使用ChatGPT构建MLOps的人工智能知识体系
收集、清洁并使用ChatGPT构建MLOps的人工智能知识库。
代码
给出的代码提供了一种全面的解决方案,用于基于人工智能的知识库,聚焦于机器学习运营(MLOps),利用YouTube的内容。以下是详细的解释。
部分1:数据收集
我们使用YouTube播放列表从生产研讨会的两个LLMs收集MLOps的视频。
我们收集并下载所有的视频,并将它们存储在Google云盘上以便稍后进行处理。
该代码位于在Google Colab中开发的Jupyter笔记本中。也提供了原始文件的链接。
Google Drive 挂载:
from google.colab import drive
drive.mount('/content/gdrive')此部分将 Google Drive 挂载到 Colab 环境中,允许数据直接保存到 Google Drive。
2.目录设置:
KB_FOLDER = "/content/gdrive/Shareddrives/AI/MLOpsKB"
...
if not os.path.exists(TRANSCRIPTS_WHISPER_FOLDER):
os.makedirs(TRANSCRIPTS_WHISPER_FOLDER)在这里,设置了用于存储YouTube音频、文稿等各种数据的路径。如果这些目录不存在,则会创建它们。
3. 抓取YouTube播放列表:
!pip install -q scrapetube
import scrapetube
...
print(unique_video_ids)scrapetube库用于从两个YouTube播放列表中提取视频ID。然后将这些ID组合并去重,形成一个唯一视频ID列表。
4. 本地存储视频 ID:
with open(f'{YT_AUDIO_FOLDER}/videos.txt', 'a') as f:
f.write(f'{video_id}\n')所有唯一的视频ID都存储在本地文件中,以便进一步处理。
5. 从YouTube下载音频:
!pip install -q yt-dlp
import yt_dlp as yt
...
print(counter, "of", total_videos, ": Existing file: " + path)本节使用yt-dlp库从YouTube下载每个视频的音频。如果视频的音频已经存在,则跳过下载。
第二部分:语音转文本
这部分专门用于将先前收集的音频文件转录为文本。让我们详细了解一下:
我们现在使用WhisperJAX将音频文件转换为文本。 WhisperJAX能够加快转换处理速度。
1. 初始设置和运行时检查:
# -*- coding: utf-8 -*-
...
print('You are using a high-RAM runtime!')让我们检查一下运行环境是否利用了GPU并且具有高内存。
2. Google 雲端硬碟掛載:
from google.colab import drive
drive.mount('/content/gdrive')本节将Google Drive挂载到Colab环境,实现直接保存和检索来自Google Drive的数据。
3. 目录验证和创建:
KB_FOLDER = "/content/gdrive/Shareddrives/AI/MLOpsKB"
...
if not os.path.exists(BOOK_FOLDER):
os.makedirs(BOOK_FOLDER)脚本设置了各个目录的路径,这些目录将存储知识库和相关数据。如果这些目录尚不存在,脚本将创建它们。
4. 转录设置:
import jax
jax.devices()
...
pipeline = FlaxWhisperPipline("openai/whisper-large-v2", dtype=jnp.bfloat16, batch_size=16)在这里,导入所需的库,并建立Whisper管道。Whisper是OpenAI的自动语音识别(ASR)系统,将用于转录音频文件。我们还使用JAX来加速ASR流水线。Jax是一个专为高性能ML研究设计的Python库。Jax只是一个数值计算库,就像Numpy一样,但具有一些关键的改进。它由Google开发,并在Google和Deepmind团队内部使用。
5. 加载视频ID:
unique_video_ids = []
...
unique_video_ids.append(curr_place)视频ID存储在前面的部分中,被加载到unique_video_ids列表中进行处理。
6. 转录音频文件:
import re, json, os
def transcribe_file(filename):
...
return transcription
transcriptions = []
...
with open(transcript_filename, 'w') as f:
f.write(json.dumps(transcription))每个视频ID对应的音频文件都使用Whisper流水线进行转录。转录结果以JSON格式保存在Google Drive上,以便进行方便的检索和进一步处理。
向向量存储添加数据
这个特定的部分专注于设置向量数据库和插入数据,这对于高效查询和检索信息至关重要。让我们分解一下代码:
运行时检查
try:
gpu_info = !nvidia-smi
...
