ChatGPT的心理学
不仅Open AI的ChatGPT(一种基于聊天的生成预训练变压器)迎来了用户界面的新时代,它的采用率也让人惊讶。随着这种大型语言模型在以前未受自动化影响的普遍领域广泛采用,我们还有很多要学习的地方,以最佳方式将数字助理的维度融入我们使用的产品和服务的现有生态系统中,从而提高使用者的生活质量,而不是降低其质量。就我个人而言,我认为作为产品研究人员的工作从来没有比现在更重要,当然,关于人类未来的前景,没有缺少像这里、这里和这里这样的文章综合描绘出了一幅黯淡的图景。好消息是,研究人员的工作变得比以前更有价值。《华尔街日报》的以下文章就是一个很好的例子。询问问题已经成为产品研究人员日常工作的重要组成部分。
现在,你准备好听坏消息了吗?截至目前,要实现人工通用智能(简称AGI),我们还有很长的路要走,尽管根据你和谁交谈的情况,可以说摩尔定律已经几乎死亡,这是半导体行业中无限倍增计算能力的概念的关键时刻(这个概念是关于在单个芯片中塞入尽可能多的晶体管),现在也适用于大量的数字信息。关于合成用户、LLMs的潜在危害以及Open AI首席执行官最近的证言,他承认这项技术需要联邦监管,使我们这些负责将这些能力带给世界的人的集体责任似乎不可逾越。但是,我们可以直面这个问题,一次解决一个偏见。
微软多年来一直拥有如何将大型语言模型(LLMs)整合到其产品和服务生态系统中的前排视角——与其他有能力向其专门的数据科学家和工程师社区学习的大型IT集团一起。去年11月与Open AI达成数十亿美元合作伙伴关系的宣布之前,我们已经有很多机会直接向我们内部的技术专家社区学习,对于了解其功能以及如何学习基本的‘提示工程’也一直充满了兴趣。但是这些会议总是感觉缺少了一些东西,这促使我进行了自己的调查,并整理了我至今所学到的内容,以交互式研讨会的形式向我们内部的交互设计师和研究人员社区呈现。研讨会的形式受到了微软设计与人工智能副总裁约翰・梅达(John Maeda)使用“番茄酱瓶时刻”和“用语义内核烹饪”等概念教授复杂概念的启发。所以,话不多说,让我们开始烹饪吧!
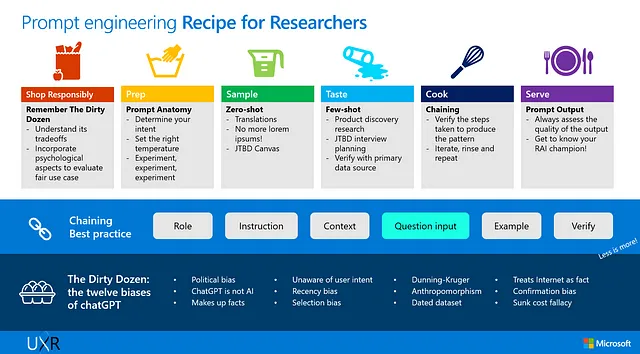
一旦确定想要做的事情,烹饪的第一步是什么?当然是收集所需的所有食材。我将这部分称为"Dirty Dozen",即ChatGPT的十二种偏见,产品研究人员(但实际上是任何希望获得更好结果的人)需要注意的。
1. ChatGPT倾向于政治左翼。

