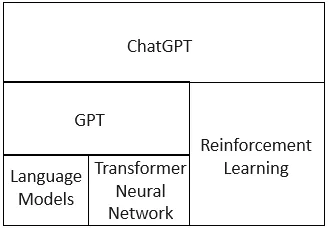
编写完整的工程指南

您可能会好奇为什么在您已经知道ChatGPT的工作方式并能与其进行交流以获取答案时,还需要提示工程。然而,请考虑以下例子:
我请GPT把奇数相加,并告诉我结果是偶数还是奇数。不幸的是,它没有给出正确的答案。失败的原因在于我使用的提示。你可能会认为我可以轻松为这个特定问题提供一个更好的提示,但是想象一下更大或更复杂的情况,许多人都在努力从ChatGPT中找到解决方法。
在这种情况下,您提供的提示确实很重要。正如您从我对提示的简单变化所看到的那样,它未能给出正确的答案。那么,这是否意味着我们不应该使用GPT?不,我们绝对应该使用,但要正确引导。这就是提示工程发挥作用的地方,它允许我们优化输入并引导GPT产生更准确和期望的输出。
本博客提供的示例直接引用自官方文档,文档地址为
官方文档链接 - https://www.promptingguide.ai/.
由— dair-ai 创建
此外,指南中展示的示例是在OpenAI的游乐场平台上使用名为text-davinci-003的特定模型进行测试的。值得注意的是,该指南假设模型的默认设置,即温度值为0.7,top-p值为1。
所以,系好安全带,准备释放你内心深处的提示引擎师。让我们开始吧!
目录—
Prompt Engineering
-- Introduction
-- LLM Settings
Basics of Prompting
-- Prompt Elements
-- General Tips for Designing Prompts
-- Examples of Prompts
Techniques
-- Zero-shot Prompting
-- Few-shot Prompting
Chain-of-Thought Prompting
Self-Consistency
Generate Knowledge Prompting
