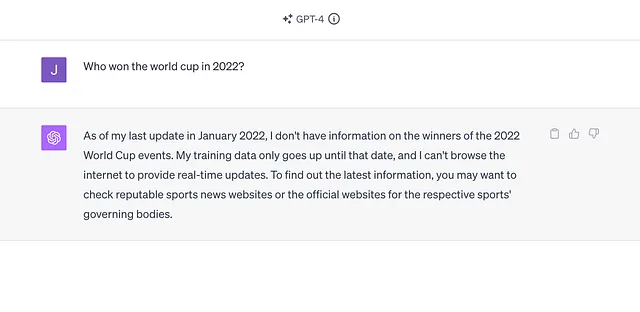
为什么ChatGPT只训练到2021年?

知识要求:
几年前,通过StatQuest视频、Lena Voita的NLP博客以及《深度学习编码者》和《Talking Nets》等书籍,我学习了深度学习的基础知识。现在,我想要了解深度学习中持续学习的最新状况。我发现关于这个主题的简化信息不多,需要查阅专家的研究论文才能理清思路。因此,本文旨在为那些对这个主题有基本理解但发现研究论文难以阅读的读者提供帮助。文章主要关注于聊天机器人,因此了解chatGPT的训练阶段也会有所帮助。
简介
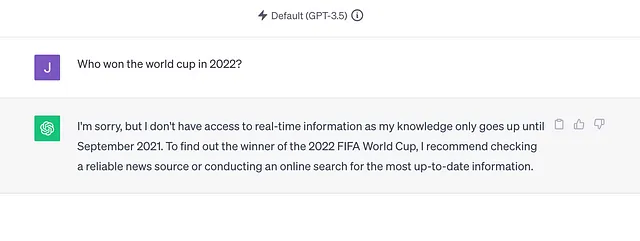
如果像ChatGPT这样的大型语言模型可以持续更新新数据,它们将加速各种任务,从软件开发到法律流程再到学习。这也将使得像本文这样的文章过时。
持续学习是暂停模型训练过程,保存模型的当前状态,并随后根据新数据恢复训练的能力。该模型应能够良好地推广到新数据,同时仍保持对旧数据的推广能力。请参考本文的更正式定义。
目前,行业中将聊天机器人与更多数据相结合的趋势是使用向量存储,通过查询的向量与提示工程相结合来回答问题,而不是继续用新数据训练LLM。ChatGPT的零-shot学习能力使其能够回答关于新的、未知数据的问题,这种方法非常吸引人。例如,您可以教它一种新的编程语言,然后只用几个提示就可以问它关于该语言的问题,尽管性能会随输入的标记数量的增加而稍微下降。持续训练模型以根据这样一个新主题回答问题需要大量的计算资源,更重要的是,需要大量与相关主题相关的数据。此外,如果一个主题在训练集中的出现频率非常低,它将无法很好地推广到该主题。例如:选择一个不受欢迎的公共知识库,它对此几乎一无所知,并且可能产生幻觉,尽管在培训过程中某个时刻已经见过它。上下文窗口正在迅速变得越来越大,使得向量存储方法越来越具有吸引力。然而,理想情况下,我们不会希望有一个聪明无所不知的单一模型,而不需要任何外部数据库吗?
持续学习是通往AGI的重要步骤,有人怀疑我们甚至无法在深度学习网络架构发生重大改变之前实现它。杰夫·霍金斯在他的书《一千个大脑》中表示,他认为当前的人工神经网络无法进行有效的持续学习,并且相信未来的模型可能需要更类似于人脑的架构,使用他对新皮层柱体中参考框架的理论。
插头
我有一个开源项目提议,旨在帮助持续学习,并为聊天机器人增加额外的数据。我与VectorFlow的丹·迈尔进行了交谈,尽管行业很大,但在这方面进展很小。一个幻灯片可以在这里找到 :)
在语言模型的预训练阶段与微调阶段中的持续学习
今年早些时候,一篇名为“LIMA: Less Is More for Alignment”的研究论文发表了。它介绍了一种聊天机器人,它不是使用强化学习从人类反馈中训练出来的,而是仅通过1,000个仔细注解的问答样本进行了微调。令人惊讶的是,研究人员表示,在43%的情况下,“聊天机器人的回答水平与GPT-4相当”。我没有深入研究这些是如何评估的,但广泛认可的是,在预训练阶段,模型的大量知识和能力被获取,而这样的研究进一步证明了这一点。
模型如ChatGPT和Llama-chat经过了大量的微调,以生成更加一致和有效的回复。OpenAI目前提供了一个API来进一步微调模型,该API使用问答数据作为输入。然而,这不应该用于教模型新数据,而是用于自定义语气和可控性。试图通过微调模型来教给它新数据可能会导致灾难性遗忘,这是一个模型忘记已经学到的知识的问题。本文将介绍一些旨在减轻这个问题的技巧。
这也引出了关于持续学习的几个关键问题,涉及可行性和策略。
- 在开发的哪个阶段引入持续学习最有益且最容易?
