细调Llama 2.0,使用单个GPU魔法
高效地调优你自己的语言模型
介绍
自然语言处理领域在像ChatGPT这样的大型语言模型(LLMs)的推动下取得了令人难以置信的进展。然而,这些模型也有其局限性。它们可能引发隐私问题,遵循一套固定的规则,并且受限于其最后训练的日期。像PaLM和GPT-3.5这样的预训练LLM的另一个局限性是它们不是开源的。这意味着开发者和研究人员无法访问模型的内部工作原理,限制了他们对其进行微调和定制以适用于特定用例的能力。
庆幸的是,由Meta推出的开源LLM LLama 2.0带来了一个新时代,它允许在您自己的数据集上进行精细调整,减轻隐私关注并实现个性化的人工智能体验。此外,创新的QLora方法为单个GPU提供了一种有效的LLM精细调整方式,使得按个人需求定制模型更加容易和经济实惠。
介绍LLama 2.0:新的可能性的新视角
梅塔最新的创新作品,LLama 2.0,发布了一系列经过预训练和优化的模型,参数数量从70亿到惊人的700亿不等。这个令人印象深刻的产品系列包括:
- LLama 2:作为LLama 1的升级版,它使用了来自多个公开可用资源的更新的训练数据。它提供三种变体:7B、13B和70B参数。
- LLama 2-Chat:LLama 2的优化版本,专门针对基于对话的用例进行了精细调节。与LLama 2一样,它提供三个变体:7B、13B和70B参数。
Llama 2.0 引入了重大的改进,
- 将上下文窗口从2048扩展到4096个标记,使模型能够处理更多的信息。
- 为了解决关注力随令牌数量呈平方成本增长的问题,作者们引入了分组查询关注机制,通过在多个头部之间共享关键查询和值投影。
- 利用更多的数据进行训练,结合通过网络抓取的数据和根据人工注释者的反馈进行微调的数据。模型明智地选择使用公开数据,以确保与开源平台的兼容性,同时减少可能由数据使用引起的法律问题。
