GPT-4V(视觉)将如何改变图像注释
我们都听说过在ChatGPT的响应中训练较小的LLM和较小的文本分类器。但现在我们正进入一个新时代,LLM能够准确解读图像。直到现在,ChatGPT的视觉能力只是一个有趣的技巧,但是这个模型的最新改进使其多模型能力能够胜过许多专门构建的视觉模型。尽管这是一个巨大的改进,但视觉问题还没有解决。ChatGPT存在基本的限制,我们使用ChatGPT来克服这些限制。
图片只是以方形排列的一组数字。可以说它是一个矩阵。到目前为止,我们只能训练模型解决一些狭窄的问题,比如分类、定位等等。有些模型能够“描述”一张图片,但是由于准确性和对图片更复杂方面的分辨能力不足,它们很快就崩溃了。这就是ChatGPT的用武之地。由于改进了准确性,我们现在可以要求它按我们的需求“注释”图片。
这如何帮助图片标注?
让我们假设我们需要在没有足够注释的任务上训练一个小模型。我们现在可以使用一个脚本从互联网上收集随机相关的图像,并使用ChatGPT的API对其进行注释。然后我们可以请人类进行审核,这只需要花费实际注释所需时间的一小部分。
为什么要训练新模型,而不是直接使用ChatGPT的API?
在许多情况下,仅使用ChatGPT的API在您的产品中可能是有益的,但有三个重要的原因说明这可能不是一个理想的解决方案。
成本
它大约需要花费0.12美元来获取一个224x224x3的图像的响应。像serna.ai这样的大多数低成本标注服务都会提供更低价格的人工标注。那么为什么要使用这种绕圈子的方法呢?我们可以使用ChatGPT来比人类更快地对图像进行标注。然后我们只需要请一个标注员来审核和完善这些标注。也许在某些情况下,ChatGPT比人类更可靠,例如上面的示例1。
如果光是注释就这么贵,你可以想象为什么实时运行会变得禁止性高。
延迟
GPT-4通过推理API运行,其响应持续时间可能会有所变化,根据输入和输出的长度,可能需要几秒钟的时间。因此,GPT-4可能不适用于需要立即响应、边缘级别的计算机视觉任务,如智能手机上的任务。
托管式GPT-4的限制
将以下英文文本翻译为简体中文,保持HTML结构:
由于GPT-4是通过API提供的,企业必须习惯于访问外部API。GPT-4不适用于需要离线处理的计算机视觉任务。
该模型的理想用例