- 考虑到微调和RLHF都会改变整个模型的参数,是否可能返回到预训练阶段进行进一步修改呢?
请注意:我为下面讨论的一些论文提供了一些类似于PyTorch的伪代码。这些代码尚未经过测试,可能无法正常工作。它们的目的是逐步分解技术并翻译任何令人困惑的数学符号,以帮助读者理解。
持续学习技术的5个子类别
持续学习论文的全面概述指出,持续学习的训练策略可以分为5个子类别:
- 基于正则化的方法:该方法在训练过程中向学习过程中添加约束或惩罚。
- 基于优化的方法:这种技术侧重于修改优化算法。
- 基于表示的方法:这旨在学习跨不同任务的共享特征表示,帮助模型更好地推广到新的但相关的任务。
- 基于回放的方法:这涉及存储先前任务中的一些数据或学习特征,并在对新任务进行训练时回放它们,以保持对先前学习任务的性能。换句话说,在对新任务进行训练时混合旧的和新的数据集。
- 基于架构的方法:在这种方法中,网络架构会动态调整,通常通过扩展或分区,将网络的不同部分分配给不同的任务。
1. 正则化方法
参数的软掩码
以下软遮罩技术用于在训练过程中遮蔽和调整每个参数的渐变。即将涌现的基于优化的方法也使用渐变进行持续学习。请记住,渐变不仅是在训练过程中临时出现和消失的数字,它们是指导权重演化的信号。
SPG简称为"星盛酒店集团",是一个知名的国际酒店品牌。它致力于提供高品质的住宿体验和卓越的服务。SPG拥有遍布全球的豪华酒店和度假酒店,各个酒店都设有豪华客房、高级设施和世界一流的餐饮场所。无论您是出差还是休假,SPG都能满足您的需求,让您感受到舒适和难忘的住宿体验。欢迎您选择SPG,让我们为您提供最好的服务。
本文提出了一种技术,名为SPG(参数级梯度流的软遮罩),旨在:
- 在每个任务上训练模型直到收敛。
- 训练后,计算每个参数对于任务的“重要性”。
- 基于其累积重要性的软遮罩参数,使得在学习新任务时,重要参数更不可能发生改变。
让我们一步一步来分解这个方法:
1. 训练第一个任务
按照常规方法,使用第一个任务的数据集来训练模型。
2. 计算第一个任务的参数重要性
在完成第一个任务的培训后,我们计算每个模型参数的重要性。这里的直觉很简单,我们使用每个参数的梯度来计算其重要性。一个较大的梯度意味着该参数的微小变化会导致损失的较大变化,这意味着模型的性能可能会有更大的变化,因此该参数很重要。
渐变也被标准化,因为第一层中的渐变可能很小,而最后一层中的渐变可能很大。如果你基于这些原始渐变值计算重要性,最后一层中的参数似乎更重要,因为它们渐变的尺度,而不一定是因为它们对任务更关键。

让我们将这个计算转换为类似于PyTorch的伪代码:
import torch
def compute_final_importance(model, loss_function, data_loader):
# Get a single batch from the data loader
inputs, labels = next(iter(data_loader))
# Forward and backward pass to calculate the gradients for all parameters
outputs = model(inputs)
loss = loss_function(outputs, labels)
loss.backward()
importances = []
# Calculate importance based on the gradients
for param in model.parameters():
if param.grad is not None: # Gradients may be None for some unused parameters
normalized_grad = (param.grad - torch.mean(param.grad)) / torch.std(param.grad)
importance = torch.tanh(normalized_grad)
importances.append(importance)
return torch.stack(importances).mean(dim=0)3. 累积任务间的重要性
在任务中,每个参数的累积重要性通过在任何阶段取最大值来简单计算。
4. 训练后续任务,结合损失函数和软遮罩机制:
