使用知识图谱来实现DevOps RAG应用程序
利用知识图谱加强LangChain应用程序
RAG应用目前非常流行。每个人都在构建自己的公司文档聊天机器人或类似的应用。通常,它们都有一个共同点,那就是它们的知识来源是非结构化文本,该文本会以某种方式被切块和嵌入。然而,并非所有的信息都以非结构化文本的形式出现。
说,例如,您希望创建一个可以回答有关您的微服务架构、正在进行的任务等问题的聊天机器人。任务主要以非结构化文本形式定义,因此与通常的RAG工作流程没有什么不同。然而,您如何准备关于微服务架构的信息,使得聊天机器人能够检索最新的信息呢?其中一种选择是每天创建架构的快照,并将其转换为LLM能够理解的文本。然而,如果有更好的方法呢?现在,让我们认识一下知识图谱,它可以在单个数据库中存储结构化和非结构化信息。
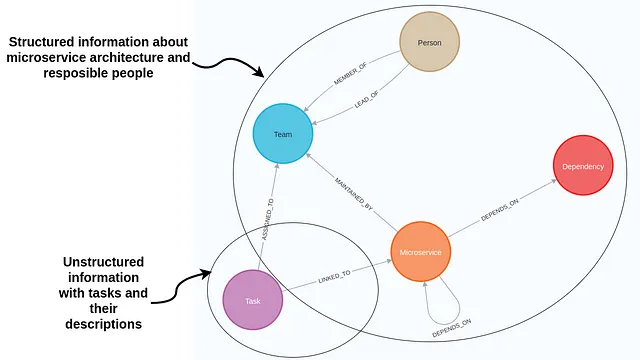
节点和关系被用来描述知识图中的数据。通常,节点用于表示实体或概念,如人员、组织和位置。在微服务图示例中,节点描述了人员、团队、微服务和任务。另一方面,关系用于定义这些实体之间的连接,如微服务之间的依赖关系或任务所有者。
无论是节点还是关系都可以将属性值存储为键值对。
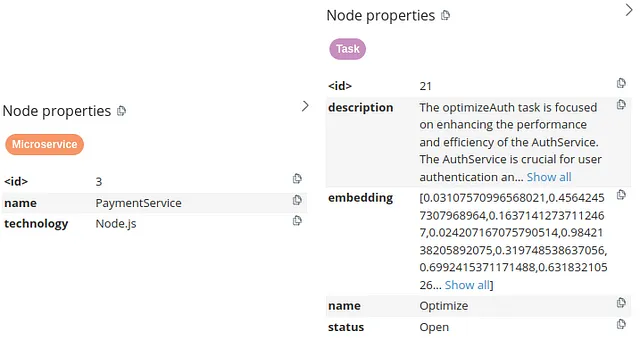
微服务节点具有两个节点属性,描述它们的名称和技术。另一方面,任务节点更加复杂。它们具有名称、状态、描述以及嵌入属性。通过将文本嵌入值存储为节点属性,您可以对任务描述执行向量相似性搜索,就像将任务存储在向量数据库中一样。因此,知识图谱允许您存储和检索结构化和非结构化信息,以提供能力支撑您的 RAG 应用程序。
在这篇博文中,我将为您介绍一种使用LangChain实现基于知识图谱的RAG应用程序的场景,以支持您的DevOps团队。代码可在GitHub上获得。
Neo4j环境设置
您需要设置一个Neo4j 5.11或更高版本,以便跟随本博客文章中的示例。最简单的方法是在Neo4j Aura上启动一个免费实例,该实例提供了Neo4j数据库的云实例。或者,您还可以通过下载Neo4j Desktop应用程序并创建一个本地数据库实例来设置Neo4j数据库的本地实例。
from langchain.graphs import Neo4jGraph
url = "neo4j+s://databases.neo4j.io"
username ="neo4j"
password = ""
graph = Neo4jGraph(
url=url,
username=username,
password=password
)数据集
知识图谱在连接多个数据源的信息方面表现出色。在开发DevOps RAG应用程序时,您可以从云服务、任务管理工具等地方获取信息。
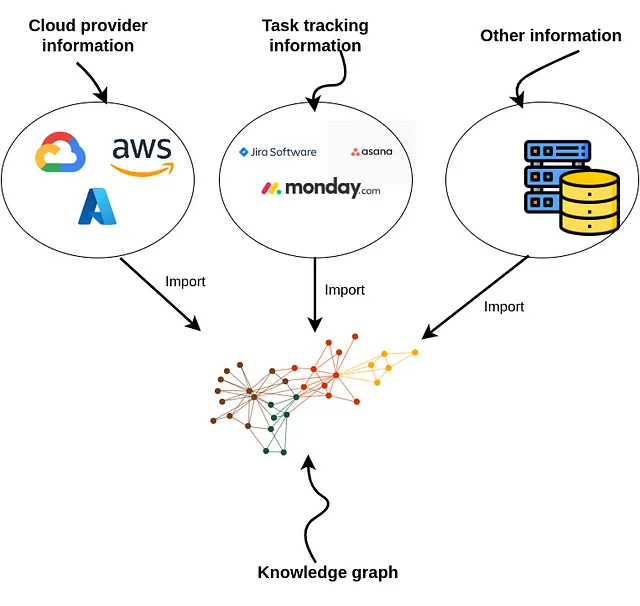
由于这种微服务和任务信息是不公开的,所以我不得不创建一个合成数据集。我使用ChatGPT来帮助我。这是一个只有100个节点的小数据集,但对于本教程来说足够了。以下代码将把示例图导入Neo4j。
import requests
url = "https://gist.githubusercontent.com/tomasonjo/08dc8ba0e19d592c4c3cde40dd6abcc3/raw/da8882249af3e819a80debf3160ebbb3513ee962/microservices.json"
import_query = requests.get(url).json()['query']
graph.query(
import_query
)如果您在Neo4j浏览器中检查此图表,应该会得到类似的可视化效果。
