如何利用可解释性和LLMs自动化商业智能和优化
可解释性机器学习不仅仅是对模型决策过程的一扇窗口,它也是优化和商业洞见的蓝图。

注意:本篇文章适用于从初学者数据科学家到高级机器学习工程师的任何人,希望利用可解释的机器学习和大型语言模型来生成自动化的商业智能。
在讨论机器学习的可解释性时,我们通常理解为提供对黑盒模型的可见性。为了提供这种可见性,全球数据科学家经常利用替代模型来快照ML算法的决策过程。过去的六年中,SHAP主导了这个领域。在2017年发布后,SHAP因使用博弈论而崭露头角,可以产生可以洞察任何机器学习模型如何进行预测的解释性估计。
在本文中,我将展示一种与SHAP相对的方法。这种方法可以实现实时模型可解释性、业务优化和自动化见解,使用一个单一的包——xplainable。我还将展示xplainable如何与OpenAI的GPT API无缝集成,以提供全面的可解释性和商业智能报告,将数据科学工作流与业务决策者连接起来。
免责声明:我是xplainable的开发人员和联合创始人之一。我会尽力保持客观,但对于我们所建立的项目我感到自豪,并且愿意详细讨论。
洞察第一:改变我们处理表格机器学习问题的方式
尽管深度学习(DL)和大型语言模型(LLMs)在近年来得到了迅猛发展,但大部分需要机器学习解决的商业问题仍然是以表格形式呈现的,并且在许多情况下,这些模型必须能够解释其结果。
解释性在大多数数据科学项目中是至关重要的,以确保模型具有稳健性、公正性和无偏见。
通常的(简化的)工作流程大致如下:
- 一个组织内的人员发现需要一个预测模型来自动化一个复杂的决策。
- 一个数据科学家开发了一个机器学习模型来预测决策结果。
- 一个优秀的数据科学家会使用解释性技术来解释模型,并与业务领导分享结果。
- 模型已部署,决策已自动化。
- 当需要时,模型会被监控和重新训练,并且项目会进入维护模式。
这样的工作流程在决策自动化方面做得很出色,但却浪费了许多战略和财务潜力。
这些模型充满了未被注意和未被开发的商业智能。
同时,我们有数据分析师非常努力地手动发现这些模型中包含的内容:统计模式和见解。
考虑到这一点,我认为这个过程应该更像这样:
- 组织内部的一个人确定了需要一个预测模型来自动化、优化和理解一个复杂决策。
- 一个数据科学家开发了一种可解释的机器学习模型,用于预测决策结果并推荐如何优化结果。
- 数据科学家、分析师和业务利益相关者结合自己的技能和知识,不断合作,利用模型生成的商业智能。
- 商业领导者使用模型解释来推动更具见识的战略。
- 模型已部署,并使用模型元数据对个体决策进行了优化。
- 该模型会在需要时进行主动监控和重新训练,并通过跟踪模型解释的变化来持续优化决策制定。
可解释的机器学习不仅仅是窥视模型决策过程的一扇窗户 - 它是自动化问题特定的业务智能和优化复杂决策的一种方式。
我所提出的过程是基于以下哲学原则的。
如果您了解数据如何影响机器学习模型,您可以了解是什么驱动您的目标变量和可以用来改善预测结果的杠杆效应。如果您能够优化预测结果,您可能会增加改善实际结果的概率。
我们可以将我们的特点分为情境特点和杠杆特点来利用这个想法。
上下文特征是无法控制但在预测决策中扮演角色的特征。例如,州/省、年龄、任职年限等。
杠杆是可以控制和优化的功能。例如,接触时间,接触方式,支持类型等都是其例子。
当您构建一个以优化为目标的训练数据集时,理解并应用这个差异非常关键。这个思路是先进行预测,然后识别机会来调整杠杆使预测结果更有利。我们的目的不仅是尽可能准确地预测目标变量,还要理解可以在个别观察上拉动哪些杠杆来最大化或最小化事件发生的可能性。
一旦我们对特征进行分类,我们就可以训练一个模型来理解特征与目标变量之间的关系。然后,我们可以使用全局解释器来学习模型在宏观层面上的工作方式,并使用局部解释器来了解单个观察值的预测是如何进行的。
这是自动化见解的关键,而Xplainable在这方面表现出色。Xplainable不像SHAP或LIME一样是一个代理模型 - 它是一个独立的机器学习模型,旨在完全透明和高度可移植。一个已适应的Xplainable模型内建了全局解释,并且可以在预测准确率与XGBoost和LightGBM相匹配的同时提供实时的局部解释。在这种情况下,代理模型的概念是多余的。
为什么不直接使用SHAP呢?