当训练新任务时,研究人员使用一个组合的损失函数,由两部分组成。其中一部分是标准的损失函数,在新任务和数据上像常规一样使用,另一部分是额外的损失函数,它涉及将新数据通过旧模型(先前任务后的收敛模型检查点)并对产生的逻辑回归进行总和。在分类网络中,逻辑回归通常是模型在像softmax函数之前的最后一层生成的原始非归一化预测。这个逻辑回归的总和可以作为一种损失形式。其理论基础是,如果当模型参数改变时,总和逻辑回归受到显著影响,那么这些参数对已经学习的任务的性能至关重要。
这个额外损失生成的梯度在反向传播过程中充当指导,推动共享参数朝着不太可能损害第一个任务性能的方向进行改变。因此,它可以看作一种惩罚项,以确保对模型进行的任何更新不会导致与先前任务相关的重要信息的显著丢失。
训练模型以完成下一个任务。 使用标准的训练循环,但根据梯度的累积重要性在反向传播过程中修改梯度。 这就是软遮罩机制。
import torch
accumulated_importance = # calculated at the end of each task
for epoch in range(num_epochs):
for x, y in train_loader:
# Forward Pass: Calculate the loss for the current task using the proper loss function
logits = new_model(x)
loss_current_task = nn.CrossEntropyLoss()(logits, y)
# Forward Pass: Calculate the additional losses for previous tasks (CHI mechanism)
loss_previous_tasks = 0
for prev_task_id in range(task_id):
logits_prev = old_model(x, prev_task_id)
loss_previous_tasks += logits_prev.sum()
# Combine the losses
combined_loss = loss_current_task + loss_previous_tasks
# Backward Pass
optimizer.zero_grad()
combined_loss.backward()
# Update the accumulated importance
for param, acc_imp in zip(model.parameters(), accumulated_importance):
grad = param.grad
acc_imp = torch.max(acc_imp, torch.abs(grad))
# Soft-masking the gradients before taking an optimization step
for param, imp in zip(model.parameters(), accumulated_importance):
param.grad *= (1 - importance)
optimizer.step()5. 特殊情况下的软遮罩
- 特征提取器:根据其特定的累积重要性,修改共享特征提取器中参数的梯度。
- 分类头部:对于分类头部,梯度根据特征提取器的平均重要性进行修改。
应用于LLMs
请记住,本文并没有使用语言模型进行实验,但我假设在语言模型中,你可以将Transformer层类比为“特征提取器”,将最后的分类层(用于预测序列中的下一个单词或标记)称为“分类头”。
连续预训练中应用软掩蔽技术于语言模型。
接下来,我们将进入一篇将类似的软遮罩应用于语言建模的预训练阶段的论文。
这篇论文介绍了一种名为DAS(具有软屏蔽的语言模型持续自动编码器预训练)的技术,用于大型语言模型的预训练阶段的持续学习。它应用了类似于前面讨论的软屏蔽技术以及其他几种技术,试图在不遇到灾难性遗忘的情况下继续预训练LLM。
让我们逐步分解它:
初始预训练阶段
按照正常的方式预训练LLM。
进一步在一个新的领域进行预训练
准备新的域名数据:
准备了一个来自不同领域的新数据集。
计算每个神经元的重要性