print('You are using a high-RAM runtime!')脚本首先检查运行环境,确定是否已连接到GPU,并且内存的可用情况。这非常重要,因为某些操作,尤其是向量计算,受益于GPU加速。
2. 目录配置:
from google.colab import drive
drive.mount('/content/gdrive')
...
if not os.path.exists(TRANSCRIPTS_WHISPER_FOLDER):
os.makedirs(TRANSCRIPTS_WHISPER_FOLDER)在这里,Google Drive 被挂载以访问已保存的数据,并建立了与知识库相关的各个目录的路径。如果某些目录不存在,则会被创建。
3. 依赖安装:
!pip install -q langchain
!pip install -q openai
!pip install -q tiktoken已安装了必要的Python软件包,包括langchain(可能是用于语言处理链的库),openai和tiktoken。
OpenAI设置:
os.environ["OPENAI_API_KEY"] = "" # Add your OpenAI API key here
MODEL = "gpt-3.5-turbo-16k-0613"为OpenAI设置了一个API密钥,并选择了一个特定的ChatGPT模型进行操作。
5. 向量数据库初始化:
vectorstore = 'FAISS'
...
else:
!pip install -q faiss-cpu
from langchain.vectorstores import FAISS代码支持两种向量数据库选项:Pinecone和FAISS。这里选择并设置了FAISS向量数据库。
6. 文本分块和向量嵌入:
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0, separator="\n")
...
if os.path.exists(f"{YT_DATASTORE}/index.faiss"):
...
else:
vector_store.save_local(f"{YT_DATASTORE}")这一段是关键的。代码首先将文本分成可管理的块。然后,对于每个块,创建向量嵌入。然后,这些嵌入要么合并到现有的向量数据库中,要么保存为新的数据库。向量嵌入主要将文本数据转换成可以高效查询和比较的格式。
7. 将块存储以供后续处理:
import json
...
with open(f'{TRANSCRIPTS_TEXT_FOLDER}/' + video_id + '_large.txt', 'w') as output_file:
output_file.write(text)该部分从文件中读取视频ID,加载它们的字幕,然后将每个字幕的文本内容保存到一个指定的文件夹,以供后续使用。
使用ChatGPT查询数据
本部分专注于查询矢量数据库,特别旨在使用ChatGPT检索相关信息。让我们深入了解细节:
我们现在可以使用ChatGPT来查询MLOps数据。
初始设置:
from google.colab import drive
drive.mount('/content/gdrive')这一部分准备环境,从Google Colab笔记本中生成并挂载Google Drive以访问存储的数据。
2. 目录验证和创建:
KB_FOLDER = "/content/gdrive/MyDrive/MLOpsKB"
...
if not os.path.exists(TRANSCRIPTS_WHISPER_FOLDER):
os.makedirs(TRANSCRIPTS_WHISPER_FOLDER)该脚本建立了各个目录的路径,其中包含知识库和相关数据。如果目录不存在,则会创建该目录。
3. 加载依赖项:
!pip install -q langchain
...
!pip install -q cached_property这里安装了必要的Python包,这些包对于后续操作非常重要,包括langchain,openai,tiktoken和其他一些包。
4. 向量数据库设置:
vectorstore = 'FAISS'
...
else:
print(f"Missing files. Upload index.faiss and index.pkl files to data_store directory first")代码支持两个向量数据库选项:Pinecone和FAISS。在此示例中,选择了FAISS。代码检查所需的数据存储是否存在;如果不存在,则提示用户上传所需的文件。
5. OpenAI 设置和提示配置:
os.environ["OPENAI_API_KEY"] = "" # Add your OpenAI API key here
...
prompt = ChatPromptTemplate.from_messages(messages)OpenAI API键已设置,并选择了特定的ChatGPT模型(在本例中为gpt-3.5-turbo-16k-0613)。还定义了一个提示结构来指导AI的回复。
6. 初始化检索链:
llm = ChatOpenAI(model_name=MODEL, temperature=0)
...