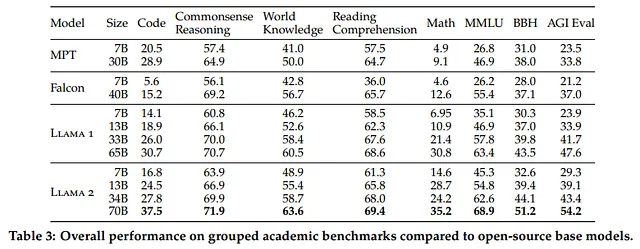
结果显示,Llama 2.0在各种基准测试中胜过开源模型。尽管与GPT-4和PaLM等闭源模型相比有些不足,但考虑到它们显著更大的参数大小和使用私有数据进行训练,这是可以预期的。整个LLama 2系列模型都是一个开源的宝库,可供研究和商业使用,没有任何费用。
参数高效微调(PEFT):QLoRA
保持HTML结构,将以下英文文本翻译成简体中文: 在自己的数据集上进行语言模型微调的潜力是无与伦比的。然而,这个过程通常需要大量的GPU内存,而且是一个资源密集型的工作。例如,对一个拥有650亿个参数的模型进行微调需要惊人的780 GB的GPU内存,相当于十个A100 80 GB的GPU。这样的资源需求妨碍了对消费者硬件实现无缝微调的进程。
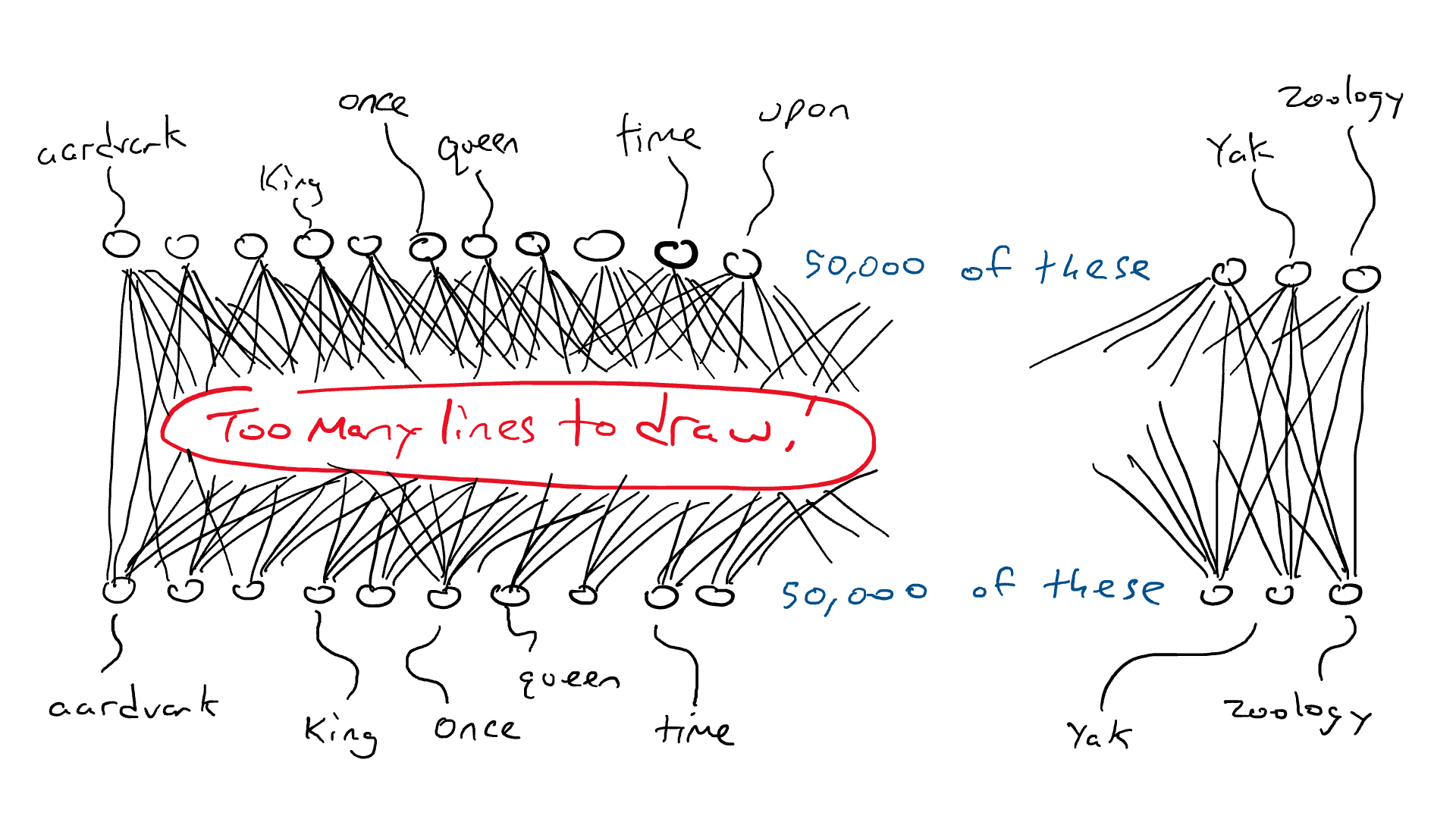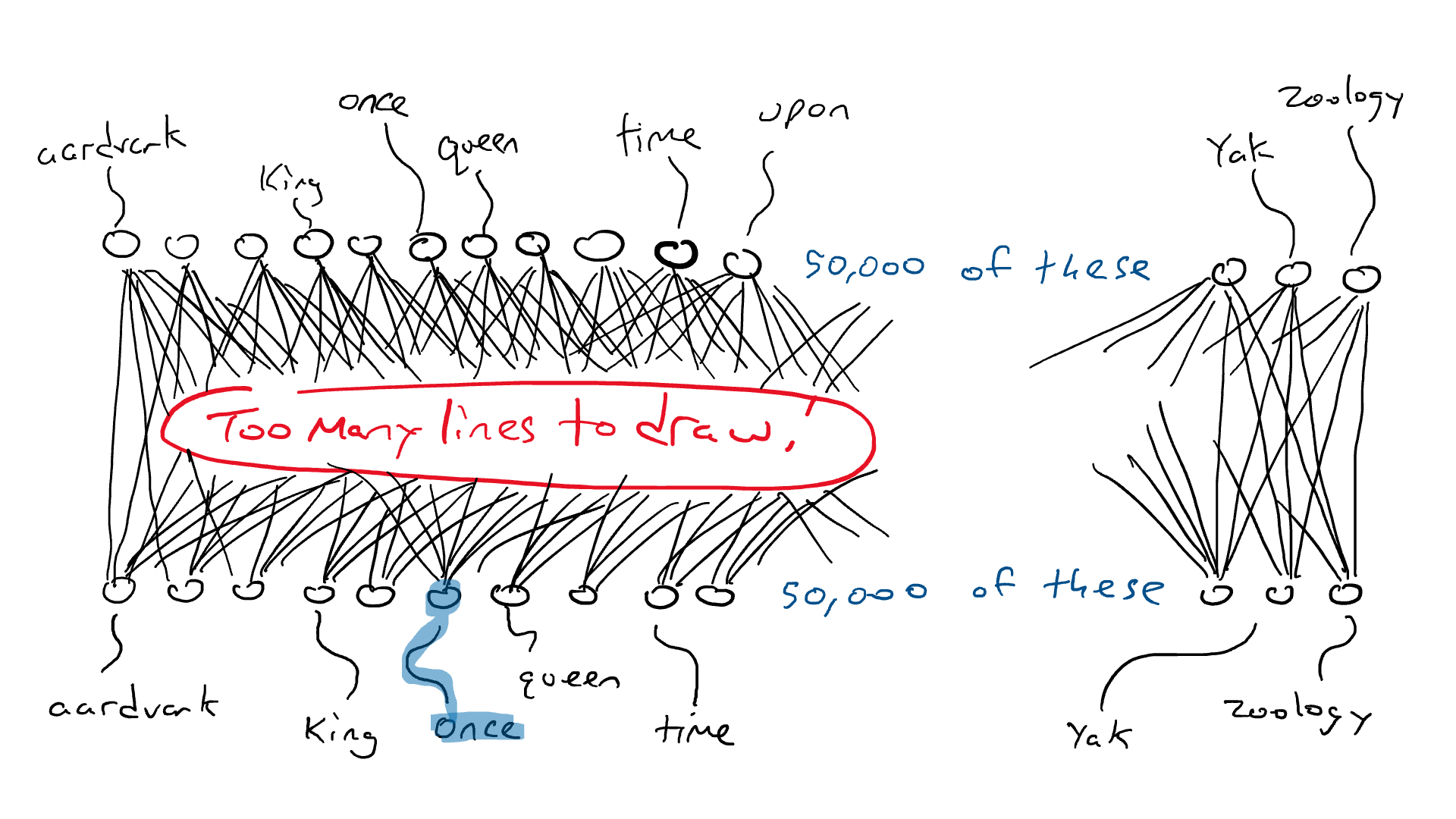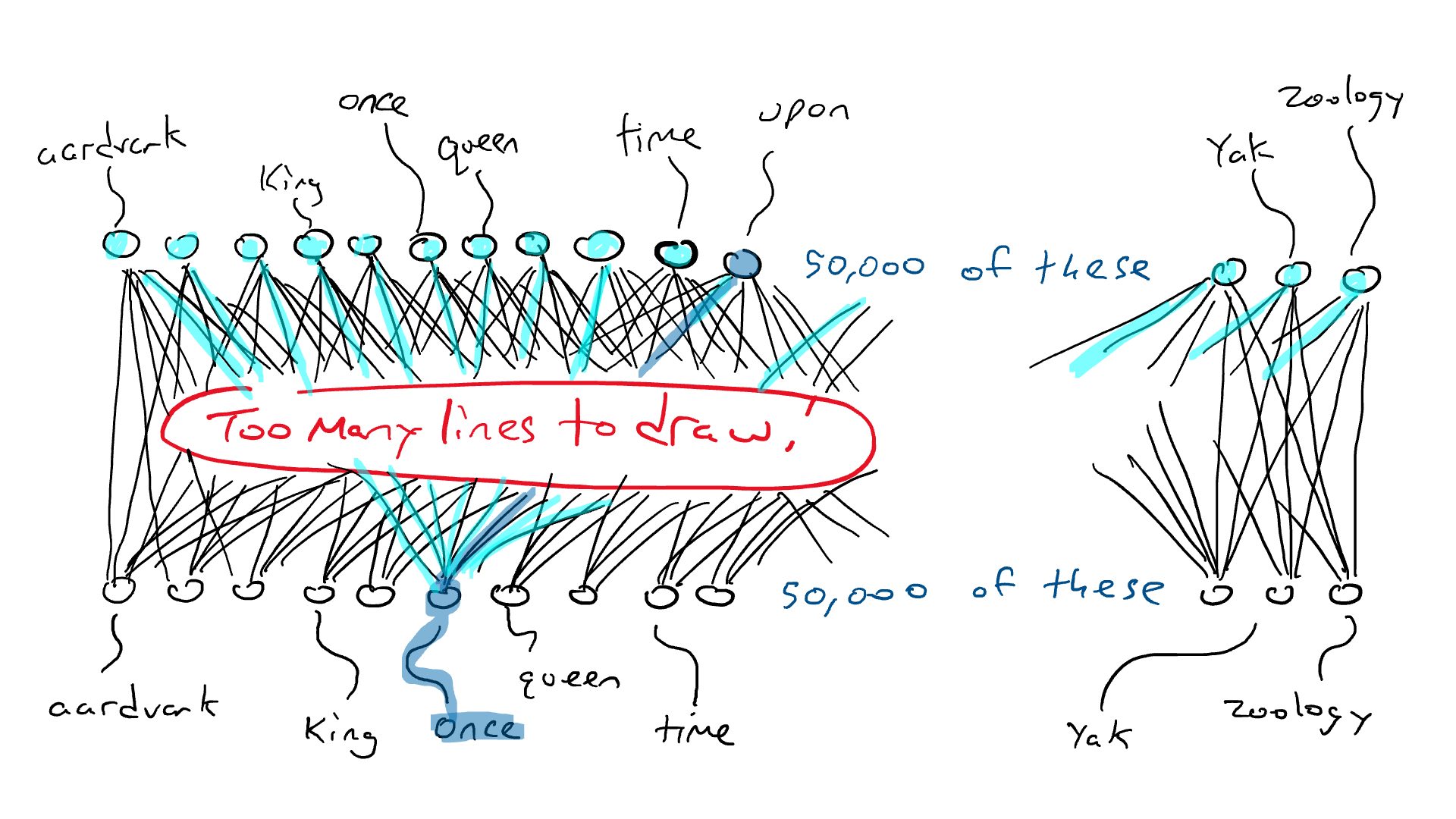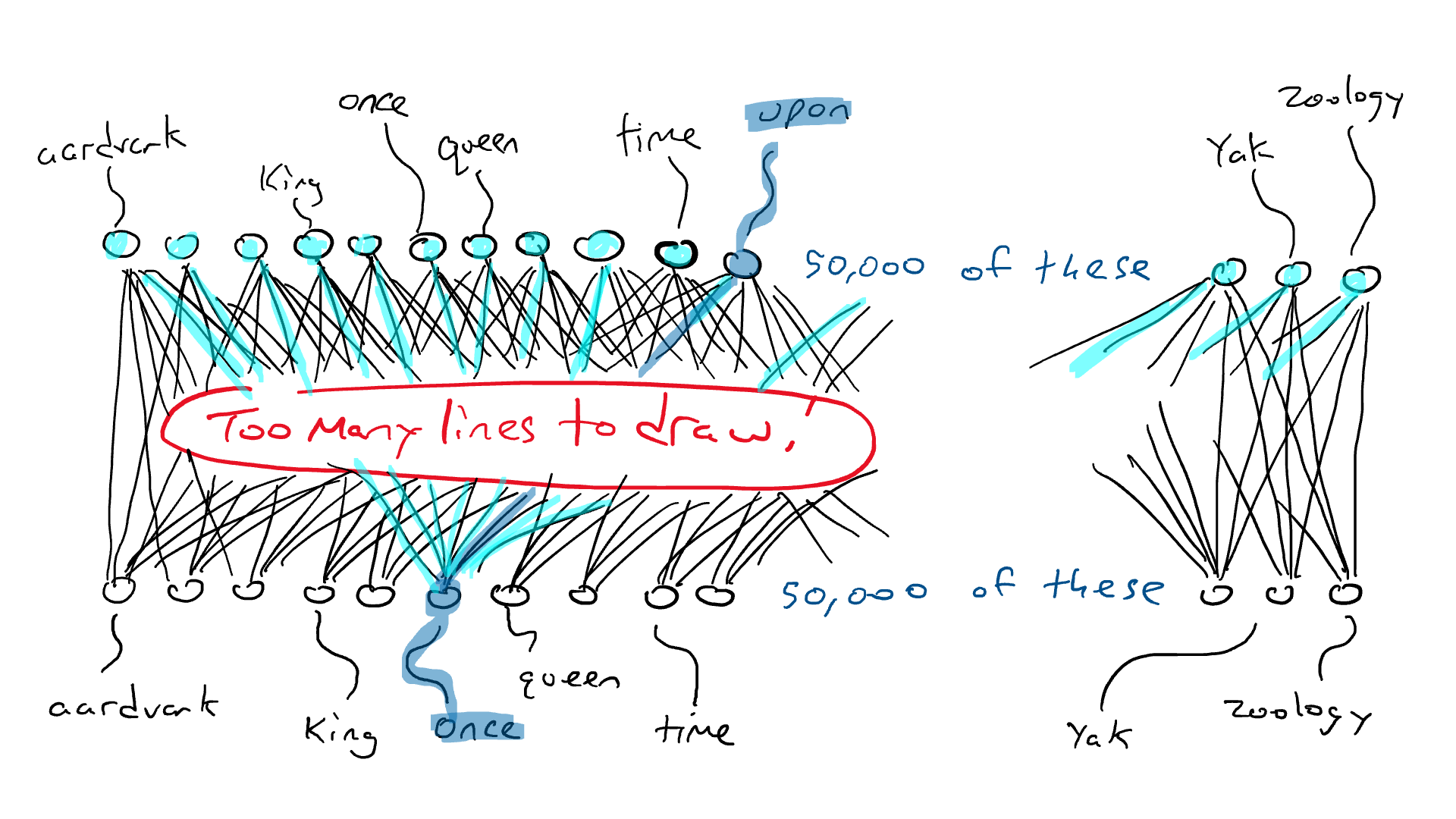
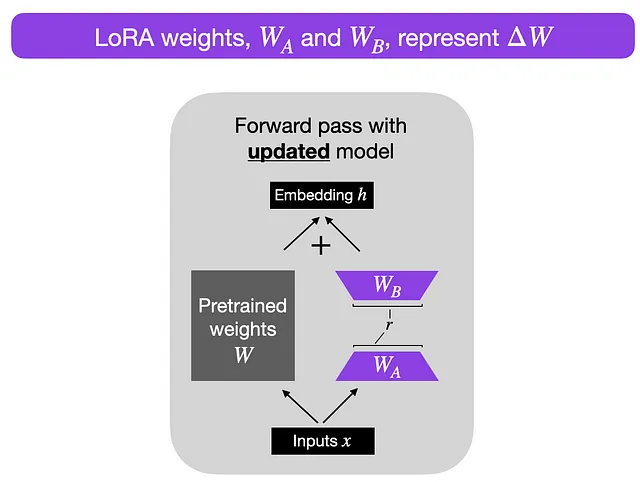
这就是LoRA: 由EJ Hu在2021年引入的大型语言模型低秩适应(Low-Rank Adaptation)进入革新领域的地方。 LoRA的架构涉及冻结预训练模型权重,并在矩阵中训练额外的权重变化,而不牺牲关键信息。 这个过程发生在Transformer架构的每一层。
