轻微的提示改变对LLM的影响巨大
大家好
今天我将解释为什么我们应该在我们的提示中详细描述我们想要的输出,这对于使用LLM非常重要。
我们知道,大型语言模型根据我们刚才提问的内容给出一个输出。

如果我们的提示不涵盖标准的范围,我们就无法得到满足我们需求的输出,因为我们没有给予它们遵循的指示。
换句话说,我们的输入越通用,输出越通用,离准确答案越远。
因此,我们的提示必须准确,并为LLM提供一个遵循的框架。
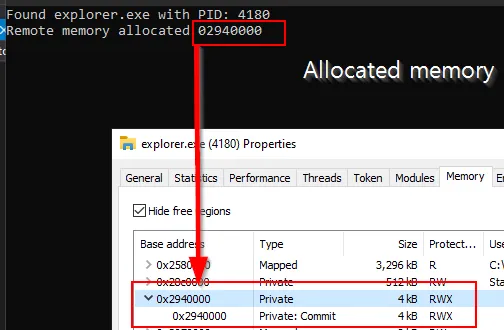
为了更加清楚,让我们来看一下PALM的一个提示示例。


乍一看,似乎有点复杂。但让我解释一下这些行:
在第一行和第二行中,LLM(PaLM)提出了一个前提和假设。
在第三行,它给了我一个任务,要创建一个提示来证明假设是真的。
然后我使用“few-shot example”和“Chain of Thought”模型来证明假设是正确的。
在最后一行中,我从LLM那里得到了反馈,了解了我的提示是否对于达成任务(“证明假设为真”)是有效的。
一切起初似乎都很平常,但问题是:
反馈不准确,也没有给我一个详细的处理方式。
然后我决定去问不同的LLM(chatGPT)给我反馈
这是我从chatGPT得到的。
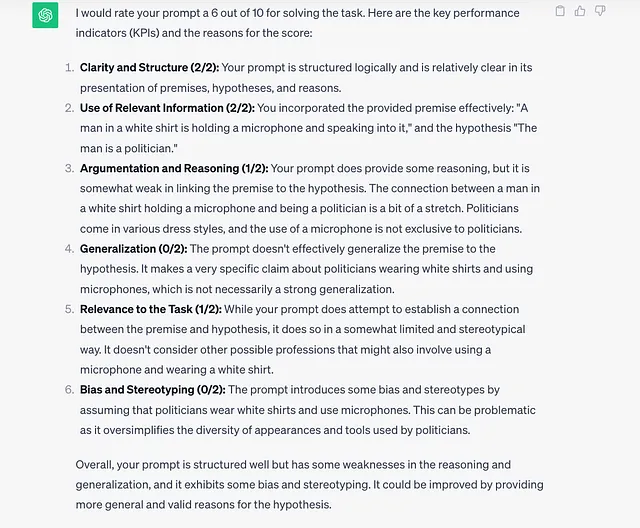
得到更详细和准确的答案的原因与ChatGPT或PaLM的质量无关。
因为我在ChatGPT中的提示有些详细。
这里是我给出的提示:
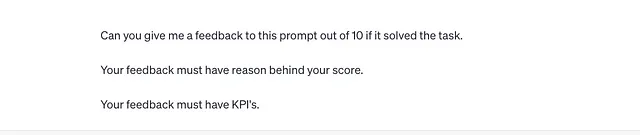
如你所见,我不仅要求它给我反馈,还问了:
— 评分背后的原因
— 评估关键绩效指标(清晰度,与任务的相关性)
由于这样的结果,我从chatGPT得到的输出远比我从PaLm得到的更好。
因为我对我的提示进行了一些小的修改,以便给ChatGPT提供一个框架(原因,关键绩效指标)来跟随。
我希望这篇文章能让您意识到在使用大型语言模型时提供一些详细的提示的重要性。