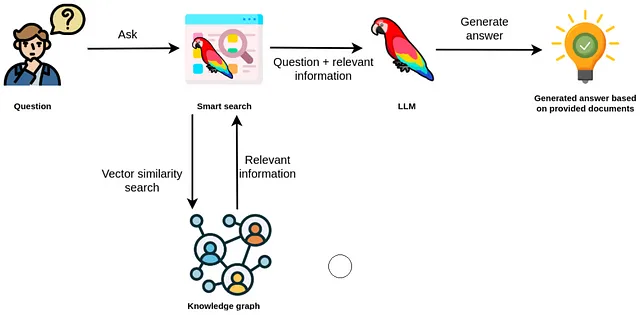
chain = RetrievalQAWithSourcesChain.from_chain_type(...)这个部分通过建立一个链接查询过程、向量存储和ChatGPT模型的链条,初始化检索过程。目标是让用户能够查询知识库并获得附加来源的回答。
7. 查询知识库:
query = "How can I learn about MLOps?"
...
print(f"Content: {document.page_content}")链条被用于查询知识库。结果将会打印出来,并附带来源(在本例中为YouTube视频链接和相关元数据)。提供了多个示例查询,包括询问有关学习MLOps、MLOps的关键组成部分以及MLOps社群中的领导者等。
构建数据的用户界面
在这篇博客文章中,我们将探索使用Streamlit和OpenAI开发的基于人工智能的聊天界面。该界面根据MLOps视频提供用户洞见和建议。让我们深入了解具体细节:
导入必需的模块:
import os
import re
import openai
import streamlit as st
from langchain.chat_models import ChatOpenAI
...
from streamlit_player import st_player导入了应用程序所需的核心库和模块。
2. 配置:
openai.api_key = st.secrets["OPENAI_API_KEY"]
os.environ["PROMPTLAYER_API_KEY"] = st.secrets["PROMPTLAYER"]
MODEL = "gpt-3.5-turbo-16k-0613"API密钥已配置,选择所需的GPT模型。
3. 文本清理功能:
def remove_html_tags(text):
...
def remove_markdown(text):
...
def clean_text(text):
...定义了一套实用函数,用于去除HTML和Markdown格式,确保视频内容呈现清晰。
4. Streamlit界面配置:
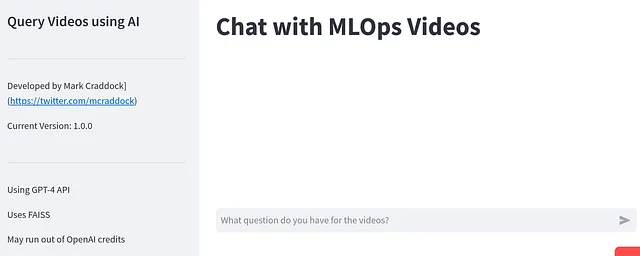
st.set_page_config(page_title="Chat with MLOps Conference Videos")
st.title("Chat with MLOps Videos")
...
st.sidebar.divider()Streamlit用户界面经过定制,包括相关标题、侧边栏和版本详细信息。
5. 数据加载:
DATASTORE = "data_store"
if os.path.exists(DATASTORE):
...
else:
st.write(f"Missing files. Upload index.faiss and index.pkl files to {DATA_STORE_DIR} directory first")该应用程序检查数据存储的存在,并加载相关数据,或提示用户上传所需文件。
6. 聊天机器人设置:
system_template="""
As a chatbot, analyse the provided videos on MLOps...
...
prompt = ChatPromptTemplate.from_messages(prompt_messages)
...
chain = RetrievalQAWithSourcesChain.from_chain_type(
...
)聊天机器人结构化了特定指令,并设置了根据用户查询来检索相关视频来源的功能。
7. Streamlit 聊天界面
if "messages" not in st.session_state:
...
for message in st.session_state.messages:
...
if query := st.chat_input("What question do you have for the videos?"):
...聊天界面使用了Streamlit的聊天功能进行开发。当用户输入问题时,助手会提供基于人工智能的见解,并提供特定视频来源的链接。