考虑一个 A × B 权重矩阵的权重更新矩阵 ΔW。我们可以将 ΔW 分解为两个较小的矩阵 WA 和 WB,使得 ΔW = WA * WB。在这里,WA 是一个 A × r 维度的矩阵,而 WB 是一个 r × B 维度的矩阵。关键思想是保持原始权重 W 不变,只训练新的矩阵 WA 和 WB。这种简洁的方法描绘了 LoRA 方法的本质,如附图所示。
将以下英文文本翻译为简体中文并保留HTML结构: QLoRA(Quantized LLMs的高效微调),由Dettmers等人于2023年引入,进一步推进了LoRA。
- 4位正常浮点量化:QLoRA引入了一种新颖的量化方法,改进了传统的分位数量化。4位正常浮点量化确保每个量化箱中具有相等数量的值,从而减轻了异常值的计算问题和误差。
- 双重量化:QLoRA采取了更进一步的措施,对量化常数进行量化,从而实现了额外的内存节省。这种巧妙的方法在保持总体性能的同时压缩了模型信息。
- 使用统一内存进行分页:借助NVIDIA统一内存功能,QLoRA协调CPU和GPU之间的无缝页到页传输。这种智能内存管理保证了GPU处理的无误,即使GPU面临内存限制的情况下也是如此。
实施
开始使用
好的,理论够了!让我们直接进入技术部分,从头开始编码。首要事项是我们需要安装并导入所需的库,以便开始实施。让我们开始吧!
pip install transformers datasets peft accelerate bitsandbytes safetensorsimport os, sys
import torch
import datasets
from transformers import (
AutoTokenizer,
AutoModelForCausalLM,
BitsAndBytesConfig,
DataCollatorForLanguageModeling,