Additional Readings什么是提示工程?
想象一下,你拥有一个超级智能助手,我们称其为AI助手,它可以回答你提出的任何问题。例如,如果你问它:“法国的首都是什么?”它将给你正确的答案:“巴黎”。
现在,假设你想让AI助手变得更加出色。你希望它不仅告诉你一个国家的首都,还要提供关于它的简要历史。在提示工程中,你会调整你的指令来实现这一点。这意味着你不仅仅问:“法国的首都是什么?”而是重新表达为:“告诉我法国的首都及其历史意义。”通过调整提示,你指导AI助手给你想要的结果。
在现实生活中,及时反馈工程被广泛应用于许多应用程序中。例如,想象一下像Siri或Alexa这样的虚拟助手。当你问他们一个问题时,你提问的方式会影响他们回答的质量。通过理解及时反馈工程,开发人员可以改善这些系统,为我们提供更准确和有帮助的答案。
LLM 参数
在影响大型语言模型(LLM)输出的各种参数中,有两个起着重要作用:温度和 top_p 值。让我们定义每个参数,以了解它们对生成结果的影响。
温度:将温度看作烹饪中的辣度。较低的温度值使语言模型在最可能的预测中保持安全,并且坚持使用最可能的结果。就像添加较少的辣料一样,这会使输出更加一致和可预测。另一方面,较高的温度值会增加更多的随机性和创意,就像给菜肴添加更多的辣料,获得意想不到的风味组合。
Top_p (最高概率值):
假设你有一个包含多个选择题和各种可能答案的问题。最高概率值(Top_p value)就像是设置一个阈值,用于确定要考虑的选项数量。较低的最高概率值意味着只选择最有可能的答案,保持专注和准确。它就像只考虑前几个选择。相反地,较高的最高概率值扩大了选择范围,包括更多的可能性和多样化的回答。
简而言之,温度影响着语言模型输出中的随机性水平,而top_p值则控制了被考虑选择范围的大小。
基本提示
让我们通过一个非常简单的提示:
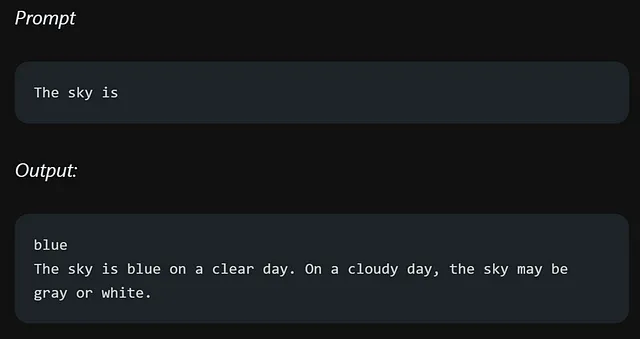