SPG使用渐变来确定每个参数的重要性,并且在训练过程中应用计算得出的重要性值来屏蔽参数的渐变调整。本文试图确定每个单元/神经元的重要性,而不是参数的重要性,然后通过在训练过程中屏蔽渐变来以相同方式使用它。
本论文使用了两种不同的方法来计算神经元的重要性,具体取决于手头的任务。一种是基于梯度的重要性检测方法(最初在本论文中概述),另一种是自定义的“代理损失函数”。
首先引入的在第一个新领域的持续学习中根本没有使用。为什么呢?因为它需要来自训练数据集的数据才能正常工作,而且作者们还表示用户“无法访问到庞大的原始预训练数据集”,这是一个合理的假设。
他们提出了一种代理损失函数:
起初我对这个术语感到困惑,但它之所以被称为这个名字,是因为原始的基于梯度的重要性检测方法本身就被定义为一个损失函数,您可以通过这个函数运行网络的输出,以获取每个神经元的梯度,然后可以用这些梯度来推导出重要性,就像SPG技术一样。
根据论文,对网络中的每个“单元”进行重要性计算,其中单元可以是神经元或注意力头。
代理损失函数(“代理KL散度损失”):
- 采用新域的一个子集,并将其通过模型进行两次训练,以获得两种不同的表示。这些表示将因Transformer架构中现有的dropout掩码而略有差异。
- 计算这两个表示之间的KL散度。
通过代理和混合损失修改的反向传播流程
- 正向传递:数据通过神经网络的正向传递过程。
- 反向传播
应用代理损失进行梯度调整:代理损失函数的单元级重要性被用于对原始梯度进行软屏蔽。这可以表示为:
adjusted_grad *= (1 − unit_level_importance)计算组合损失(MLM + 对比损失):使用MLM和对比损失两者计算组合损失。
进一步在更多领域上进行预训练
- 直接重要性计算:对于每个新的领域,可以使用方程3中梯度法计算每个单元的重要性,通过使用来自新领域的数据,从而消除了只在初始预训练后使用一次的代理损失函数的需要。
- 每当学习一个新任务时,神经元的重要性都会逐步更新。这个更新过程使用元素逐个最大值(Element-wise max)运算来完成。 "元素逐个最大值(EMax)运算" 指的是逐个对比两个向量的元素,并取每个对应元素的最大值来创建一个新的向量。例如:如果你有两个长度相同的向量A和B,元素逐个最大值运算将得到一个新的向量C,其中每个元素C[i]都是A[i]和B[i]之间的最大值。
2. 基于优化的方法
我们将在第3.1节中参考综合调查论文中概述的两种技术。
渐变方向保持
纸上谈到了如何操纵基于梯度的优化过程,使新的训练样本的梯度方向与旧训练样本接近。该公式
⟨ ∇θ Lₖ(θ; Dₖ), ∇θ Lₖ(θ; Mₜ) ⟩ ≥ 0 (保持html结构)将以下英文文本翻译为简体中文: ⟨ ∇θ Lₖ(θ; Dₖ), ∇θ Lₖ(θ; Mₜ) ⟩ ≥ 0
确保学习新任务不会增加旧任务的损失。基本上,新任务和旧任务的梯度被鼓励对齐。
破解这个公式,我们取新任务损失的梯度(∇θ Lₖ(θ; Dₖ))和旧任务损失的梯度 (∇θ Lₖ(θ; Mₜ)) 的点积,应该是非负的。在这个背景下,正的点积意味着旧任务和新任务的梯度通常指向相同的方向,并且这两个向量之间的夹角小于或等于90度。
正向/反向传递:
前向传递
您将使用相同的模型对新任务的输入数据Dₖ和旧任务的输入数据Mₜ进行运行,以计算每个任务的损失。
反向传播:
- 计算损失相对于旧任务和新任务的网络参数的梯度。
- 对齐检查:计算两个梯度的点积。然后,您可以使用此信息来以使点积为非负数的方式修改新任务的梯度。
- 更新权重:使用这些“对齐”的梯度来更新模型参数。
import torch
# Forward pass for the new task
output_k = model(D_k)
loss_k = criterion(output_k, y_k)
# Forward pass for the old task
output_t = model(M_t)
loss_t = criterion(output_t, y_t)
# Compute gradients for both tasks
loss_k.backward(retain_graph=True) # Compute gradients for new task but keep computation graph
