解锁 LLM(Language Model) 的力量:HuggingFace 和 LangChain 实践指南
2022年11月30日标志着科技行业的一个开创性工具的发布。OpenAI为广大公众发布了ChatGPT [Chat-Generative Pre-trained Transformer]。这是一个具有里程碑意义的里程碑,可以说只有90年代初互联网的发布才有过类似的情景。
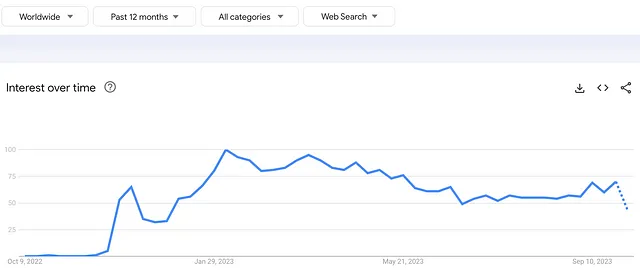
以下图表显示了ChatGPT在过去12个月内在Google趋势上的流行程度。
背后驱动ChatGPT的是一种强大的算法(即GPT 3.5/4.0),基于大型语言模型(LLMs)。
because the primary data have not yet loaded?
这些模型是在大量的文本数据上进行训练的,以学习语言中的模式和实体关系。LLM使用深度学习算法来处理和理解自然语言,执行翻译、情感分析和生成新文本等任务。
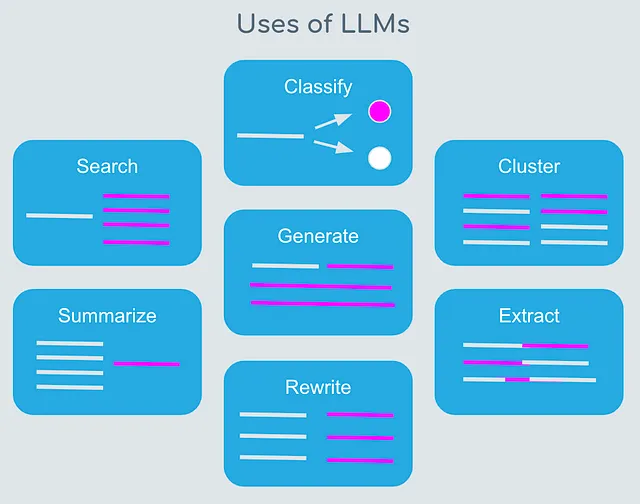
以下图示了LLMs的用途
在本文中,我们将展示一个文本生成LLM的样本用法。
我们需要以下内容来完成实践作业:
- 大蟒蛇(用于在Jupyter笔记本中编写Python代码)
2. Python包 — HuggingFace(开源社区,致力于开发和发布LLM模型),LangChain(开源包装框架,用于编写具有多个提供者(如Meta、OpenAI和HuggingFace)的LLM)。
让我们潜入并开始吧 :-)
步骤
- 根据您的操作系统类型安装Anaconda程序。

2. 点击 Jupyter notebook 下的启动按钮
3. 创建一个HuggingFace账户并生成Access Tokens -
个人资料 > 设置 > 访问令牌
4. 创建一个新的Jupyter笔记本 —— MyFirstLLMApp
以下是MyFirstLLMApp笔记本的源代码
!pip install langchain
!pip install huggingface_hub
import os
os.environ["HUGGINGFACEHUB_API_TOKEN"]="<YOUR ACCESS TOKEN>"
from langchain.llms import HuggingFaceHub
llm=HuggingFaceHub(repo_id="google/flan-t5-xxl")
# The LLM takes a prompt as an input and outputs a completion
query1 = "What is the currency of India?"
completion = llm(query1)
print(completion)
query2 = "when is diwali this year?"
completion = llm(query2)
print(completion)输出是


代码中使用的LLM模型的实际名称是——google/flan-t5-xxl。
您可以在这里阅读更多相关信息。
注:由于某种原因,模型无法正确输出第二个查询的答案。一个可能的原因是t5模型是基于110亿参数训练的。您可以尝试使用其他复杂模型,如Meta的LLaMA 2,该模型基于700亿参数进行训练。另一个好的选择是Falcon模型。
这就是关于实践性法学硕士文章的全部内容。
如果你喜欢我的文章,请考虑为其点赞,并在LinkedIn上关注我。