当你用“天空是”开始句子时,它会给你不同的选择而不是一个确定的答案。但是,如果你在句子中加入更重要的细节,你就增加了得到明确和准确回答的机会。让我们看另一个例子,看看在提示中添加关键信息会有什么不同。
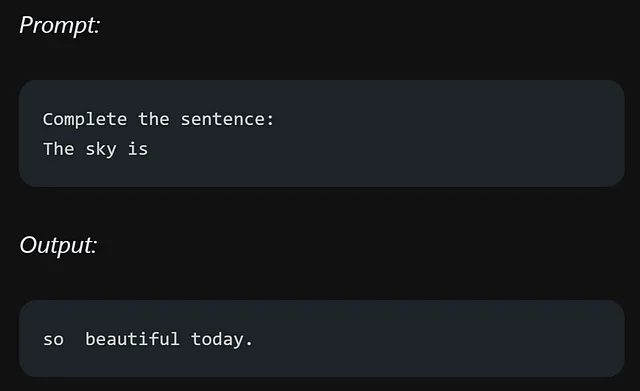
这样清晰了吗?你指示模型完成句子,导致了更准确的回答,与你的提示相一致。构建有效提示以指导模型任务的这种技术被称为提示工程。
提示格式化
简单来说,基本规则是问题应该以以下格式呈现:

当一个指令应该被格式化为:

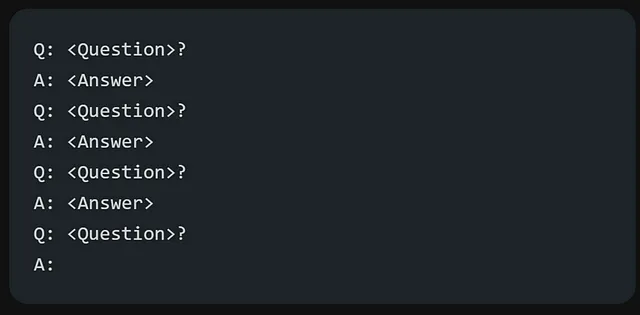
谈到格式化问题回答,通常的做法是使用广泛应用于许多问题回答数据集的问题回答(QA)格式。
上述提及的格式通常被称为零射示提示。之所以被称为零射示提示,是因为它不涉及提供任何关于问题和答案结构的具体示例或演示。
在我之前提到的格式中,还有一种被广泛使用且有效的技术叫做少数示范提示。在少数示范提示中,你可以包含示范来引导模型。以下是如何对少数示范提示进行格式化:

QA格式的版本将如下所示:
为了更清晰地展示少量提示如何工作,这里有一个小示例分类:
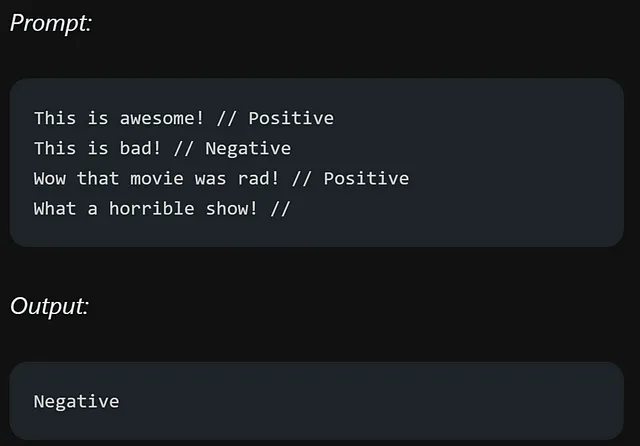
提供的格式非常清晰。每个评论后面跟着两个斜杠(//),然后是情感值,可以是积极的或消极的。
少量样例提示允许语言模型通过提供少量示例来学习任务,这有助于它们理解上下文并表现更好。
提示的要素
一个提示可以包括不同的元素:
- 指示 — 这是给模型遵循的具体任务或方向。
- 上下文——它提供额外的信息或背景,以帮助模型生成更好的回应。
- 输入数据 — 它指的是我们希望模型提供回答的问题或输入。
- 输出指示器——它指示了输出的期望类型或格式。
不是所有的四个要素都是一个提示所必需的,而且格式取决于执行的具体任务。
设计提示的一般建议
开始简单-当设计提示时,重要的是从简单开始,并尝试重新设计或迭代以实现最佳结果。正如官方指南中提到的那样,建议从基本的游乐场(如OpenAI或Cohere)开始。您可以通过添加更多元素和背景逐渐增强您的提示,以改善结果。在整个过程中,迭代您的提示至关重要。