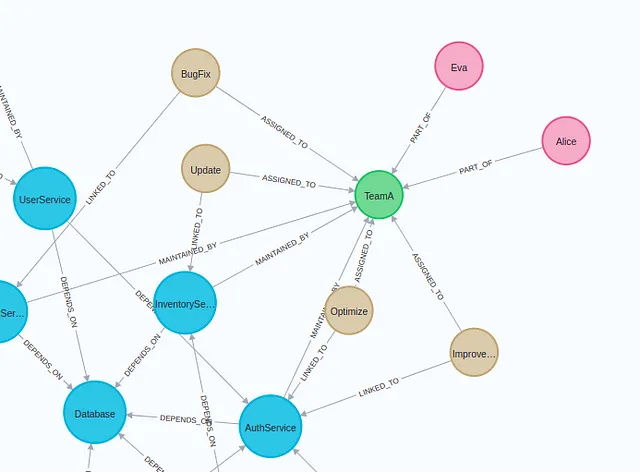
蓝色节点描述了微服务。这些微服务可能彼此依赖,这意味着其中一个的功能或结果可能依赖于另一个的操作。另一方面,棕色节点代表直接与这些微服务相关联的任务。除了显示设置和相关任务的方式之外,我们的图还显示了负责哪些团队的信息。
Neo4j矢量索引
我们将首先实现一个向量索引搜索,通过任务的名称和描述来查找相关任务。如果你对向量相似性搜索不熟悉,让我给你一个简单的复习。关键思想是根据任务的描述和名称计算文本嵌入值。然后,在查询时,使用类似余弦距离的相似度度量找到与用户输入最相似的任务。
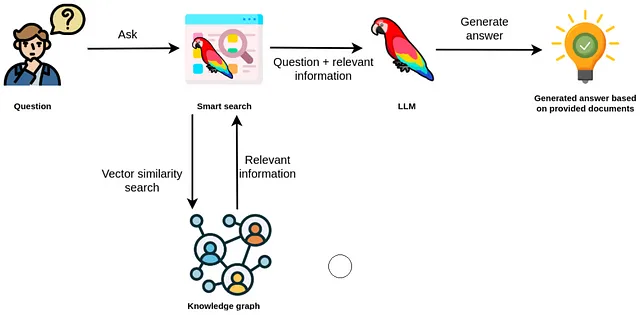
从向量索引中检索到的信息可以作为上下文传递给LLM,从而使其能够生成准确和最新的答案。
任务已经在我们的知识图谱中。然而,我们需要计算嵌入值并创建向量索引。这可以通过使用from_existing_graph方法来实现。
import os
from langchain.vectorstores.neo4j_vector import Neo4jVector
from langchain.embeddings.openai import OpenAIEmbeddings
os.environ['OPENAI_API_KEY'] = "OPENAI_API_KEY"
vector_index = Neo4jVector.from_existing_graph(
OpenAIEmbeddings(),
url=url,
username=username,
password=password,
index_name='tasks',
node_label="Task",
text_node_properties=['name', 'description', 'status'],
embedding_node_property='embedding',
)在这个例子中,我们使用了以下用于from_existing_graph方法的特定于图形的参数。
- index_name:向量索引的名称
- 节点标签: 相关节点的节点标签
- text_node_properties: 用于计算嵌入并从向量索引中检索的属性
- 嵌入节点属性:用于存储嵌入值的属性名
现在向量指数已经初始化,我们可以像在LangChain中使用其他向量指数一样使用它。
response = vector_index.similarity_search(
"How will RecommendationService be updated?"
)
print(response[0].page_content)
# name: BugFix
# description: Add a new feature to RecommendationService to provide ...
# status: In Progress您可以观察到我们使用text_node_properties参数构建了一个类似于地图或者字典的字符串响应,其中包含了已定义的属性。
现在我们可以通过将向量索引包装到一个检索式问答模块中轻松创建一个聊天机器人的回应。
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
vector_qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(),
chain_type="stuff",
retriever=vector_index.as_retriever()
)
vector_qa.run(
"How will recommendation service be updated?"