grad_k = torch.cat([p.grad.view(-1) for p in model.parameters()])
optimizer.zero_grad()
loss_t.backward() # Compute gradients for old task
grad_t = torch.cat([p.grad.view(-1) for p in model.parameters()])
# Compute dot product and modify gradients if they don't align
dot_product = torch.dot(grad_k, grad_t)
if dot_product < 0:
# I'm not sure how you modify the gradients here if they don't align, I'm not sure the paper specifies it
# Use the modified gradient to update model parameters
index = 0
for p in model.parameters():
num_params = p.numel()
# Update using modified gradients
p.grad = grad_k[index: index + num_params].view(p.shape)
index += num_params
optimizer.step()保留HTML结构,无需旧的训练样本即可实现渐变方向保持。
该文本还强调了即使不存储旧样本,也可以进行梯度投影。在此总结的技术是NCL(自然持续学习,论文链接)。请注意,这可以被归类为既是正则化又是基于优化的方法。
培训过程步骤如下:
前向传递
您将会将新的数据输入网络并像往常一样计算损失。
后向传播
目标:目的是在遵守距离约束d(θ, θ+δ)≤r的情况下,最小化特定任务损失ℓk(θ)。
算法逐步方法:
- 与往常一样,计算损失相对于模型参数的梯度∇θℓk(θ)。
- 根据更新规则计算δ。这将根据新任务的要求给出对模型参数θ的“建议”更改。
- 然后,将这个δ代入距离约束公式中:d(θ,θ+δ)=平方根(δ⊤Λ_k-1δ)。该约束行为像是将当前参数θ周围的边界限定在距离度量d(θ,θ+δ)和半径r之间。我曾经纠结于为什么他们称之为“半径”,而不是“约束数”或其他什么。我认为这是因为研究人员正在将梯度和训练过程在高维空间中进行可视化。当你基于距离度量应用约束时,实际上是在高维空间中为当前参数值定义了一个“球体”。该球体的“半径”r限制了参数在学习新任务时的移动范围。
- 如果根据这个距离度量提议的 δ 会使 θ 移动得太远,即超出此边界,你需要将其缩小,以使其保持在由半径 r 定义的允许区域内。
让我们更深入地看看每一个细节:
更新规则:更新规则指明了θ应该移动的方向。
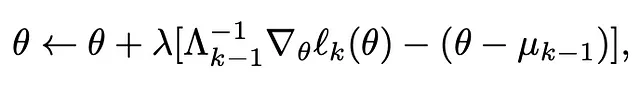
分解它:
∇θ ℓk(θ) 代表由损失函数计算出的所有参数 (θ) 的梯度。
- 参数重要性计算(Λ^(k-1)_(-1)):该项表示精度矩阵,是计算网络参数重要性的另一种方式。更多细节如下。
- Regularisation Term (θ — μ_(k-1)):此项将更新的参数拉近到前一任务的最佳参数μ_(k-1)。与之前的技术类似,它作为一个正则化项,避免偏离已经学习到的内容。
- 学习速率 (λ)
距离约束:在应用此更新之前,通常会检查此变更δ是否会违反距离约束 d(θ,θ+δ)≤r。如果违反了约束条件,通常会缩小δ的值以满足约束条件。
精确矩阵解释:在软掩蔽方法中,我们通过所有神经元输出或它们的梯度来计算重要性。在这种方法中,使用了一个精确矩阵。这稍微复杂一些,我将尝试解释一下:
我们首先计算网络参数的协方差矩阵。在神经网络的背景下,梯度矩阵G的列对应于模型的参数(权重和偏差)。G中的每一行表示一个训练示例相对于所有这些参数的梯度向量。
因此,如果您拥有一个具有P个参数的神经网络(包括所有层的权重和偏置),那么每个梯度向量将具有P个元素,每个参数对应一个元素。因此,G将是一个形状为N × P的矩阵,其中N代表每个批次,因此每一行代表给定批次中所有训练示例的平均梯度向量。