为了设计有效的简单任务提示,使用诸如“写”,“分类”,“总结”,“翻译”,“排序”等具有指导性的命令。实验是找到最佳方法的关键。一些建议包括将说明放在提示的开头,并使用清晰的分隔符如“###”来区分说明和上下文。
例如:
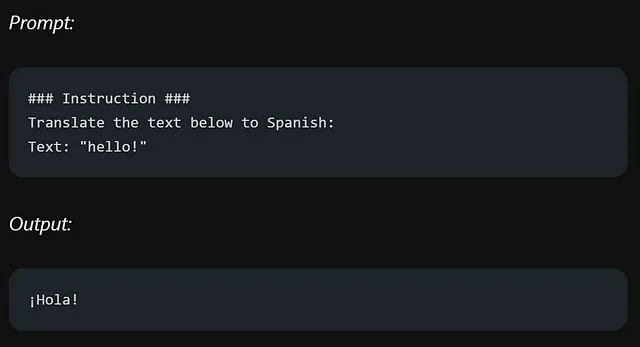
保持HTML结构,将以下英文文本翻译成简体中文: 在您的指令和所需任务的模型中要极其具体和详细。专注于拥有良好结构和描述性的提示。在提示中包含示例可以非常有效。考虑到提示的长度,因为它有一定的限制。力求在具体和避免不必要细节之间取得平衡。
考虑以下例子,我们想从一段文本中提取信息:
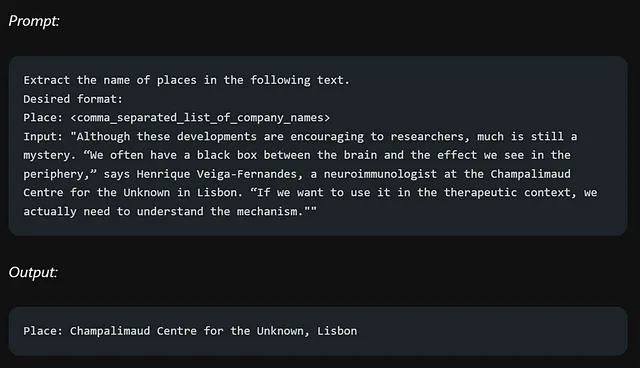
在详细描述和改进提示的格式方面非常重要,但是避免过分复杂和模糊的描述至关重要。明确直接往往更加有效,就像有效的沟通一样。
以下是我试图表达的一个快速示例!假设你想要理解即时工程。起初,你可以向ChatGPT请求一个简要解释,而不需要太多的详细信息。你可以尝试类似这样的内容:

然而,该提示可能没有清晰的指示句子数量或风格。虽然您仍然可能会收到不错的回答,但更好的方法是(非常具体、简明扼要):

在设计提示时,不要指定不要做什么,而是提供清晰的说明,指导模型应该做什么。
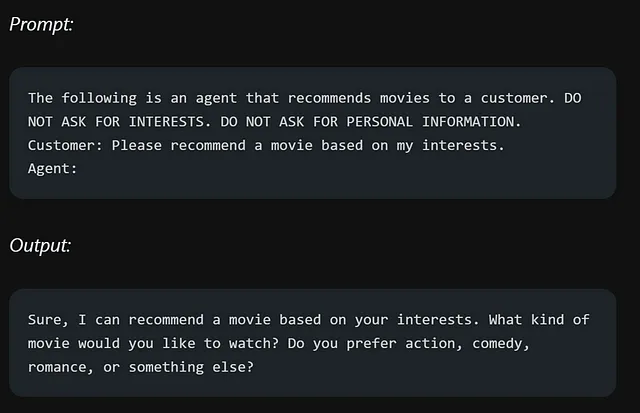
让我们来看一个电影推荐聊天机器人的例子, 由于指示的方式不当而未能满足期望。用户要求它避免做某件特定的事情,这导致聊天机器人将注意力放在了错误的方面,而不是用户真正想要它做的事情。
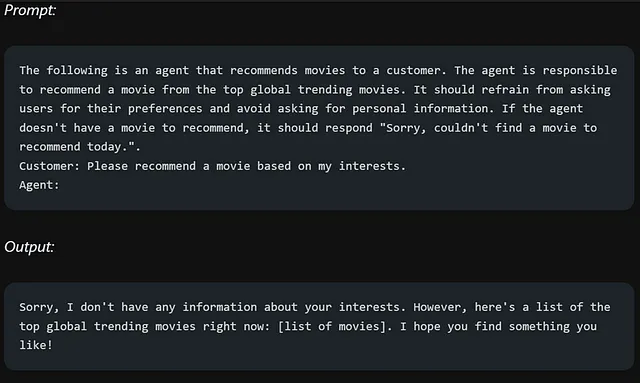
现在,我们不再指示机器人不应该做什么,而是提供明确的指示,告诉它我们希望它做什么。
提示工程使用案例
在本节中,我们将探索不同领域中关于提示工程的各种应用案例,例如文本摘要、问题回答等等。