)
# The RecommendationService is currently being updated to include a new feature
# that will provide more personalized and accurate product recommendations to
# users. This update involves leveraging user behavior and preference data to
# enhance the recommendation algorithm. The status of this update is currently
# in progress.在一般情况下,向量索引的一个限制是它们不提供像Cypher这样的结构化查询语言那样的信息聚合能力。以下面的例子为例:
vector_qa.run(
"How many open tickets there are?"
)
# There are 4 open tickets.响应似乎是有效的,并且LLM使用肯定的语言,使您相信结果是正确的。然而,问题在于响应直接与向量索引中检索到的文档数量相关联,默认情况下为四个。实际上发生的是,向量索引检索到了四个未结票,而LLM毫不怀疑地认为这些就是所有的未结票。然而,事实是不同的,我们可以使用Cypher语句对其进行验证。
graph.query(
"MATCH (t:Task {status:'Open'}) RETURN count(*)"
)
# [{'count(*)': 5}]我们的玩具图中有五个未完成的任务。虽然向量相似性搜索在筛选相关非结构化文本中非常出色,但它缺乏分析和聚合结构化信息的能力。使用Neo4j,可以通过使用Cypher来轻松解决这个问题,Cypher是一种用于图数据库的结构化查询语言。
图寻源
Cypher是一种专门用于与图数据库进行交互的结构化查询语言,并提供一种可视化的方式来匹配模式和关系。它依赖于以下ASCII艺术类型的语法:
(:Person {name:"Tomaz"})-[:LIVES_IN]->(:Country {name:"Slovenia"})此模式描述了一个带有标签“人”的节点,名为Tomaz,其具有与斯洛文尼亚国家节点之间的“居住于”关系的名为LIVES_IN的属性。
LangChain的一个很棒的特点是它提供了GraphCypherQAChain,它可以为您生成Cypher查询,这样您就不需要学习Cypher语法来从Neo4j这样的图形数据库中检索信息了。
以下代码将刷新图架构并实例化Cypher链。
from langchain.chains import GraphCypherQAChain
graph.refresh_schema()
cypher_chain = GraphCypherQAChain.from_llm(
cypher_llm = ChatOpenAI(temperature=0, model_name='gpt-4'),
qa_llm = ChatOpenAI(temperature=0), graph=graph, verbose=True,
)生成有效的Cypher语句是一项复杂的任务。因此,建议使用先进的LLMs(如gpt-4)来生成Cypher语句,而在生成答案时可以将数据库上下文交给gpt-3.5-turbo处理。
现在,你可以问同样的问题,即有多少张门票是未关闭的。
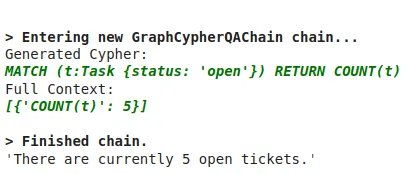
cypher_chain.run(
"How many open tickets there are?"