在最近一篇探讨大型语言模型(LLM)算法偏见的论文中,David Rozado(2023)对ChatGPT进行了15个政治取向测试,并发现其中14个测试显示出左倾政治观点,尽管声称具有政治中立性。像ChatGPT这样的人工智能系统可以在大多数规范性问题上声称政治中立性和事实准确性,同时展示出政治偏见,这可能影响人们的感知并对社会产生控制力,从而为用户在输出中寻求更加平衡的结果提出了挑战。
2. ChatGPT 不是人工智能。
ChatGPT和基于LLM的其他交互式AI工具通过合成一个封闭箱LLM来生成一段文本,以尽可能接近用户请求的信息。
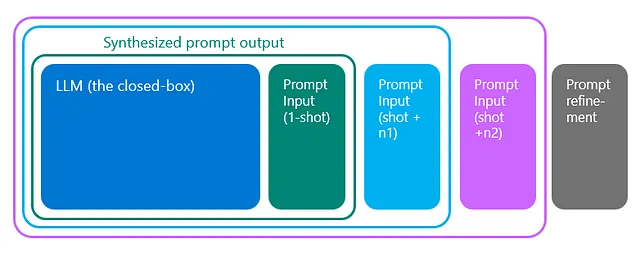
了解ChatGPT工作原理的最简单方法,除了自己向ChatGPT提问,还可以将其视为建立在以下前提下的模式综合引擎:通过提供大量数据集来训练模型,可以增加正确预测用户所要求结果的可能性。我们需要承认,在当前形式下,ChatGPT不仅会偶尔产生幻觉,而且这种幻觉是有意设计的,这也带我到下一个观点——
3. ChatGPT 幻想

以下是当前LLM倾向于模拟人类对话的一些常见倾向:它们生成的回答往往过于冗长,因为长篇回答乍一看可能更全面,但这与那些不知所云却试图混淆视听的人类类似。此外,也有很多用户发现有关人物、地点或事实的不准确信息混在似乎方向正确且熟练的内容中。
4. ChatGPT 不知道用户的意图
此外,由于它的工作是识别和生成模式,它没有能力在用户表面层面之外提出深层次的问题。这是为什么深思熟虑地设计提示非常重要,我们正在看到“提示工程”作为一种不断上升的技能集。
因此,您可能会邀请ChatGPT喝一两杯,但您不一定希望把它带到您的心理治疗师办公室。如果您正在寻求类似于聊天机器人的治疗体验,我建议尝试一下Woebot。
5. ChatGPT是具有人形特征的。
我们喜欢将ChatGPT视为一个推理引擎,但在我们达到科幻书籍和电影中经常浪漫化的人工通用智能水平之前,还需要一些时间。再次强调,从技术上讲,ChatGPT并不是人工智能。
“智能是个误称,”微软的产品设计师埃姆·艾弗斯说,他专门从事聊天机器人。 “虽然它看起来似乎很聪明,并以一种类似于人类推理的方式处理输入,但它背后并没有一个‘思考’实体。我们自己真正的大脑被连接到语言是附着在另一个人身上的这种观念所影响,但这是拟人化的。我们会给物体赋予它没有的特质,这在期望和现实之间存在着差距。”
如果你曾经发现自己拥有一袋剥离式粘性谷歌眼睛,并在附近随意将其粘在消防栓、树叶和邻居的垃圾桶之类的东西上,那么你知道你一直在拟人化。

6. ChatGPT存在选择偏见。
很重要的一点是要将包容性引入诸如ChatGPT这样的引擎,而不只是简单接受其输出结果。ChatGPT旨在产生输出中最可能的模式,正如我们已经确定的那样,这些模式不一定是事实,但它并不会停下来编造不存在的引文。根据设计,它通过学习常见模式来模仿人类推理。当意识到源数据中的偏见时,包容性增长就拥有了全新的意义,因为它很可能加强并延续W.E.I.R.D(西方、受教育、工业化、富裕、民主)数据的观点。

我有没有提到ChatGPT没有智能?
7. ChatGPT受到邓宁克鲁格效应的影响。
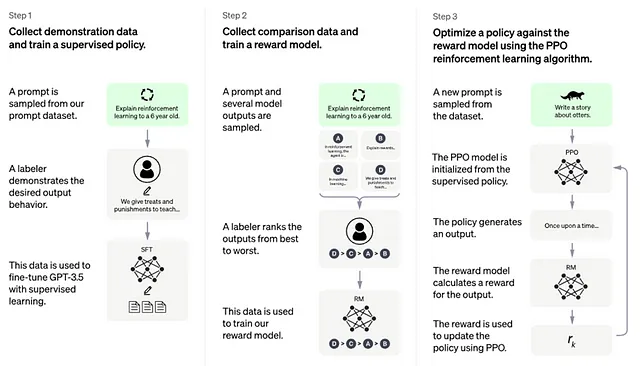
以下插图是OpenAI团队解释模型训练过程的方式,通过从人类反馈学习(RLHF)和近端策略优化(PPO)来“奖励”模型以获取更高质量的回答。它的工作是生成缺失的标记。在这个背景下,一个标记可以被认为是一个单词的音节。通过算法计数这些标记可以估计正在处理的信息量。对此的一个良好类比是想象一下公用事业如何被测量。在给定的计费周期内,你可以通过水龙头一次度量家庭的用水量,然后再通过排水口度量一次。
8. ChatGPT具有最近偏见。
ChatGPT的输出质量取决于两个元素:用户输入的质量和其所训练的语言模型的质量。