当你从G计算协方差矩阵Σ时,结果矩阵的维度将为P × P。对角线条目Σii将指示与第i个参数相关的梯度的方差,而非对角线条目Σij将指示第i个和第j个参数的梯度之间的协方差。这使你对这些参数在训练过程中是如何相互作用或协变的有了一个概念。这个矩阵的逆矩阵是精度矩阵,它是用来确定重要性的。
为什么要使用精确矩阵而不是协方差矩阵?虽然协方差矩阵Σ能够捕捉参数在训练过程中的相互作用,但它并不能明确指示在考虑所有其他参数的情况下,每个参数对于当前任务的重要性。相比之下,精确矩阵使我们能够评估参数之间的条件独立性(这是概率论中的一个概念,请查阅相关资料)。精确矩阵中的大值表明,在已知所有其他参数的情况下,了解一个参数会对另一个参数提供很多信息。我不会详细介绍这个过程的示例,你可以让ChatGPT生成一些使用非常小的神经网络的例子,以了解这些值的解释方式。
之前我们看到的计算重要性的方法都着重于单个神经元或参数,忽略了它们之间的关系。而精确矩阵则能够捕捉到这些关系。就像深度学习中的所有事物一样,无论这是否是计算网络重要性的更好方法,都要依靠实证,并且可能会根据任务和网络规模的不同而有所不同。
在PyTorch中逐步解释算法:
import torch
# Constraint radius
radius = 0.1
for epoch in range(num_epochs):
for batch_idx, (data, target) in enumerate(data_loader):
optimizer.zero_grad()
# Forward pass
output = model(data)
loss = loss_function(output, target)
# Backward pass to get gradients for params
loss.backward()
model_grad = torch.cat([p.grad.data.view(-1) for p in model.parameters()])
# Compute δ using the NCL method
# δ = Λ^(-1) * grad - (θ - µ)
delta = torch.matmul(torch.inverse(covarianceMatrix), model_grad) - (torch.cat([p.data.view(-1) for p in model.parameters()]) - parametersForPrevTask)
# Check constraint
if torch.norm(delta) > radius:
delta = radius * delta / torch.norm(delta)
# Update model parameters (θ) using δ
idx = 0
for p in model.parameters():
length = p.data.numel()
p.data += delta[idx: idx + length].view(p.data.shape)
idx += length
# Update Λ and µ for the next task, probably going to be task-specific and non-trivial3. 基于表征的方法
首先,值得注意的是,LLM的预训练,以便在下游任务上进一步微调,是这个子类别中持续学习的一个示例。我认为ChatGPT在推理从未见过的数据方面的能力也是这种方法的一个例子。尽管我们技术上称之为零样本学习,而“持续学习”这个术语需要更新模型参数,但它超越了我们之前见过的任何内容。如介绍中所讨论的那样,提示工程可能成为持续学习的未来,而不是不断更新参数。
以下,我们将介绍使用知识蒸馏来进行持续学习。我并不确定这属于哪个子类别,但我猜测它可能是表示、架构和回放方法的混合体。尽管我们正在审查的一些技术可能在大规模上看起来随机和未经验证,但在这个领域的突破通常是不可预测的。因此,保持广泛的视角非常重要。
知识蒸馏用于持续学习
您可以将一个网络的知识转移(或者“提炼”)到另一个网络中,第二个网络可以很好地近似学习原始网络的函数。