首先,SHAP之所以如此受欢迎,是因为它是一个出色的通用工具,能够很好地解释复杂模型。然而,在扩展项目超出快照解释时,它的局限性可能会限制其在生产系统中的实用性。
由于计算 Shapely 值需要非常大的计算功耗,在需要快速获取结果时,时间复杂度可能会变得不合理地高 — 尤其是当我们深入探索实时可解释性领域时,我们希望能够实时理解预测的主要驱动因素。SHAP 并非为此而设计。
当然,SHAP可以通过子采样其训练数据来提高速度,但这会以准确性为代价 - 正如您将在本文的剩余部分中了解到的,当我们寻求利用可解释性进行优化时,准确性非常重要。
解锁可解释性——完整指南
探索定期存款预测
为了展示可解释性,我们将通过使用葡萄牙银行机构的开源银行营销数据集来进行示例。该数据集可以在UCI机器学习库中找到。
您可以通过以下链接了解更多关于数据集的信息,但从高层次来看,数据集包含用于预测在市场营销活动后一个人是否会购买定期存款的电话市场营销活动信息。
通常,目的是开发一个模型来预测哪些客户会购买定期存款。然而,通过采取我之前概述的方法,我们可以将目标定为以下:
识别更有可能购买定期存款的客户,并了解驱动购买决策的潜在因素,以改善活动设计。
注意:本帖的主题是模型可解释性和优化。因此,在模型之前采取的一些重要步骤我将略过。如有任何关于这些步骤的问题,请在评论区提问。
开始使用
对于在Python中熟悉机器学习的人来说,您可以通过典型的Pythonic API来利用Xplainable,并且您可以使用pip install xplainable从PyPI安装它,或者如果您更喜欢无代码选项,则可以使用pip install xplainable[gui]进行安装。这篇文章不会涵盖无代码过程,但您可以在xplainable文档中了解更多信息。
数据
让我们加载数据,保留一部分作为测试集,并查看前几行。
注意:您可以运行pip install ucimlrepo直接加载数据集
from ucimlrepo import fetch_ucirepo
from sklearn.model_selection import train_test_split
# fetch dataset
bank_marketing = fetch_ucirepo(id=222)
# data (as pandas dataframes)
X = bank_marketing.data.features
y = bank_marketing.data.targets['y']
# Create a training and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)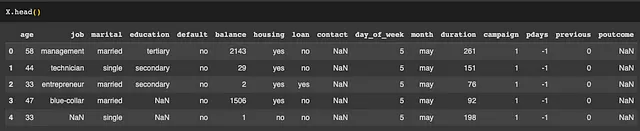
预处理
在建模之前,我们必须对数据进行预处理,以使其达到适当的状态。在使用xplainable进行解释性建模和优化时,有几个关键考虑因素:
1. 保持特性可解释性
避免应用对数据解释能力产生困扰的对数转换和其他预处理技术。我们的目标是开发出高度可解释的模型,以改善决策过程。当我们尝试解释一个经过对数转换的决策过程时,如何理解和决定余额(Balance)等事项呢?
2. 不要平衡类别(不要使用SMOTE!)