文本摘要
在自然语言生成中,将英文文本翻译为简体中文并保持HTML结构是一项常见任务。我们可以尝试使用提示进行简单的总结任务。以下示例将抗生素信息概括为一句话。

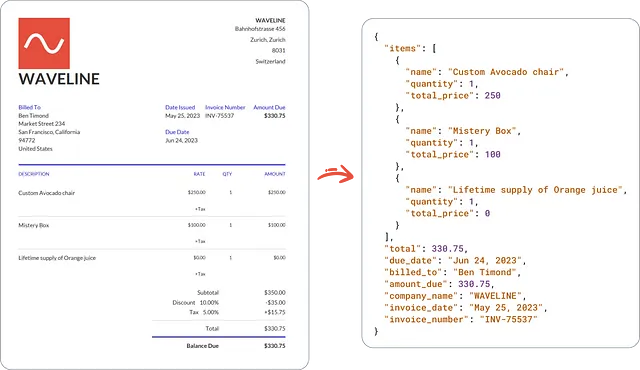
信息抽取
现在我们将利用一种语言模型来进行信息提取。这涉及从给定的段落中提取相关信息。
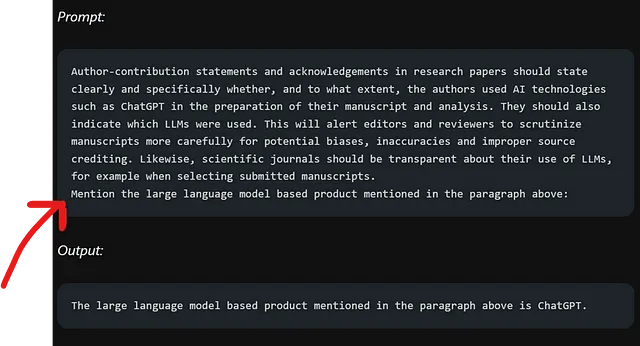
在段落中,红箭头突出显示所询问的信息。
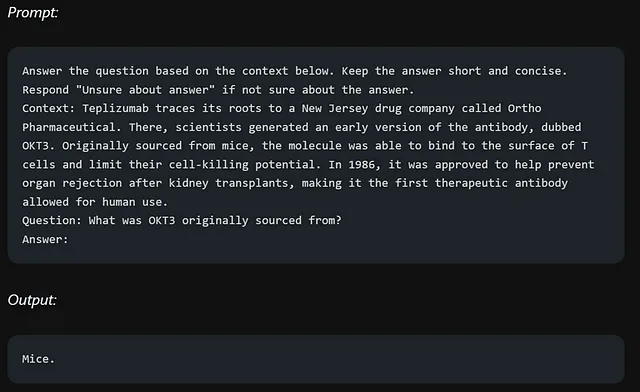
问题回答
这是一个使用语言模型(LLM)进行问答的指南。
文本分类
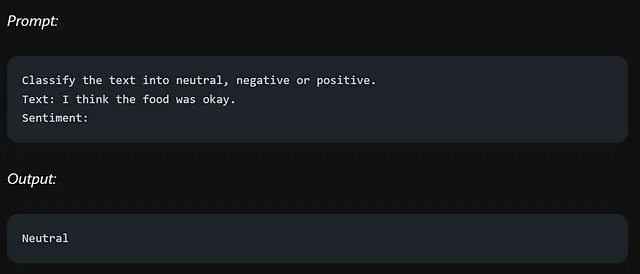
为了获得所需的标签格式(如“neutral”而不是“Neutral”),请在提示中提供具体的指示以获得更好的结果。
例如:
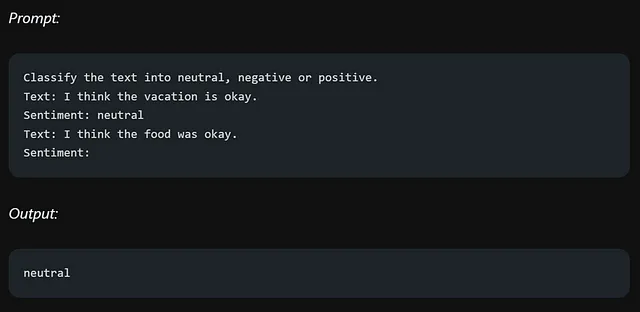
当您提供了模型应该返回情感值的样本时,模型将以与提供的样本相同的格式返回该值。
让我们来尝试以上示例,但稍微有所变动:
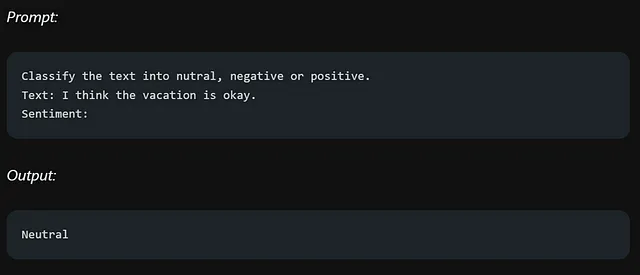
该模型返回“中立”而不是“nutral”,是因为在提示中没有提供特定的示例来指导所需的输出格式。在提示工程中,明确和提供清晰的示例是至关重要的,以确保模型理解期望的内容。
立即改善工程使您可以指示LLM系统作为会话系统(如聊天机器人等)运行。这就是角色提示发挥作用的地方。
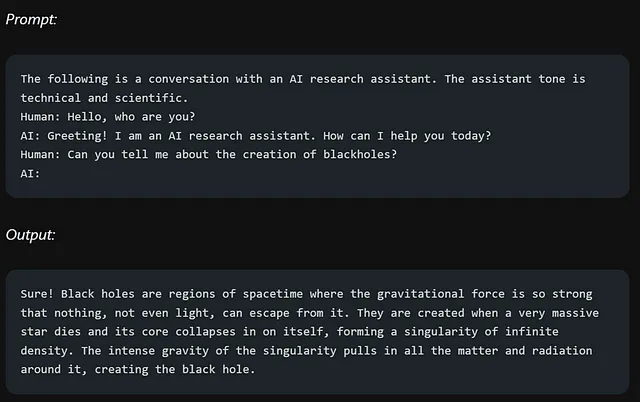
为了使机器人更少技术性、更易理解,请在提示中提供额外的信息,例如指定回复应以一个7年级学生可以理解的语言为准。这将引导机器人使用更简单的语言并避免过多的技术术语。
代码生成
确实是语言模型(LLMs)的一个重要使用案例。GitHub Copilot作为一个示例,展示了如何利用LLMs生成代码。