DataCollatorForSeq2Seq,
Trainer,
TrainingArguments,
GenerationConfig
)
from peft import PeftModel, LoraConfig, prepare_model_for_kbit_training, get_peft_model模型加载
### config ###
model_id = "NousResearch/Llama-2-7b-hf"
max_length = 512
device_map = "auto"
batch_size = 128
micro_batch_size = 32
gradient_accumulation_steps = batch_size // micro_batch_size
# nf4" use a symmetric quantization scheme with 4 bits precision
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
# load model from huggingface
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
use_cache=False,
device_map=device_map
)
# load tokenizer from huggingface
tokenizer = AutoTokenizer.from_pretrained(model_id)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"现在让我们向前迈进一步,从Hugging Face下载令人印象深刻的Llama 2.0模型和分词器“NousResearch/Llama-2-7b-hf”。代码还指定了BitsAndBytesConfig对象,用于双重量化和4位模型格式,以优化模型的性能。
def print_number_of_trainable_model_parameters(model):
trainable_model_params = 0
all_model_params = 0
for _, param in model.named_parameters():
all_model_params += param.numel()
if param.requires_grad:
trainable_model_params += param.numel()
print(f"trainable model parameters: {trainable_model_params}. All model parameters: {all_model_params} ")
return trainable_model_params
ori_p = print_number_of_trainable_model_parameters(model)同时,我们创建了一个方便的辅助函数称为“print_number_of_trainable_model_parameters”,以检查原始模型的可训练参数。运行此函数后,它会提供输出可训练模型参数:262,410,240。
# LoRA config
model = prepare_model_for_kbit_training(model)
peft_config = LoraConfig(