这可能与你在不平衡数据集方面学到的知识相抵触,但有一个很好的原因。首先,对于类别不平衡问题,可解释性是具有鲁棒性的,至少在正确的参数设置下是如此。但更重要的是,平衡类别可能会混淆你的解释。这是因为当我们解释结果时,我们是相对于平均定期存款购买率或基准值来进行解释的 - 通过平衡类别,你隐藏了模型中真实的基准值,因此它将无法区分哪些特征在有帮助的意义上更重要,从而使解释变得困难和具有误导性。
3. 尽一切可能避免使用均值替代法
类均衡一样,均值插值使解释性变得模糊不清,特别是在缺失百分比增加时。对于分类特征,使用字符串“missing”或“unknown”进行插值。考虑删除少量的缺失行,如果是数值特征,或者应用更高级的技术以确保不引入特征的偏差。
4. 简化分类特征
通过压缩,我指的是减少唯一类别的数量。高基数的类别特征可能很难解释,并且常常会减慢训练时间。一种方法是选择占x%观察数的类别,将其余的类别分为“其他”。Xplainable提供了一个预处理阶段来自动完成这个过程。
from xplainable.preprocessing.pipeline import XPipeline
import xplainable.preprocessing.transformers as xtf
X_train['City'].nunique()
# Result: 1127
pipeline = XPipeline()
stages = [
# <-- your other stages here,
{"feature": "City", "transformer": xtf.Condense(pct=0.5)}
]
pipeline.add_stages(stages)
X_train_transformed = pipeline.fit_transform(X_train)
X_train_transformed['City'].nunique()
# Result: 2565. 避免使用独热编码
对于编码分类特征,使用虚拟化编码会使结果的解释变得困难,并且可能对元数据用于优化产生负面影响。举个例子,婚姻状况特征——当你保留其原始格式时,可以使用可解释性来比较每个类别(单身 vs 已婚 vs 离异),优化器可以选择其中一个值。如果对该特征进行一位有效编码(OHE),婚姻状况的重要性将分布在2-3个特征之间,优化器将不知道这些状态是相互排斥的。
特征选择
谈到可解释性和洞察力的建模时,特征选择是其中最关键的步骤之一。我们必须在保持解释的准确性的同时,努力最大化我们的准确性指标。
在可解释建模中,特征选择有两个罪状:
多重共线性
过于密切相关的特征会损害模型解释。你必须处理多重共线性以充分利用你的特征。多重共线性不会直接影响预测性能,但会损害模型的可解释性,尤其是如果你打算将模型解释用于决策。
2. 过多的特性
通过保持HTML结构,将以下英文文本翻译为简体中文: "Xplainable可以处理许多特征。然而,人脑却不能。为了充分利用可解释的建模,您应该只选择最重要的特征 - 这将确保您在保持简单易懂的同时能够保持较高的准确性,从而使决策变得更容易。"
为了应对这两种情况,可解释性功能内置了特征选择类,可为您筛选特征并解释为何舍弃某些特征。尽管这对于我们的银行示例来说不是一个突出的问题,但以下是示例:
图形选择器
此功能选择器通过迭代地识别最高相关特征并丢弃最弱的特征来处理多重共线性。GraphSelector创建了一个相关矩阵,并使用NetworkX将所有特征进行交叉映射,以确定哪些特征存在问题。所有这些都可以通过几行代码来实现。
from xplainable.feature_selection.graph import GraphSelector
# Fit the network
graph_selector = GraphSelector(min_feature_corr=0.5, min_target_corr=0.01)
graph_selector.fit(X_train, y_train, start_threshold=0.75)
# Access the remaining features
graph_selector.selected要可视化GraphSelector选择我们的特征的方式,我们可以运行以下代码行:
graph_selector.plot_graph()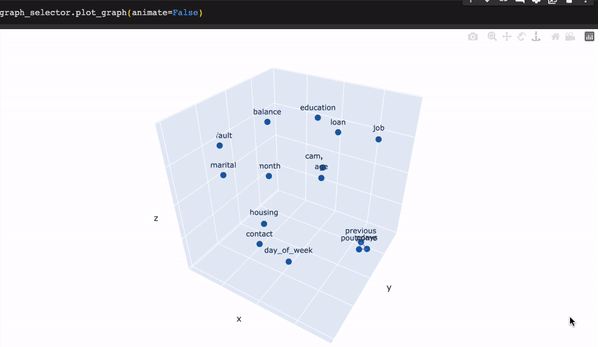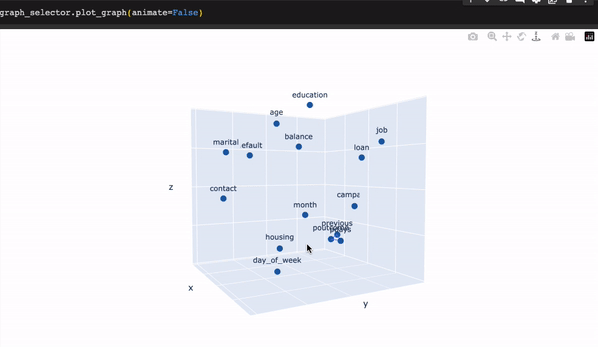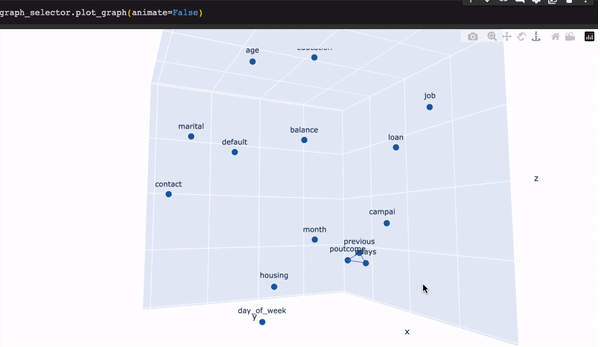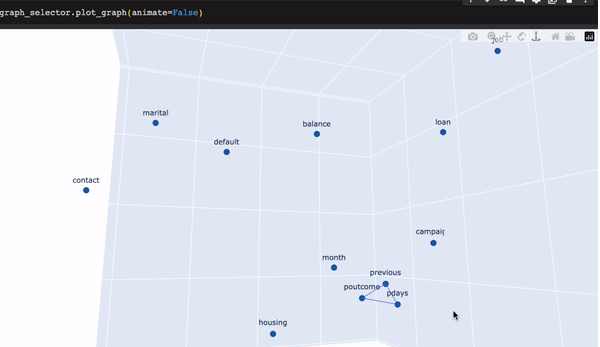
在初始状态下,三个特征呈高度相关。图形选择器通过自动放弃对多重共线性有最大贡献的特征来处理这些情况。
为了解释决策过程,我们可以运行以下操作:
for feature in graph_selector.dropped:
print(f"Dropped {feature['feature']} because of {feature['reason']}")# Output
Dropped pdays because of high chance of multicollinearity with ['previous', 'poutcome']
Dropped previous because of high chance of multicollinearity with ['poutcome']您可以直观地看到特征选择器的决策过程,并通过我们的直觉来确认它正在移除高度可能引起多重共线性的特征。这有助于我们更好地理解数据,并使我们能够为特征选择器设置适当的参数,以确保不会丢失关键特征。尽管有这些发现,但我们将在此示例中保留这些特征在数据集中。
XClf特征选择器
该特征选择器为可解释分类模型(XClassifier)找到最具预测性的特征。它通过迭代选择特征样本并对每个特征集训练模型来实现此目的。训练后,特征重要性分数将乘以指定的准确度指标并存储。该过程重复进行,直到所有迭代都完成。最后,根据总累积分数,对特征进行从最重要到最不重要的排序。这使得识别需要舍弃的特征更加简单。
以下是在定期存款数据集上运行XClfFeatureSelector(在运行GraphSelector之前)的输出结果:
fs = XClfFeatureSelector(n_samples=100)
feature_info = fs.fit(X_train, y_train)
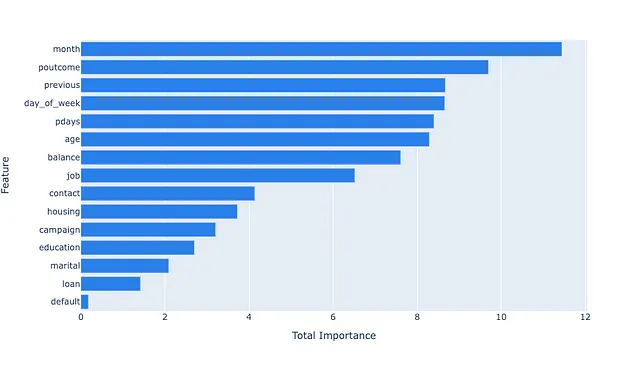
所得图表显示了每个特征的重要性乘以所有迭代中的AUC(默认指标)的总和。您可以看到,默认指标在所有迭代中只起到了微小的作用,因此我们可以考虑将其作为一个特征删除。另一方面,月份和poutcome每次被选择时都非常有影响力,其他特征也以不同程度影响模型的决策。
虽然我们可以更深入地进行特征选择,但是在这个示例中,我们将保留数据集中的所有特征。
特征选择在这些方法结合时最为强大。每个问题都是不同的,因此您可以尝试以不同的顺序运行它们并对每个设置参数,以查看哪种方法会产生最佳结果。我将在后续发布另一篇更详细介绍此主题的文章。
建模
现在,让我们来谈谈真正有趣的东西。使用xplainable进行建模与大多数Python机器学习库并无二致 - 只需使用简单的拟合/转换组合即可应用。然而,xplainable中的参数优化略有不同 - 它非常简单且速度极快(参见快速重拟合)。
from xplainable.core.models import XClassifier
from xplainable.core.optimisation.bayesian import XParamOptimiser
# Optimise hyperparameters
opt = XParamOptimiser(metric='roc-auc')
params = opt.optimise(X_train, y_train)
# Train model
model = XClassifier(**params)
model.fit(X_train, y_train)就是这样。您的模型已经训练完毕,您的洞见可供分析和优化。
微调
如果您想从可解释模型中提取更多的预测能力,可以通过在特征级别而不是数据集级别上设置参数来对其进行微调。这可以通过为一个或多个特征指定一组新的参数并应用以下步骤来完成:
params = {
"max_depth": 7,
"min_info_gain": 0.03,
# ...
}
model.update_feature_params(features=['pdays'], **params)这种参数重新拟合的方法可以比从头开始重新训练模型快上千倍——这正是能够实现快速参数优化和特征选择的原因。
评估
要评估一个模型,您可以运行这一行代码来输出与模型类型相关的大多数关键指标。在这种情况下,是分类模型。
model.evaluate(X_test, y_test)解释模型
为了解释定期存款模型并提取其在全球层面上的见解,您只需要运行以下操作:
model.explain()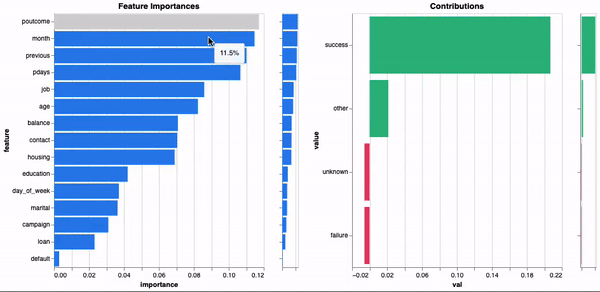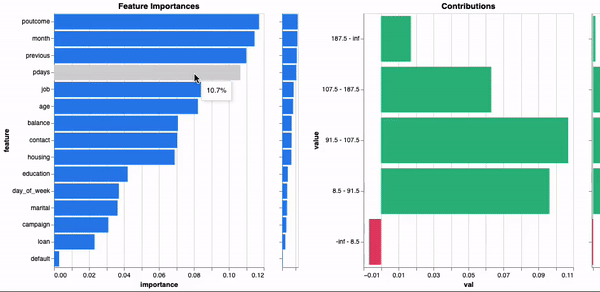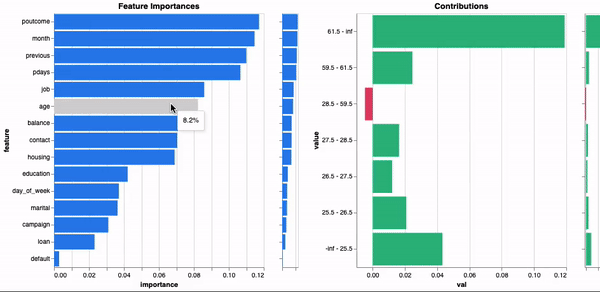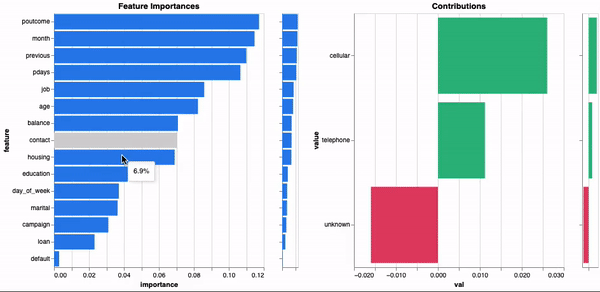
请注意,如果您想要渲染上面的交互图表,您需要使用pip install xplainable[plotting]安装正确的依赖项。
正如您所见,由于元数据在训练期间计算和存储,因此全局解释立即可用。这样一来,我们就可以在不使用替代模型的情况下了解模型决策过程,并且使带有解释的模型更易移植。
实际上,元数据如此轻巧,以至于可解释的模型可以直接部署在微处理器上(使用具有实时可解释性的Tensorflow Lite)。这将在另一篇博文中介绍。
本地解释可以在一个或多个观察点上运行,并且可以在模型训练后立即计算。这可以通过在数据框中的观察点上运行,或者在情景分析工具中完成。
解释观察结果作为数据帧
local_explanations = model.predict_explain(X_test)
local_explanations.sample(5)
返回的数据帧包含每个特征对预测的贡献,以及基准值,分数,概率,乘数和支持。
解释观察结果作为瀑布图
