Langflow微教程 — 链接收集器
欢迎回到我们的Langflow微教程系列!在本文中,我们将继续探索简单的Langflow示例和自定义组件设计。
您可以下载我们将要讨论的流程,以便修改和了解正在使用的组件。
今天,我们将专注于一个基本的网络爬虫流程,用于提取可能包含有价值信息的链接。希望你喜欢!
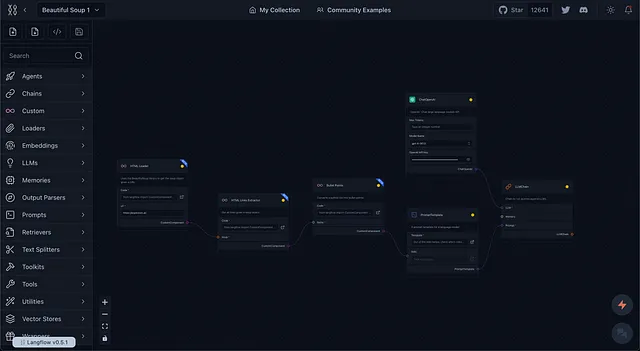
主要特点
HTML加载器:HTML加载器自定义组件使用BeautifulSoup库从给定的URL中检索出soup对象。这样可以轻松从HTML文档中提取相关信息。
HTML链接提取器:HTML链接提取器可以获取HTML内容中的链接。通过利用BeautifulSoup,该组件可以减少在信息被LLM处理之前的文本量,从而节省时间和令牌成本。
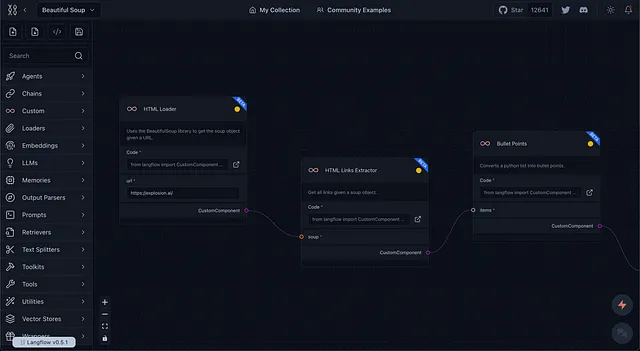
目标
该流程的目标是从HTML文档中提取相关链接,并将它们作为项目符号呈现给语言模型。
该模型旨在识别可能包含公司电子邮件的链接(在此示例中使用了“email”,但您可以想象其他不同查询的类似用例),如“关于我们”和“联系我们”页面。
注意,在将HTML信息传递给提示模板之前,会对其进行一些预处理,这使得自定义组件和LLM管道更具吸引力。