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["q_proj", "v_proj"],
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, peft_config)
### compare trainable parameters #
peft_p = print_number_of_trainable_model_parameters(model)
print(f"# Trainable Parameter \nBefore: {ori_p} \nAfter: {peft_p} \nPercentage: {round(peft_p / ori_p * 100, 2)}")接下来,我们可以开始将模型打包为LoRA格式,同时保持原始参数冻结,并引入之前讨论过的额外权重。LoRA模型具有几个可配置的参数:
- 确定更新矩阵的秩,也称为Lora注意力维度。较低的秩会导致较小的更新矩阵,可训练参数较少。增加r(不超过32)会使模型更稳健,但同时会增加内存消耗。
- lora_alpha 控制 LoRA 的扩展因子
- target_modules 是一个模块名称列表,例如 “q_proj” 和 “v_proj”,用作 LoRA 模型的目标。具体的模块名称可能根据底层模型而变化。
- 偏置:指定是否应训练偏置参数。可以是'none'(无),'all'(全部)或'lora_only'(仅Lora)。
在将模型与LoRA适配器连接后,让我们再次打印可训练参数,并将其与原始模型进行比较。值得注意的是,可训练模型参数:4,194,304,现在仅代表原始模型大小的不到2%。
### generate ###
prompt = "Write me a poem about Singapore."