多次发问提示是一个技术术语,用于描述针对一个特定话题进行的多次对话,随着对话的进行,这种提示可能会失去准确性和价值,因为它有遗忘先前对话的倾向。ChatGPT的首个公开版本于2022年末发布,只能记忆最后的3000至4000个词。
9. ChatGPT是过去的一个快照
目前形式的LLMs的另一个限制是它是一个封闭系统,这意味着它在一段固定的时间内一次性被训练。尽管通过用户的输入和引导模型可以持续改进,但它经常错误地记载历史日期,并且并不总是具备最新的信息。
10. ChatGPT通过“互联网”进行训练。
此外,ChatGPT并不了解在网上所能得到的现实世界的限制条件。此外,它还是基于我们不一定想要在结果中看到的数据进行训练的,比如基于观点的社交媒体网站如Twitter和Reddit的数据。公开可获得数据的伦理问题是一个不断发展的辩论,以及可能产生我们不希望看到的后续影响的解决方案的有意应用。以下是Indy Young提供的一个坚实的起点框架,用于思考对人们可能造成的潜在伤害。
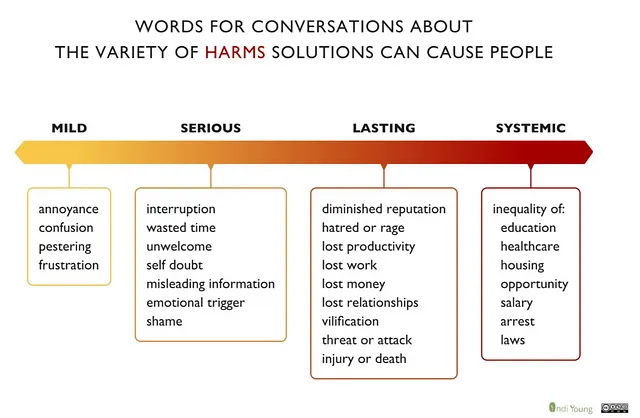
如果您对了解负责任人工智能的原则以及微软如何减轻ChatGPT等产品的有害使用感兴趣,这是一个很好的开始的地方。
11. 识别塞梅尔维斯反射:当人工智能无处安放
恰当赋予 ChatGPT 人类特质的是其表现出了塞梅尔维斯效应,这是一种人类行为倾向,即坚持现有的信念并拒绝与之相悖的新观点。

12. 沉没成本谬误
随着ChatGPT等基于意图的交互工具的普及,我们需要审视我们决策中的技术中心主义,看看是如何带领我们走到这一步的。沉没成本谬误是一种心理障碍,它使人们只是因为已经投入了大量资源,而执着于不成功的事业。
这些是ChatGPT在开箱即用时给用户带来的“十二宗罪”偏见,没有任何额外的训练和定制。它是一个强大的推理引擎。了解这些偏见可以帮助我们对其能力有更健康的期望,并促使我们考虑增加创造性价值的使用案例,以及提供良好回报的投资。
在我们结束之前,还有一个点与ChatGPT的心理方面可能不直接相关,但了解这一点可能会改变我们在衡量继续使用像ChatGPT这样强大推理引擎的成本和收益时的观点。
13. ChatGPT 不会帮助改善气候问题
今天我们需要5套80吉字节的A100系列GPU(图形处理单元),只是为了加载模型和文本。GPU具有高功耗和热量产生,运行它们的数据中心需要持续的冷却以保持处理器的正常运行。为了使数据中心正常运行的环境控制消耗的电量和服务器本身一样多,这是令人震惊的。

最后但同样重要的是,我想邀请您去必应人工智能聊天室,点击“立即聊天”按钮,看看您能让ChatGPT想出多少个这些偏见。如果您发现了本文中没有提到的其他偏见,请在下方留言。