没有为答案指定编程语言。这凸显了即使问题中缺少一个小细节,也会对回答的理解和准确性产生显著影响。
对于语言模型(LLM)来说,最具挑战性的任务之一是推理,它涉及到进行逻辑思考并根据给定信息得出结论的能力。
这里是一个复杂的提示,挑战我们的法学硕士对其理解的能力:
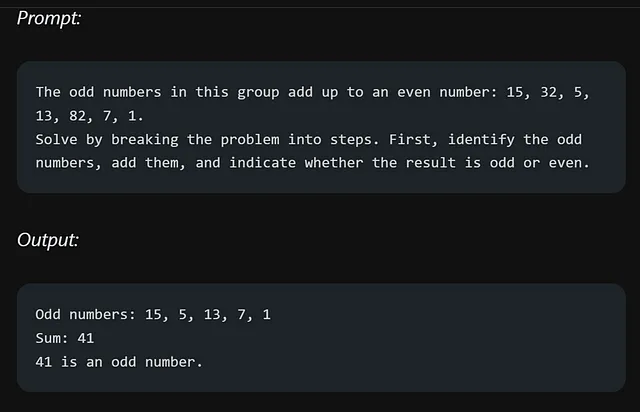
作者明确表示他们进行了多次尝试来实现这一目标。这强调了在使用LLM时,推理确实是最具挑战性的方面之一。
促使技巧
零射击提示
大型的LLM(例如GPT-3)可以在没有明确训练的情况下执行任务,这要归功于它们遵循指令的能力和在大规模数据集上进行的广泛训练。这被称为“零样本”学习。由于它们已经熟悉提示中的单词,所以几乎没有额外的学习需求。
让我们回想一下我们的情绪提示示例:
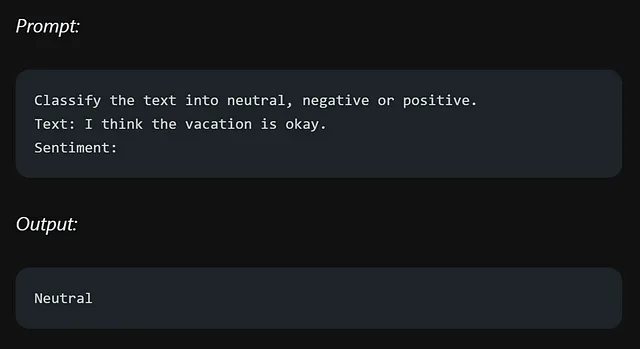
尽管没有明确提到“情感”一词,但该模型的零样本能力使其能够理解并生成与情感相关的回复,这要归功于它在一个大型数据集上的训练。它可以根据其预先存在的知识和上下文推断出这一概念。
少量提示
当零样本测试不起作用时,我们使用少样本提示,即给我们的模型提供示例。一个示例表示一次尝试,给予两个示例表示两次尝试,依此类推。
一个例子:
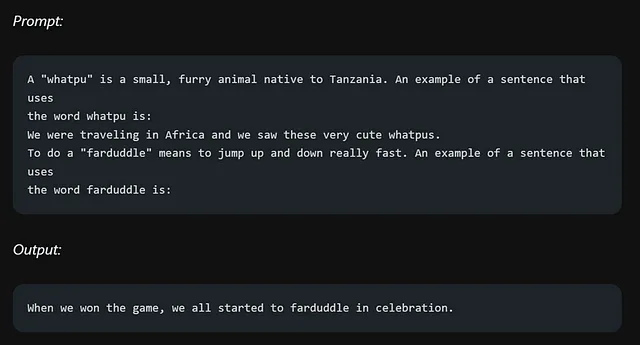
首先,我们向我们的模型提供了“whatpu”这个词的定义。然后,我们给出了一个包含“whatpu”这个词的例句,然后要求模型用这个词造一个句子。
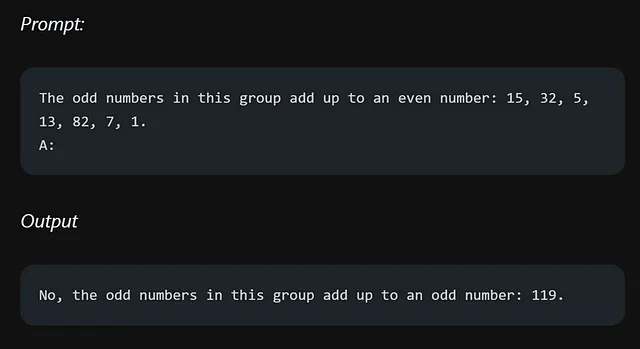
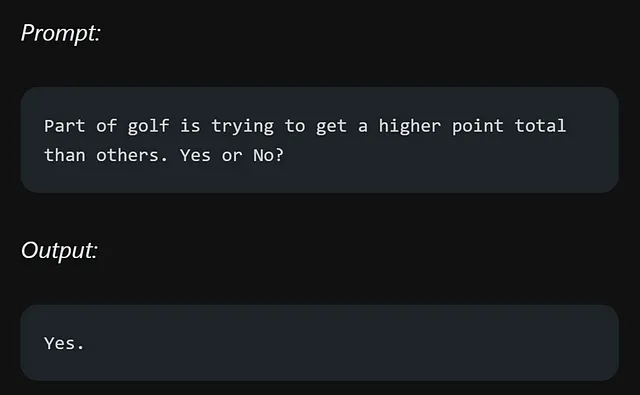
如果我们记得正确,在我们之前的推理提示中,我们要求模型添加奇数并确定结果是否为偶数。现在,让我们尝试使用几次尝试的方法解决同样的问题。
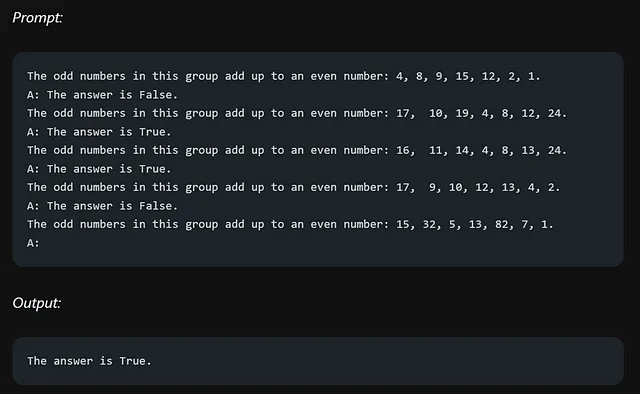