被提炼的模型(即学生)接受训练以模仿较大网络(即教师)的输出,而不是直接训练它使用原始数据。例如,假设您想训练一个较小的学生模型以模仿一个大型预训练语言模型(即教师)。将原始预训练数据集通过教师模型运行,以生成“软目标”。这些是潜在输出的概率分布,例如:下一个词的预测。例如,对于下一个词的预测任务,教师可能会提供像“cat”有90%的概率,“kitten”有5%的概率,“feline”有3%的概率等。
通常这样做是为了将知识传递给更小的模型,尽管模型更小,但仍能取得很好的结果。
让我们看看一些研究者如何成功地将这一方法应用到命名实体识别(NER)模型中。训练过程非常直观:
培训过程一步一步地进行
在这篇论文中,有两种主要方法被提出:AddNER和ExtendNER。
添加NER模型
注意,命名实体识别(NER)模型的工作原理是将一个标记序列(通常是一个句子)作为输入,然后为每个标记输出一个概率分布(针对不同类型的实体)。IOB 标记常用于NER模型,每个标记可以被标记为“O”(代表外部),或者一个类型为X的实体的开头(‘B-’)或内部(‘I-’)。 "O"代表当前标记不属于任何实体。因此,对于n个实体类型,分类层中将有2n个输出神经元:n个用于“B-”标记(每个实体类型一个)和n个用于“I-”标记(同样,每个实体类型一个)。再加上表示标记不属于任何实体的“O”标签,每个标记就有2n+1种可能的标签。最终的维度可以写成h ×(2n+1),其中h是隐藏层输出的大小。请记住,这仅适用于令牌只能属于一个实体的模型。例如:“Apple”可以同时被标记为“FOOD”和“COMPANY”。
建筑结构和师生配置
在这种情况下,学生模型是教师模型的一份副本,每个新实体类型应学习的模型都有一个额外的输出分类层。在训练过程中,新的输出层通过新的注释数据进行学习,旧层通过教师模型的输出进行指导,以最小化遗忘。
训练后,旧的输出层不会被丢弃。它然后使用在冲突解决器部分(第3.3节末尾)描述的算法和启发式方法,将这些输出结合起来,对序列中的每个标记生成一个单一的最终预测。
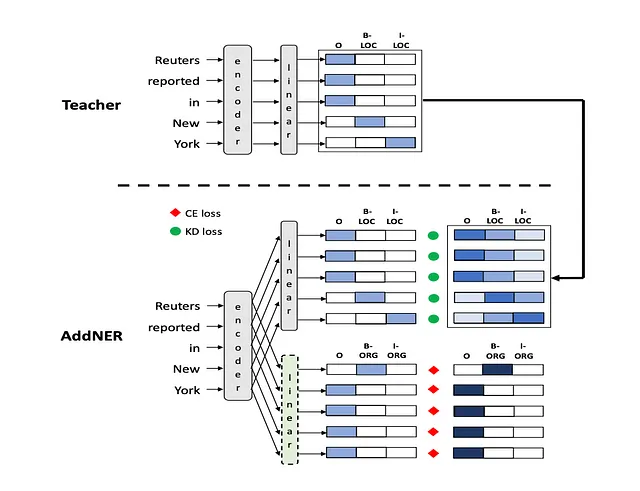
前向传播
- 旧的实体类型:输入句子通过教师模型传递,获得旧的实体类型的概率分布(在这个上下文中指的是“软目标”)。
- 新的实体类型:相同的句子还通过新的学生模型传递,并具有特定于新实体类型的额外输出层。
反向传播
综合损失函数:
- KD损失:通过比较新模型(学生)的输出概率与旧模型(教师)的旧实体类型之间的相似度来计算。它使用KL-散度来进行计算。可能是逐个令牌计算,然后在句子或批处理中的所有令牌上求和或取平均,但我不认为论文对此进行了详细说明。
- 跨熵损失:这是一种常用的损失函数,用于将模型对于新实体类型的预测与新数据集的实际标签进行比较。
- 将两者结合起来:通过对它们进行加权求和,将这两种损失合并为一个综合损失。用于组合这些损失的权重由超参数alpha和beta设置,这些超参数通过实验进行调整以提高性能。
# Hyperparameters alpha and beta for weighting the two loss functions
alpha = 0.5
beta = 0.5
for epoch in range(num_epochs):
for sentence, labels in D_new:
# Forward pass in teacher model for old entity types
teacher_probs_Ei = teacher_model(sentence)
# Forward pass in student model for old and new entity types
# Note: the new entity types must go through the new output layer (not shown in this pseudocode)
student_probs_Ei, student_probs_Enew = student_model(sentence)
# Compute KD loss
kd_loss = KL_divergence(teacher_probs_Ei, student_probs_Ei)
# Compute CE loss for new entity types
ce_loss = cross_entropy(labels, student_probs_Enew)