model.local_explainer(X_test, subsample=10)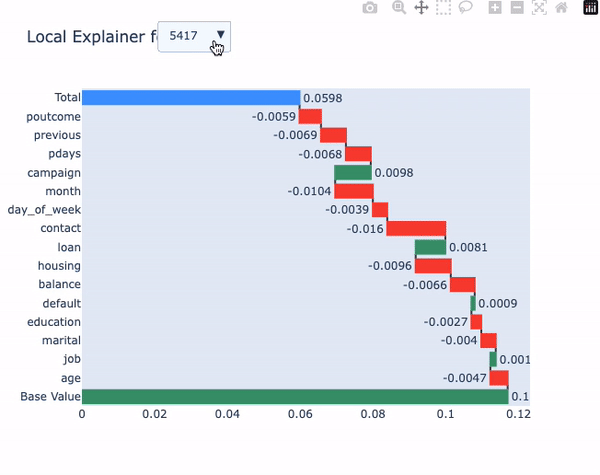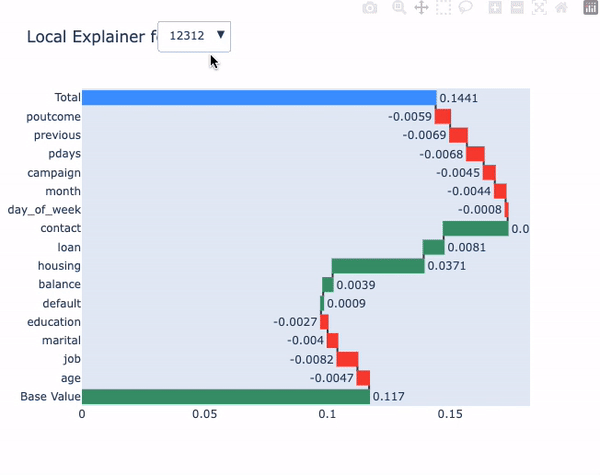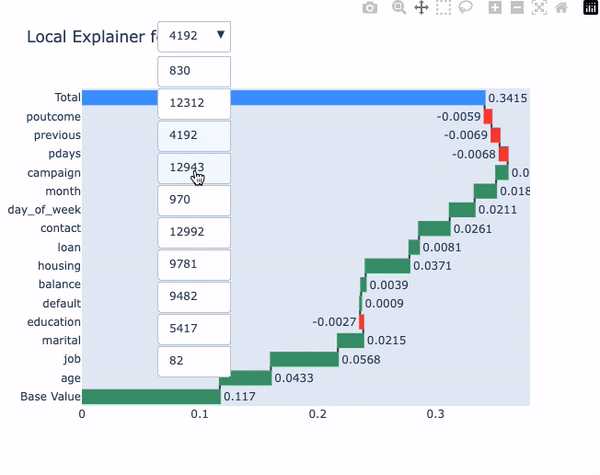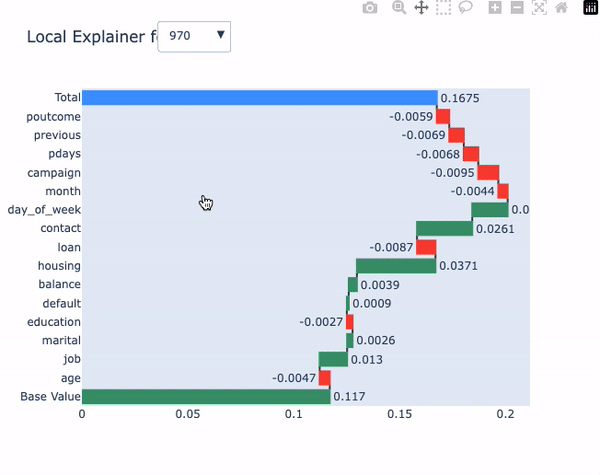
本地解释器与predict_explain()方法提供相同的信息,但允许我们逐个观察地可视化每个观测结果。
GPT解释器
当您拥有有效的xplainable API密钥或访问xplainable网络应用时,您可以使用ChatGPT来生成自动化的、全面的文本洞察和模型解释。
这里是一个在定期存款数据集上生成的报告示例:
import xplainable as xp
from xplainable.gpt import gpt_explainer
import os
# This detects any pre-definined xplainable API keys
xp.initialise(os.environ.get('XP_API_KEY'))
# Generate a report
report = gpt_explainer(
model_id="<model-id-here>",
version_id="<version-id-here>",
target_description="If the customer purchased a term deposit or not",
project_objective="Identify customers who are likely to purchase a term deposit and learn the key drivers to better drive campaign strategy.",
temperature=0.7,
markdown=True
)
report
Xplainable 能够与 ChatGPT 无缝集成,而且说实话,分析结果相当令人印象深刻。以下是我们能够从中提取的内容:
- 问题和数据的摘要
- 每个关键特性和各自的驱动因素的详细分析
- 数据中的关键模式和洞见
- 偏见检测和分析
- 结论和建议
这是一种在自动化洞察和模型可解释性方面改变游戏规则的方式,它依靠可解释模型的轻型架构实现。
API 部署与嵌入式说明
部署可解释模型非常简单。一旦模型被训练好,你可以在不到一秒钟的时间内启动一个端点来处理预测和解释。你所需做的就是拥有一个初始化的API密钥,然后运行以下代码:
xp.client.deploy(
hostname="<your-xplainable-host>",
model_id="<model_id>",
version_id="<version_id>",
location="syd"
)在不到一秒钟的时间内,这个模型将会被部署在一个可解释云服务器上并准备进行推理——你可以通过可解释的网络应用来管理部署的安全性和访问密钥。
以下是使用Postman对部署模型进行的真实测试
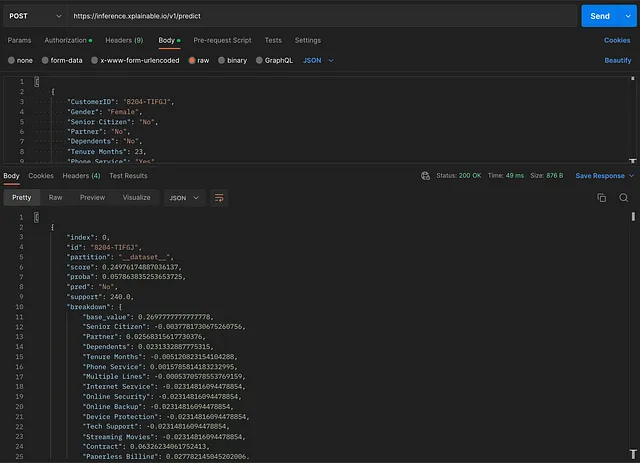
请注意,即使包含了预测细分,响应时间仍然小于50毫秒。这就是实时优化的机会所在——而这是使用代理模型无法实现的。
使用可解释性进行优化是一个庞大的主题,值得拥有自己的博客文章。它在列表中,敬请关注实时优化方面的更多内容。
主要要点
可解释的机器学习不仅仅是关于解释模型 - 它涉及从数据预处理到模型部署的整个数据科学生命周期,以提取有意义的见解并推动更好的决策。
Xplainable 提供了一种同时实现数据科学和商业智能目标的工作流,能够弥合数据专业人员与业务决策者之间的差距。
如果你已经走到这一步了 - 谢谢你。
如何支持可解释性
- 注册演示
- 在GitHub上给我们点亮(Star)
- 关注我们的领英页面
我们对开源项目的承诺 —— 号召贡献者
我们积极鼓励开源社区的合作和贡献。我们相信不同的观点和集体的专业知识会促进高质量的软件开发。通过将Xplainable开源,我们旨在建立一个充满活力的用户、贡献者和热爱者社区,共同塑造可解释机器学习的未来。