不幸的是,少样本提示的方法对于这个推理问题并没有产生可靠的响应。似乎需要采用其他技术或方法才能在这种情况下获得更准确和一致的结果。
链式思维提示
思维链 (CoT) 促进,当与少量提示一起使用时,可以增强模型对复杂任务的推理能力。它将问题分解为较小的步骤,使模型能够在提供答案之前经过中间阶段的推理。这种组合对于完成需要推理的挑战性任务的结果更好。
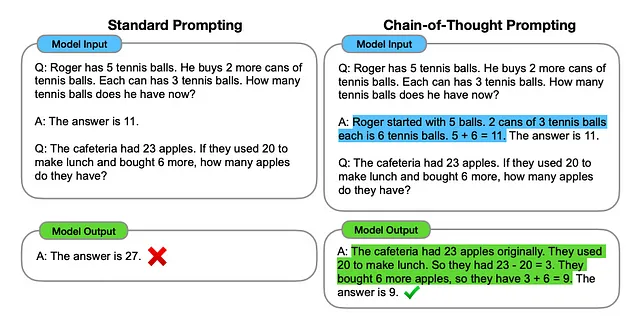
将复杂问题分解成子问题显著有助于LM提供准确和适当的回答。它使模型能够分别推理每个子问题,从而更全面地理解整个问题并生成更可靠的答案。
让我们尝试使用COT提示来解决我们的奇数相加任务:
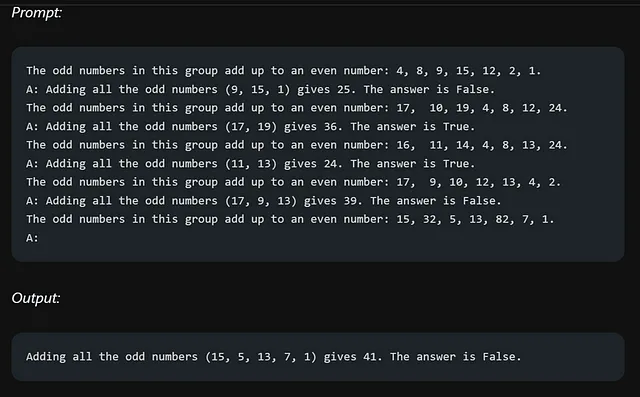
这次的答案是正确的,是因为在解决问题的过程中提供了推理步骤。
通过将零-shot提示与Chain-of-Thought(CoT)提示相结合,我们可以鼓励模型逐步思考,以解决问题。
这是一个例子。

零射和少射结合思维链触发(CoT)在解决语文问题时表现出优越性能,相较于其他方法。通过结合两种技术,模型能够逐步推理并生成准确的回答,即使在具有挑战性的问题解决情境中也能如此。
自恰性
自一致性是一个在提示工程中应用的先进技术,可以提高少样本"Chain-of-Thought"(CoT)提示的性能。它通过使用CoT提示生成多个回答,并选择最一致的答案来实现。这项技术对于涉及算术和常识推理的任务特别有用,因为它增强了模型回答的准确性。
以下是一个非常简单的算术任务的例子:
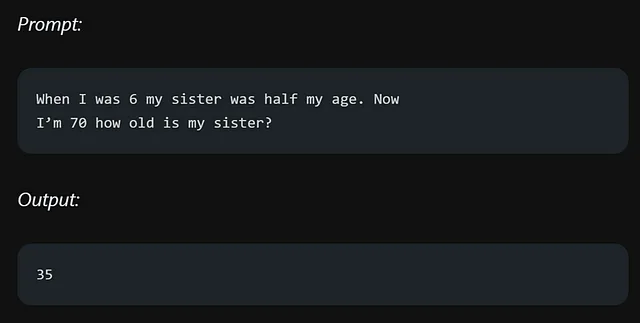
答案是错误的,通过使用自洽性在提示工程中,我们可以提高我们的模型在回答特定问题等任务中的性能。
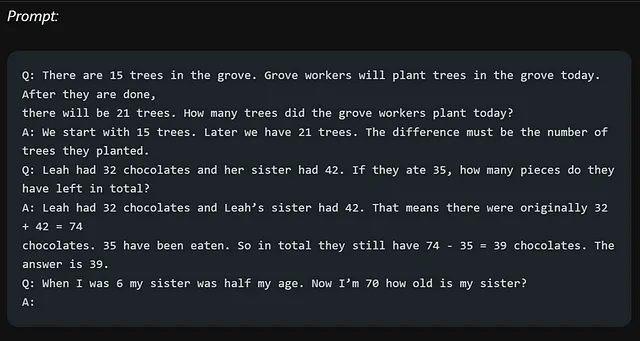
在"思维链" (CoT)启示的背景下,我们会提出多个问题,并为每个问题提供答案。最后一个问题是我们需要回答的问题。通过采用这种方法,我们可以引导模型生成更准确和一致的回答。