inputs = tokenizer(prompt, return_tensors="pt")
generate_ids = model.generate(inputs.input_ids, max_length=64)
print('\nAnswer: ', tokenizer.decode(generate_ids[0]))
res = tokenizer.batch_decode(generate_ids, skip_special_tokens=True, clean_up_tokenization_spaces=False)[0]
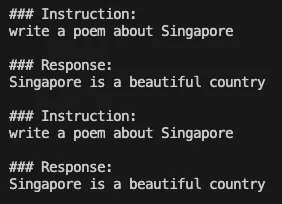
print(res)就在令人激动的微调过程之前,让我们不要忽略从预训练的语言模型生成输出并观察其反应的过程。在这种情况下,当要求模型写一首关于新加坡的诗时,生成的输出似乎相当模糊和重复,这表明模型难以提供一个连贯和有意义的回应。
数据加载
为了展示Fine-tuning Instruction-LLM的过程,我们将使用来自databricks / databricks-dolly-15k的公共数据集,该数据集呈现了一系列的指令-响应对。值得注意的是,这个数据集中的某些样本还包含上下文信息,为模型的理解过程增加了一层复杂性和丰富性。请允许我展示从这个有趣的原始数据中提取出来的一个引人入胜的样本记录。
{
'instruction': 'Why can camels survive for long without water?',
'context': '',
'response': 'Camels use the fat in their humps to keep them filled with energy and hydration for long periods of time.',
'category': 'open_qa',
}一个prompt_template被创建出来以增强模型的学习能力。这个巧妙的模板由两种不同类型组成:prompt_input和prompt_no_input。前者用于包含输入上下文的样本,而后者则适用于缺乏这种上下文信息的实例。通过将每个任务的指令与适当的上下文(如果可用)精确匹配,我们培养了模型内部的更深层次理解和上下文感知能力。
max_length = 256
dataset = datasets.load_dataset(
"databricks/databricks-dolly-15k", split='train'
)
### generate prompt based on template ###
prompt_template = {
"prompt_input": \
"Below is an instruction that describes a task, paired with an input that provides further context.\
Write a response that appropriately completes the request.\
\n\n### Instruction:\n{instruction}\n\n### Input:\n{input}\n\n### Response:\n",
"prompt_no_input": \
"Below is an instruction that describes a task.\
Write a response that appropriately completes the request.\
\n\n### Instruction:\n{instruction}\n\n### Response:\n",
"response_split": "### Response:"
}
def generate_prompt(instruction, input=None, label=None, prompt_template=prompt_template):
if input:
res = prompt_template["prompt_input"].format(
instruction=instruction, input=input)
else:
res = prompt_template["prompt_no_input"].format(
instruction=instruction)
if label:
res = f"{res}{label}"
return res我们首先使用generate_prompt函数将指令、上下文和回答组合起来生成完整的提示。一旦完整的提示被创建出来,我们就使用提供的tokenizer对其进行分词,将文本转化为input_ids和attention_mask。值得注意的是,为了训练模型预测下一个单词,我们将标签(类似于input_ids)指定为模型的输入,并通过训练器实现向右的偏移操作。然而,为了避免模型关注指令和上下文中的下一个单词,我们将这些段中的所有原始标记都屏蔽掉,用-100替换,只保留回答部分的输入。然后,数据被进一步组织成训练集和验证集,并移除不必要的列,从而形成一个经过精炼和高效处理的用于训练的数据集。
def tokenize(tokenizer, prompt, max_length=max_length, add_eos_token=False):
result = tokenizer(
prompt,
truncation=True,
max_length=max_length,
padding=False,
return_tensors=None)
