
为每个人解密大型语言模型:调整自己的LLM(大型语言模型)的方法。第一部分/共3部分。
你首先要记住的是,LLM代表的是大型语言模型,它们包含数十亿个参数,并且其巨大的大小,加上用于训练的大量数据,赋予它们几乎魔法般的能力。
然而,对于我们中的许多人来说,这是一个挑战,因为这些模型需要大量的计算资源。Sam Altman曾经提到,训练GPT-4的成本高达1亿美元。
在这个系列中,我们将深入研究第一个解决方案,它使我们能够使用标准的16GB T4 GPU对LLM进行微调,从而使这种强大的技术更易于被更广泛的用户所使用。
您将学到什么
- 渐变
- 优化器状态
- 减少LLMs的内存使用的技巧
- 量化
- 完成
介绍
在这个例子中,我们将使用Meta Llama 7B型号,这是一个具有70亿个参数的模型。每个参数都被表示为一个32位浮点数,占用4字节的内存空间。为了将这个模型加载到内存中,我们需要惊人的28GB的内存空间。70亿(模型参数)* 4字节(32位浮点数大小)= 28 GB。使用T4 GPU时,我们将遇到“内存不足” (OOM) 错误。
然而,加载模型只是开始。调优过程还涉及两个额外的内存密集型步骤:管理梯度和优化器状态。这些步骤进一步增加了内存要求,使得高效的内存管理成为处理如此大规模模型的一个重要方面。
让我们从渐变开始
渐变在训练机器学习模型中发挥关键作用。
它们是使模型真正了解数据并在训练过程中提高性能的核心。在训练过程中,模型使用一种叫做梯度下降的技术进行学习。
梯度下降
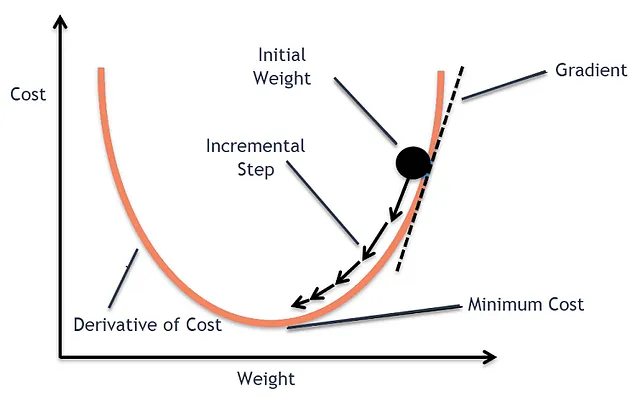
要了解更多关于梯度下降的内容,您可以阅读我关于线性回归模型中梯度下降的文章。
但是用梯度下降总结来说,我们通过逐步调整模型参数的计算梯度和学习率,以最小化损失函数。因此,梯度实质上是指示参数变化的方向和大小的偏导数,以最小化模型损失。
通常,每个模型参数都有一个渐变。因此,在一个70亿参数模型的情况下,我们将处理70亿个渐变,每个渐变占用4字节的内存。这总共需要28GB的内存,仅用于存储渐变。
优化器状态
现在您已经了解了渐变和梯度下降,为了对大型语言模型进行微调,我们可以使用随机梯度下降(SGD),但我们通常使用一种称为Adam的优化器,通常我们使用一种被称为AdamW的变体。(https://towardsdatascience.com/why-adamw-matters-736223f31b5d)
在这个过程中,我们更新LLM参数权重,为此我们需要存储Vt和St,如下图所示。因此,7B * 4(字节)* 2(Vt和St)= 56GB。
总计需要112GB来训练模型,使用32个浮点变量。
技巧
在应对内存挑战的各种技术中,一种直接的方法是从32位浮点精度转换为16位精度。这种调整能够有效地将内存消耗降低一半,将需求从112千兆字节减少到56千兆字节。然而,这种方法存在一个平衡点:仅仅选择16位浮点表示会减少内存使用,但也会限制模型表示大约±65k个不同值的能力。当使用32位浮点数时,我们可以表示±20亿个不同值。
量化
量化实质上是将连续值映射为离散值的过程。在我们的情况下,是将32位浮点数转换为8位整数。
但这是一个挑战,因为现在我们需要将数十亿的数字转换为仅有255个int8的值,而又不能损失太多的模型准确性。
量化过程通常包括两个关键步骤:校准和量化本身。
校准的目标是找到最佳的α因子来最大化精度,在α经过校准后,我们使用以下公式来实现量化。
我们正在观察一系列数字,超出某个范围(我们称之为“α间隔”)的任何内容将被截断或裁剪。在这个范围内的任何内容将四舍五入为最接近的int8数字。选择这个范围非常重要。如果范围太大,可能会包含很多数字,但这可能会导致粗略近似和高误差,无论是由于截断还是四舍五入。因此,选择适当的范围通常是在截断数字和四舍五入数字之间找到平衡的关键。
所以现在我们将有7 * 1 + 7 * 1 + 7 * 2 * 1 = 28GB(其中7代表模型参数的数量,1代表int8的一个字节,2代表我们需要保留的优化器状态的2个值)。现在我们接近将模型适配到16GB的T4 GPU内存中。
结束
在本文中,您学习了:
- 模型规模:大型语言模型(LLMs)庞大而庞大,拥有数十亿个参数,使得它们在使用过程中需要大量的资源。
- 渐变:仅存储一个具有70亿个参数的LLM的渐变就需要占用28GB的内存。
- 优化器:在LLM微调中常常使用高级优化器例如AdamW,这些优化器对内存需求有很大贡献。
- 精度变换:从32位浮点精度过渡到16位可以减少一半的内存使用量,但同时也会降低表示能力。
- 量化:量化是将连续值映射为离散值的一种技术,用于减少内存使用。然而,这需要在内存效率和模型准确性之间进行谨慎权衡。
如有任何意见,请随时在我的Linkedin账号上联系我。谢谢阅读本帖。
如果你喜欢所阅读的内容,请在下方👏,与朋友分享,并关注我,以不错过这系列的文章。
接下来
在下一篇文章中,我将进一步讨论一种称为低秩调整(LoRA)的技术,该技术将继续帮助我们在优化LLM模型的过程中。
参考文献
https://huggingface.co/docs/optimum/concept_guides/quantization 请访问上述链接,以保持 HTML 结构,将以下英文文本翻译为简体中文:
请访问以下链接查看翻译结果: https://towardsdatascience.com/why-adamw-matters-736223f31b5d
用 Hugging Face Transformers 和 Bitsandbytes 集成进行模型量化
在这篇文章中,我们将介绍如何使用 Hugging Face Transformers 库和 Bitsandbytes 集成来进行模型量化。
模型量化是一种减小模型大小和加快推理速度的技术,通过将浮点参数转换为更低精度的表示来实现。
本文将分为以下几个部分:
- 介绍模型量化的背景和原理
- 讨论 Hugging Face Transformers 库的基本原理和用法
- 介绍 Bitsandbytes 集成库及其在模型量化中的作用
- 演示如何使用 Hugging Face Transformers 和 Bitsandbytes 进行模型量化
通过本文,你将了解如何使用 Hugging Face Transformers 和 Bitsandbytes 进行模型量化,以及其在深度学习应用中的优势。








