使用大型语言模型自动化数据分析
从数据探索到文档记录:ChatGPT作为数据分析的端到端解决方案

简介
大型语言模型(LLMs)如chatGPT已经成为强大的工具,能够理解人类语言甚至生成代码。作为一名数据分析师,我每天都与chatGPT互动,以构建思路、编写SQL查询语句并更好地理解现有查询。一个想法浮现出来,即将所有这些功能整合到一个解决方案中,以自动化我工作中的某些方面。我确定了三个实施的关键任务特征:
- 识别:支持分析师找到合适的数据以完成工作
- 实现:将自然语言转化为数据库查询(SQL)
- 文档:记录结果和方法
让我们通过一个实际示例深入探讨这个想法。
如果你想自己尝试这个解决方案,请点击下方链接。
方法
该原型的目标是创建一个端到端解决方案,允许用户提出一个任务或目标,并以数据的形式得到答案。
为了实现这一目标,LLM(在我们的案例中是GPT-4)将被提供一个数据模型。数据模型包括所有表名,以及它们的列、数据类型和与其他表的关系。此外,每个表还将提供三行示例数据,以便让LLM了解其格式。
现在,当用户提供一个提示,例如“2022年销售额是多少”,chatGPT将接收数据模型和问题作为上下文,并收到相应的指令来构建一个SQL查询作为答案。使用Langchain,一个常用的用于高级LLM解决方案架构设计的Python库,很容易做到这一点。
SQL是一种标准数据库语言,可用于合并,过滤和转换表格数据。它是每个数据分析师最基本的工具,可以将代码转换为表格数据。有了这个设置,我们现在可以进一步将问题说明转化为数据。
数据
对于我们的探索,我们将使用Northwind数据库,这是一个可免费使用的资源,旨在展示SQL查询和挑战。该数据库镜像了通用公司的数据情况,包括员工、供应商、客户和订单等要素。
所有的表都通过键相连。例如,每个订单都有一个唯一的订单编号与“订单详细信息”表相匹配,该表本身通过产品编号与“产品”表相连。这显示了关系可以变得非常复杂。例如,要接收特定客户订购的产品,所有这些表(产品,订单详细信息,订单)必须根据各自的编号链接在一起。

基础测试
在任何数据分析师工作中的一个基本步骤是能够将关于数据的问题转化为基本的SQL提示。为了评估chatGPT的能力,使用了一个包含40个问题的存储库,旨在测试Northwind数据集的SQL基础知识。这些问题涵盖了各种标准问题类型,包括表过滤,列合并和表连接,并难度逐渐升级。
问题来源:Northwind数据库GitHub存储库
示例1:
创建一个报告,显示缺货的产品的产品名称、单价和每单位数量。
SELECT ProductName, UnitPrice, QuantityPerUnit FROM northwind.products
WHERE "UnitsInStock" = 0;例子2:
创建一个报告,其中将客户的“总订单数”重命名为“自1994年12月31日以来的订单数”。
SELECT c.CompanyName, count(c.CustomerID) AS NumberofOrders
FROM northwind.customers c
JOIN northwind.orders o ON o.CustomerID = c.CustomerID
WHERE o.OrderDate >= '1994–12–31'
GROUP BY c.CustomerID having count(c.CustomerID) > 10;值得注意的是,chatGPT 在第一次尝试中成功地解答了40个问题中的39个,展示了它在处理基本数据查询任务方面的熟练程度。现在,让我们提升游戏水平,转向一个真实世界的场景。
呈现解决方案
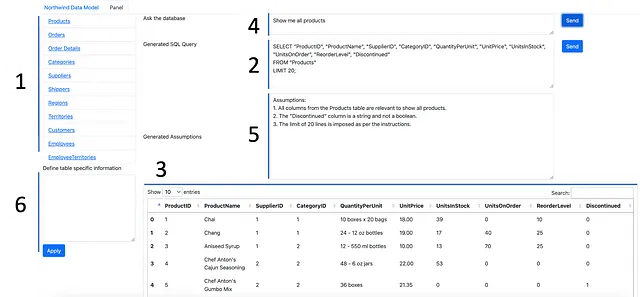
技术的好坏取决于其用户界面。为了方便无缝数据分析和查询生成,下列组件是所有常见数据平台的重要组成部分:
- 一个用于查看单独表格的数据面板。
- 一个用于输入 SQL 查询的文本字段。
- 一个输出部分来查看结果。
为了最大化 LLM 的潜力,引入了三个额外的功能:
- 一个文本字段以自然语言提示数据。
- 一个带有两个功能的展示盒:
- 显示LLM在生成结果时所做的假设(发送按钮在4处)。
- 返回一条SQL查询及其生成的表格的文档(2处为发送按钮)。
3. 输入表格的具体细节的文本框,LLM 在提出解决方案时应该考虑。
为了简单起见,该解决方案不含聊天功能。
一个实际的例子:分析货运公司
让我们深入研究一个实际应用案例。在数据集中,每个订单都由三家运输公司之一进行交付:Speedy Express(快速快递)、United Package(联合包裹)或Federal Shipping(联邦航运)。现在想象一下,你作为一名数据分析师加入北风公司的第一天。你的主管给了你以下任务:
"我想要对我们的物流公司进行对比测试。你能告诉我其中一家公司是否比另一家快递更快?"
探索数据
作为新手,确定相关表格及其相互连接是我们的初始步骤。我们首先在提示框中阐述目标。