)结果是以下内容
您还可以要求链使用各种分组键来汇总数据,就像以下示例一样。
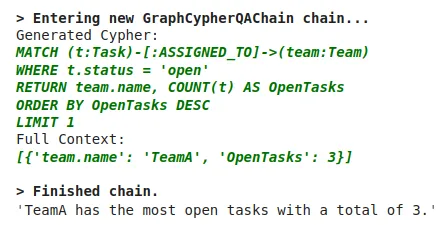
cypher_chain.run(
"Which team has the most open tasks?"
)结果如下
您可能会说这些聚合不是基于图形的操作,您说得对。当然,我们可以执行更多基于图形的操作,比如遍历微服务的依赖图。
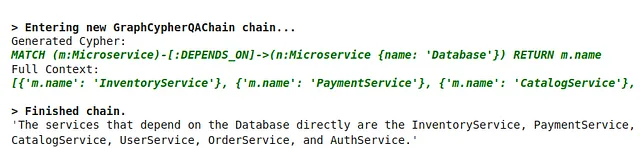
cypher_chain.run(
"Which services depend on Database directly?"
)结果如下
当然,您也可以通过提出问题来要求链条生成可变长度的路径遍历。
cypher_chain.run(
"Which services depend on Database indirectly?"
)结果是以下

一些提到的服务与直接依赖问题中的一样。原因是依赖图的结构,而不是无效的Cypher语句。
知识图谱代理
由于我们已经为知识图谱的结构化和非结构化部分实施了不同的工具,我们可以添加一个代理,利用这两个工具来探索知识图谱。
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
tools = [
Tool(
name="Tasks",
func=vector_qa.run,
description="""Useful when you need to answer questions about descriptions of tasks.
Not useful for counting the number of tasks.
Use full question as input.
""",
),
Tool(
name="Graph",
func=cypher_chain.run,
description="""Useful when you need to answer questions about microservices,
their dependencies or assigned people. Also useful for any sort of
aggregation like counting the number of tasks, etc.
Use full question as input.
""",
),
]
mrkl = initialize_agent(
tools,
ChatOpenAI(temperature=0, model_name='gpt-4'),
agent=AgentType.OPENAI_FUNCTIONS, verbose=True
)让我们来测试一下代理程序的工作情况如何。
response = mrkl.run("Which team is assigned to maintain PaymentService?")
print(response)结果如下

让我们现在尝试调用Tasks工具。
response = mrkl.run("Which tasks have optimization in their description?")
print(response)结果如下

有一件事是确定的。我必须改善我的代理提示工程技能。工具描述方面肯定有改进的空间。此外,你还可以自定义代理提示。
结论
知识图谱非常适合在您需要使用结构化和非结构化数据来支持您的RAG应用程序时使用。通过本博客文章中所展示的方法,您可以避免多语言体系结构,其中您必须维护和同步多种类型的数据库。在LangChain中了解更多关于基于图形的搜索。
代码可在 GitHub 上获得。