尽管该模型在通用图像方面表现出色,但我们必须在其聊天界面中进行广泛测试,然后才能在真实世界中实际使用它。在精度至关重要的场景中,最好使用人工标注员进行测试,或者采用混合方法,在使用API进行标注后再由人工审查这些注释。
让我们看一些快速的例子。
例子1: 在这个例子中,我们将展示如何使用HTML和CSS创建一个基本的网页布局。这个布局包括一个标题,一个导航栏,一个侧边栏和一个内容区域。我们将使用一些基本的HTML标签和CSS属性来控制页面的结构和样式。这个例子可以帮助你理解如何使用HTML和CSS创建一个简单的网页布局。
为了进一步分析之前,我们可以根据我们提及的自定义因素,在手机上运行一个筛选模型来检查面部的光照条件是否足够好,然后将其传递给另一个模型或人类进行注释。

例子2:
您正在努力训练一个基于闭路电视的模型,根据地板的脏污程度自动呼叫清洁工或机器人。由于计算成本和响应时间在多个摄像头上24x7运行将成为禁止因素,因此您不能依赖于LLM来完成此任务。
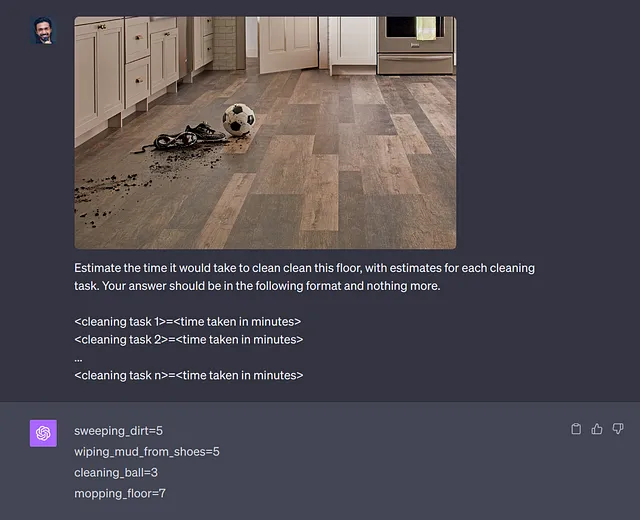
示例3:
您正在尝试训练一个模型,能够快速分析一个人走进建筑物的动作。
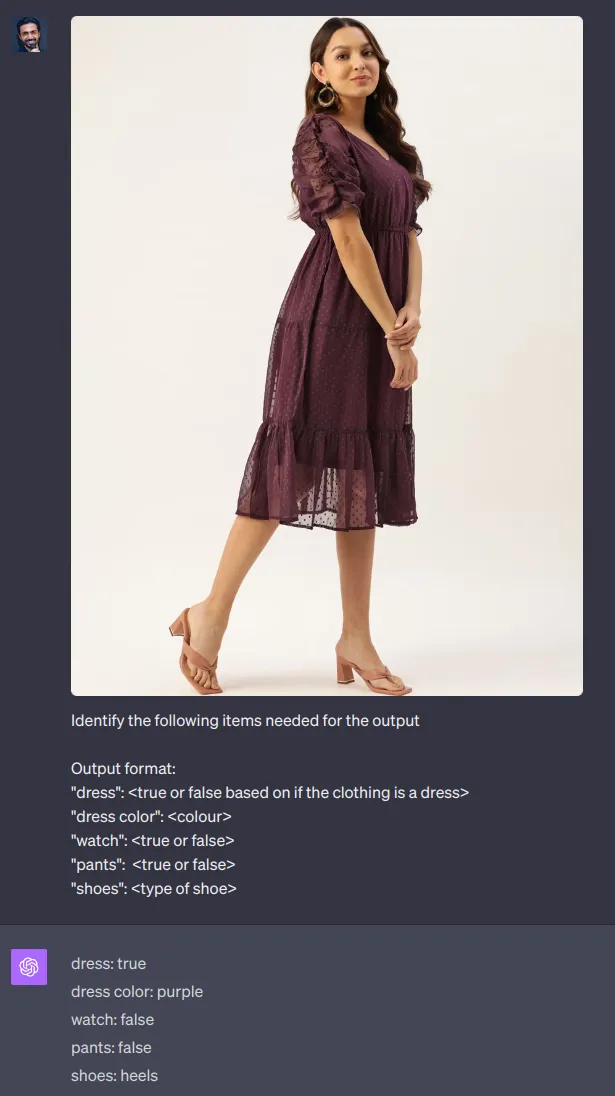
虽然这些是令人印象深刻的,但模型还不完美,如下所示:
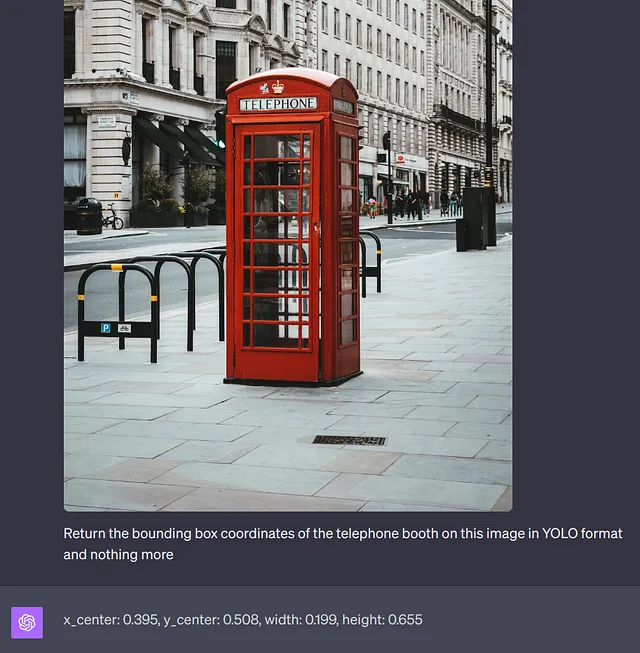

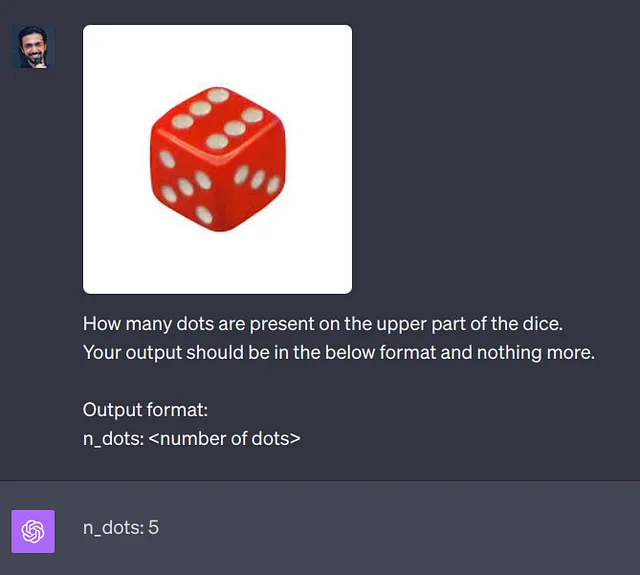
如何在我的应用程序中使用这种方法
- 上传几张图片到ChatGPT,尝试几个不同的提示,看看它是否达到您的期望。
- 如果以至少90-95%的准确率执行,使用ChatGPT API并正确提示它以给出简单的输出,如上面的示例所示。
- 编写一个脚本将这些输出转换成有用的注释格式。
- 将这些注释上传到类似 cvat.ai 的标注平台上,或者付费的标注平台如 roboflow,并请人工标注员纠正任何错误。
结论
虽然这看起来很棒,但它并非万能解决方案。在适当的情况下使用它,并考虑其他可用的自动化方式。
如果您需要在计算机视觉方面的任何问题上获得帮助,包括标注,请发送邮件到rishi@serna.ai。我们为您所有的计算机视觉需求提供端到端解决方案,包括开发、部署和低成本高效的标注服务。