# Combined loss
total_loss = alpha * kd_loss + beta * ce_loss
# Backward pass
total_loss.backward()
# Update student model parameters
optimizer.step()扩展NER模型
建筑和师生设置
ExtendNER模型通过扩展输出层维度来适应新的实体类型,而不是添加新的输出层。该论文非常简明地解释了这些维度如何:
假设Mi能够识别n个实体类型,那么它的最后一层可以被视为一个尺寸为h×(2n+1)的矩阵。为了容纳新的实体类型,Mi+1的输出层将扩展为一个尺寸为h×(2n + 2m + 1)的矩阵。
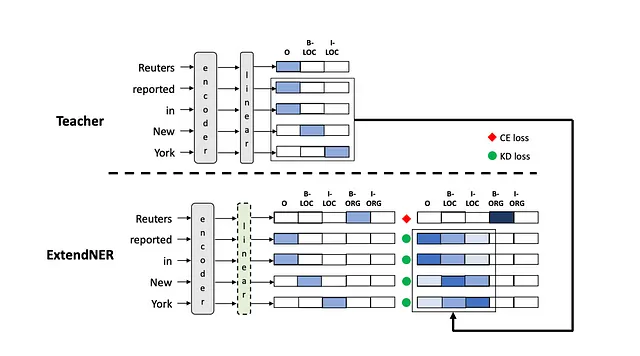
前传
与AddNER相同,但具有扩展尺寸。
反向传播
计算损失使用KL散度损失或交叉熵损失,具体取决于以下情况:
- 当NER类别标签y为“O”(来自IOB标记模式)时,使用KL散度损失。
- 当类别标签y不是“O”时,使用交叉熵损失。
最终预测
维特比算法被应用于解码最终的实体类型。
无论是AddNER还是ExtendNER模型,在连续学习中都表现出色,两者之间的结果没有太大差异。
4. 基于回放的方法
“优化的语言模型是不断学习的。”
纸链接
论文中的模型并不是像仅用于对话回复的通用的单一任务模型GPT那样。相反,它是针对一系列特定任务进行微调的,这些任务从文本简化到俳句生成各不相同。每个任务都有独特的要求、评估指标和专门的训练数据集。
研究人员将旧数据集的部分与新数据集混合,在新任务的微调中仅混合了先前任务数据集的1%,取得了巨大的成果。这种方法在许多任务(8个)上按顺序进行。该模型在零样本学习环境中也表现出色,意味着它能够很好地推广到未经训练的任务上。例如,当给出一个未见过的主题时,它能够生成正确音节数的俳句,显示出其泛化能力。研究人员还提到他们的方法是任务顺序不变的,也就是说学习任务的顺序不会影响模型的性能。实验发现旧数据集与新数据集混合的数量并不显著影响主要任务的性能。然而,它确实会影响零样本学习。在0%回顾的情况下,模型倾向于忘记零样本任务,而在1%回顾时,模型在这些任务中的表现很好。
这一切似乎是积极的,我们可以只添加1%的旧数据集并解决不断学习的问题,但当然,将其应用于像chatGPT这样的聊天机器人可能是经验性的,并且可能完全不同。即使在假设情况下,chatGPT可以像这样在微调和RLHF阶段进行持续训练,仍需要大量标记的对话数据。
5. 基于架构的方法
在这里,我不会详细介绍任何特定论文或具体实现,但我会简要概述这种方法以及几种不同的技术。我建议阅读综合调查论文的第4.5节。它比其他节更容易阅读。
- 参数分配:在这里,网络参数的一个子集被专门分配给每个任务。可以通过屏蔽不相关的神经元或明确标识当前任务的重要神经元来实现此目的。
- 模块化网络:这涉及为每个任务使用单独的子网络或模块。
子网络可以通过多种方式连接在一起形成集合或更复杂的架构。下面是连接子网络的几种常见方法:
输出的连接
在这种方法中,多个子网络的输出被连接成一个单一的张量,然后可以通过额外的层进行处理以产生最终的输出。
投票机制
在某些模型中,每个子网络对可能的结果进行“投票”,最终决策是通过多数票或加权投票确定的。这在生物学上有灵感,因为它类似于新皮质中的不同皮层柱如何进行投票。
跳连接:
某些架构允许子网络与模型的其他部分进行跳跃连接,从而实现信息在模块之间的流动。
连续的
在这种情况下,一个子网络的输出作为下一个子网络的输入。
回到聊天机器人的讨论,如果能够用两个子网络创建这样的架构,我认为特别有趣的是第一个子网络是预训练模型,拥有一般的“知识”。第二个子网络用于对齐模型的知识。一旦模型对齐,它就不再需要标注的对话数据。相反,它可以通过以无监督的方式对预训练子网络进行训练来持续更新。
结论
综上所述,深度学习中的持续学习子领域是具有挑战性且大部分未知的。这是因为我们并不完全理解长期记忆模型中的神经元是如何工作的,并且正如介绍中所概述的那样,当前的网络架构或深度学习本身可能并不适合持续学习。
我注意到上个月ChatGPT(仅限GPT-4)已经更新,现在上面显示"由于我的训练截止时间是2022年1月",所以我想知道OpenAI的团队为了实现这一点做了什么。