解密LLM驱动的搜索:停止比较嵌入或向量数据库,开始微调
一个对商用语义搜索系统的全面评估揭示了通过行为数据连续优化检索模型的能力远远超过任何基础模型或向量数据库所带来的好处。
保持 HTML 结构,将以下英文文本翻译为简体中文: 持续进行的生成性人工智能(GenAI)和特别是检索增强生成(RAG)的热潮,已经在大多数企业中引发了建立内部语义搜索能力的渴望,以部署用于生产的对话式知识代理。在我们早前的博客中,我们解释了RAG管道内语义搜索的工作原理,包括嵌入、向量数据库、预训练和微调等术语。
目前,互联网上充斥着关于嵌入模型和/或向量数据库正确选择的建议。然而,许多研究缺乏在客户界面生产环境中量化语义搜索的真实影响的具体案例研究。为了填补这一空白,我们提出了这样一个案例研究。
评估目标:理解真正重要的事情!
我们的评估关注以下三个关键问题
1. LLM驱动的搜索真的比基于关键词的弹性搜索更好吗?
2. 在实践中,嵌入模型的选择是否重要?是否值得付出努力?
3. 我们真的需要更多的微调吗?也许基础模型已经足够了?
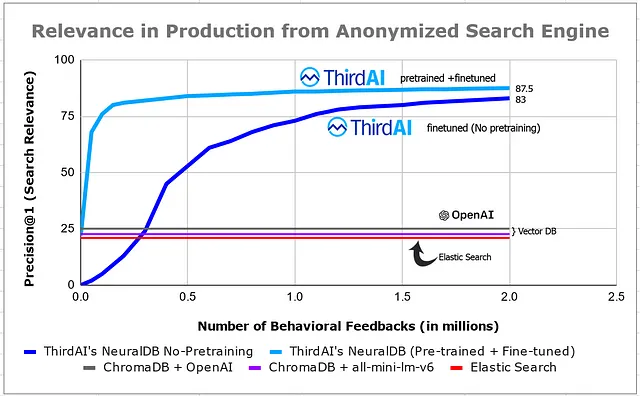
评估设置之要点:来自大规模真实生产工作负载的不断演进的用户数据
一个常被现有基线忽视的关键因素是面向客户的应用程序不断变化的特性。如今存在的大多数评估只关注静态基准,与时刻变化的真实世界生产数据集相距甚远。为了解决这个问题,我们使用一个广受欢迎的商业语义搜索引擎进行了评估(为了保护隐私而匿名化),在一个较长的时间段内运行,处理了数百万条文本用户查询。
在这种情况下,用户提交基于文本的查询,希望获得"相关的"结果,通常涉及具有自己文本描述的产品或物品。评估算法为每个用户查询排名结果。然后,用户进行交互,提供明确或隐含的反馈,用作进一步改进和/或评估的标签。
明确的反馈以喜欢、不喜欢或领域特定的信号形式存在,其中包括产品购买等具体行动。最近时间间隔的标签形成了一个未见过的预留数据集。这个包含数百万个未见标记的数据集用于对竞争算法进行全面的大规模评估。所有基线算法都在这个完全未见的测试集上进行评估,该测试集反映了模型在实际生产中的估计效用,基于真实用户的反馈。
基准线:我们评估了以下四个基准线的类别。
- 弹性搜索(基于关键字的非语义搜索):我们使用了标准实现。
- 基础模型和VectorDB(仅预训练,不进行微调):在这里,我们展示了两个不同的基础模型的结果,分别是a)OpenAI的Ada模型和b)All-mini-LM-v6,一种更便宜且受欢迎的模型。对于这两种嵌入模型,我们使用Chroma VectorDB报告结果。当使用其他任何VectorDB或开源算法时,我们没有看到结果方面的变化。请注意,该生态系统不鼓励进行微调,因为如果嵌入模型以任何方式进行修改,它们需要完全重新构建。
ThirdAI的NeuralDB无需预训练(经过监督调优的语义基线没有任何预训练):NeuralDB是一个高级的学习索引检索系统,消除了管理和存储任何嵌入的需求。我们使用了这个没有预训练步骤(在插入期间将train标志设置为FALSE)的NeuralDB脚本。NeuralDB自动消耗任何反馈数据(使用db.supervised_train函数调用),同时还包括文本查询,并更新用于检索的神经模型。使用NeuralDB不需要任何嵌入模型或向量数据库。
- 第三人工智能的神经数据库(预训练+监督微调语义基线):我们在文本插入(按下按钮进行自我监督预训练)期间,使用了相同的神经数据库脚本,将训练标记设置为TRUE。它使用原始文本对神经数据库内部的神经模型进行纯自我监督的预训练(无需标签)。神经数据库然后自动消耗任何行为数据(使用db.supervised_train函数调用),并更新检索的神经模型,提供一键式微调功能。
结果在上面的图中总结。
结论
AI的真正商业影响几乎完全取决于我们的零样本能力是否从21%的精度(弹性)提高到了24%的精度(OpenAI)。如果没有使用生成的反馈和行为数据进行精细调整,我们的精度将从超过87.5%下降至接近25%。即使只有微小的行为反馈,也可以通过预训练的NeuralDB模型实现前所未有的提升,使我们能够在短时间内从24%提高到80%的精度。根据上图,我们可以得出以下结论。
1. 任何生产中的语义搜索用户界面系统都会产生隐式或明确的反馈形式的行为信号。如果没有计划使用这些数据来不断调整模型,上面的情节清楚地显示我们浪费了大部分人工智能的优势。社区已经开始意识到这一点,例如,可以在这里找到到另一个博客的链接。
2. Foundational LLM驱动的模型和向量数据库的检索质量只比弹性搜索略好。这与许多最近的观察结果相一致。弹性搜索的主要限制是无法进行精细调整,这可能成为其在人工智能主导领域未来的致命因素。
3. 不同的基础嵌入模型选择只会带来微小且可以忽略的差异。
4. 不断进行微调并不复杂,并且可以通过稳定的系统(如ThirdAI NeuralDB)使用简单的API来实现。
AI驱动的语义搜索在生产中的“严酷现实”。
主要的语义搜索引擎,如 Google、Microsoft、Amazon等运用人工智能/机器学习的搜索引擎,都在持续进行再训练和优化。基于人工智能的语义搜索是一个成熟的概念,在几乎所有成功投入实际应用的系统中,不断优化模型是现实的。
如果组织在投资语义搜索基础设施时,不鼓励以监督的精细调整形式进行领域专门定制,那么这样的基础设施很可能会面临生产上的挑战。
NeuralDB:随时进行持续预训练和/或微调。完全不需要嵌入,也无需向量处理。
NeuralDB 是一种先进的学习索引检索系统,它消除了管理和存储任何类型嵌入的需求。ThirdAI 的 NeuralDB 专注于微调的重要性。无论可用数据量如何,NeuralDB 始终鼓励微调。只有 NeuralDB 的 API 提供了一个点击按钮选项,用于在插入时进行自监督预训练(将 train 标志设置为 TRUE/FALSE)。此外,还有两个 API 用于监督微调:db.associate API 和 db.supervised_train API。NeuralDB 的设计旨在通过不断演化的 LLMs 过程,实现最高的相关性,以满足组织的不断变化的需求。