以下是多个输出结果:
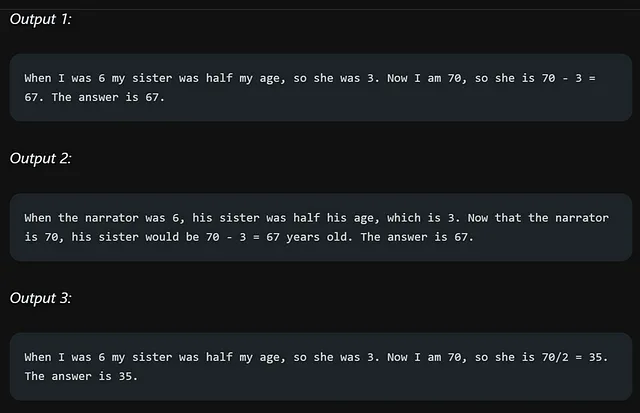
我们使用自洽技术计算最终答案,涉及到额外的步骤。有关该过程的更详细信息,您可以参考题为《自洽训练用于组合推理》的论文,该论文可在以下链接中找到:https://arxiv.org/pdf/2203.11171.pdf。该论文提供了关于在组合推理任务背景下有效应用自洽训练的深入见解和技巧。
生成知识激励
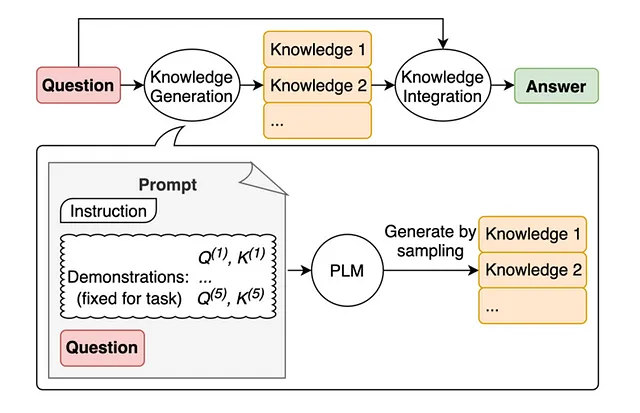
在提示工程中,一种流行的技术是将知识或信息融入模型以提高其预测准确性。通过提供与任务相关的相关知识或信息,模型可以利用这些额外的背景来进行更准确的预测。这种技术使得模型能够利用外部资源或现有知识来改善其理解能力并生成更为明智的回应。
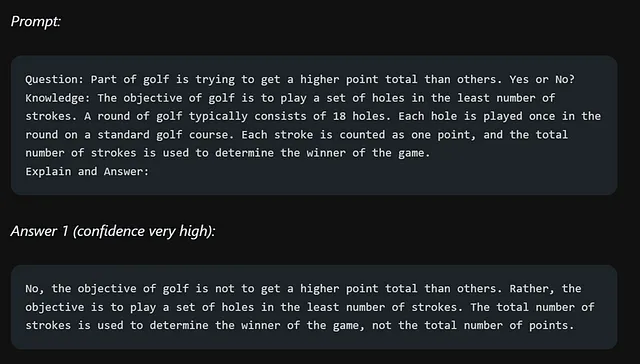
以下是为什么知识重要的一个例子:
这个错误表明,LLMs在需要更深入了解世界的任务中存在局限性。
让我们通过不仅仅回答问题,而且在途中传递一些知识来提升这个内容。
例如,主动提示是一种动态引导语言模型产生所期望输出的技术。定向刺激引导则探索了将模型引导到特定方向的方法。ReAct专注于通过主动学习和迭代反馈提高模型性能。这只是众多令人兴奋的领域中的几个例子。
前导工程涵盖了多样的应用,如生成数据、生成代码以及研究毕业生职位分类案例。您还可以深入研究不同的模型架构,例如Flan、ChatGPT、LLaMA,并且了解备受期待的GPT-4。此外,了解与前导工程相关的风险和潜在的滥用问题是至关重要的,如对抗性提示、事实性问题以及模型中的偏见。
为了扩大你的知识,你可以探索与提示工程相关的论文、工具、笔记本和数据集。这些资源将为你提供宝贵的见解和额外的阅读材料,进一步加强你对这个迷人领域的理解。所以,抓住官方指南,踏上你自己对提示工程广阔可能性的探索之旅吧!