通过这个过程,这个模型:
- 认识到订单表在分析交货时间方面的相关性。
- 识别“ShipVia”列和“ShipperID”之间的必要关系,以链接订单表和发货人表。
- 提出一种通过比较“OrderDate”和“ShippedDate”来计算平均交货时间的方法,并记录假设。
在继续之前,让我们查看订单表来验证这种方法。
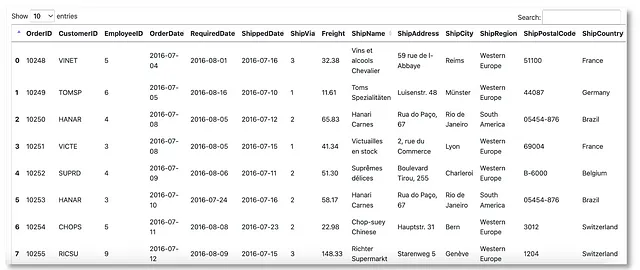
虽然计算交货时间的逻辑似乎是合理的,但我们注意到可能存在偏见。因为不同的运输目的地可能会对平均交货时间产生影响。
优化方法
第一步帮助我们探索了回答问题所需的必要表格和列。现在,为了全面了解运输公司,我们需要分析各地区的平均交货时间。
由于我们现在了解了我们的目标和数据,当我们写我们的提示时,我们可以更加具体,心中有一个清晰的输出图像。

ChatGPT 能够提出正确的方法。这有时需要一些提示工程,但通常要比自己编写正确的 SQL 查询快得多。
分析显示,联邦航运在其竞争对手中表现出色,特别是在西欧和北美等关键市场。然而,在特定地区,其他公司也表现出色。
记录结果
在一个数据驱动的公司里,记录方法通常和得出正确的结果一样重要。我们需要确保,以防这个方法再次被其他人(或数字代理)采用,用户可以快速理解总体目标和列。
在接下来的步骤中,chatGPT将接收到它在上一节生成的查询。此外,将添加表的描述,包括它们的列和一些示例行。在我们的案例中,是订单表。然后,会指示chatGPT定义生成表的目标,并详细说明每个列是如何创建的。

结果不言而喻。ChatGPT能够正确识别分析的目标,并记录每一列及其来源。如果另一个用户再次使用这个表格,范围将很快被理解。
数据分析的未来
优点和缺点
在技术进步的宏伟计划中,像chatGPT这样的LLM在数据分析领域的整合标志着一个重要的里程碑,并将塑造未来的应用景观。正如我们在这次探索中所看到的,这些模型有潜力彻底改变数据分析师处理任务的方式,提供了一种前所未有的与技术交流的新方式。
实际中,数据库可能包含数百个不相关的表。要对整个数据结构有一个概览并确定适合当前任务的最佳表格往往是困难的。这是LLM有很大潜力突出的领域。将表格信息和可用文档输入模型,使用户能够快速获得关于如何解决问题和使用哪些数据的专业意见。此外,拥有一个原生的SQL工具来创建和记录数据库查询可以极大地提高机构内的效率和数据理解能力。
然而,也存在一些挑战,比如受到长度限制的提示难度,限制了详细数据模型的包含。在LLM的背景下,不可能无限制地添加表格。因此,我们在使用这种方法时面临着可扩展性问题。此外,结果的质量可能会有所不同,需要特定且经过深思熟虑的提示来避免懒惰或不准确的回答。我们发现,为了计算平均运送时间,chatGPT采用了一种捷径,没有考虑地区/国家。这显示了理解数据和提示的必要性,以及提供清晰指示的需求。
整合的挑战
克服技术挑战需要进行大量的工程努力。然而,有一些方法可以应对。例如,通过为每个数据集创建单个代理,可以规避最大上下文长度的问题,通过思维引导或与用户进行双向交互,可以避免快捷回答中的偏见和偏差。所有这些都需要在大规模上进行严格的测试和尝试。它要求与数据、界面和文档平台进行全面整合。
这远远超出了大多数公司的核心能力和重点。因此,这些任务由数据分析解决方案提供商,如Google Bigquery或Snowflake,或全新的市场新进者来承担。虽然目前尚无主要解决方案提供商采取行动,但我相信大多数公司目前都在致力于解决方案的研发。然而,责任并不仅仅只落在解决方案提供商的肩上。
采取行动
任何代理的结果只能如公司对数据的理解和记录一样好。只有在数据基础被充分记录且个别表格、数据集收集和领域之间的连接得以建立时,代理才能提出正确答案。实际上,在使用公司内部数据方面,很多最佳实践仍在领域专家或其他数据分析师之间传递。为了使公司能够成功将生成性解决方案整合到其应用程序环境中,公司必须建立流程,从而实现数据集和领域概念的彻底数字化记录。
生成式人工智能在组织中自动化和加速许多繁琐流程方面具有巨大潜力。它可能是完全弥合人类与技术之间鸿沟的缺失环节。然而,要充分发挥其潜力,公司需要采取行动并建立对这项技术的潜力和限制的内部理解。