result["labels"] = result["input_ids"].copy()
return result
def generate_and_tokenize_prompt(data_point):
full_prompt = generate_prompt(
data_point["instruction"],
data_point["context"],
data_point["response"],
)
tokenized_full_prompt = tokenize(tokenizer, full_prompt)
user_prompt = generate_prompt(data_point["instruction"], data_point["context"])
tokenized_user_prompt = tokenize(tokenizer, user_prompt)
user_prompt_len = len(tokenized_user_prompt["input_ids"])
mask_token = [-100] * user_prompt_len
tokenized_full_prompt["labels"] = mask_token + tokenized_full_prompt["labels"][user_prompt_len:]
return tokenized_full_prompt
dataset = dataset.train_test_split(test_size=1000, shuffle=True, seed=42)
cols = ["instruction", "context", "response", "category"]
train_data = dataset["train"].shuffle().map(generate_and_tokenize_prompt, remove_columns=cols)
val_data = dataset["test"].shuffle().map(generate_and_tokenize_prompt, remove_columns=cols,)模型训练
随着对数据和模型进行广泛准备,现在是开始训练过程的时刻。拥有灵活性,可以根据需要微调训练者的设置,在Google Colab上进行了关键的五小时训练,运行了200步。
args = TrainingArguments(
output_dir="./llama-7b-int4-dolly",
num_train_epochs=20,
max_steps=200,
fp16=True,
optim="paged_adamw_32bit",
learning_rate=2e-4,
lr_scheduler_type="constant",
per_device_train_batch_size=micro_batch_size,
gradient_accumulation_steps=gradient_accumulation_steps,
gradient_checkpointing=True,
group_by_length=False,
logging_steps=10,
save_strategy="epoch",
save_total_limit=3,
disable_tqdm=False,
)
trainer = Trainer(
model=model,
train_dataset=train_data,
eval_dataset=val_data,
args=args,
data_collator=DataCollatorForSeq2Seq(
tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True),
)
# silence the warnings. re-enable for inference!
model.config.use_cache = False
trainer.train()
model.save_pretrained("llama-7b-int4-dolly")
一代人
训练了几个小时的单个GPU后,现在是时候使用之前使用过的输入提示“给我写首关于新加坡的诗”来测试模型的性能了。代码片段首先加载了预训练的Llama-2–7b-hf模型和Peft权重。模型的生成配置被设置为控制因素,例如
- 温度控制生成过程的随机性。当温度较高时,生成器更为随机,产生多样但连贯性较差的输出。当温度较低时,生成器较不随机,产生更连贯但多样性较低的输出。
- 从一组生成的选项中选择最有前途的候选人。"top-p"中的"p"代表"概率",它指的是给定候选人是最佳选项的概率。
- top-k 与 top-p 类似,但是不同的是它选择具有最高概率得分的固定数量的候选项,而不是选择候选项的百分比。
- 在Beam搜索算法中,"num_beam" 允许模型同时考虑多个可能的输出。它通过维护一组可能的输出,称为 "beam",并通过添加可能正确的新输出来迭代地扩展 "beam" 来工作。
# model path and weight
model_id = "NousResearch/Llama-2-7b-hf"
peft_path = "./llama-7b-int4-dolly"
# loading model
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
use_cache=False,
device_map="auto"
)
# loading peft weight
model = PeftModel.from_pretrained(
model,
peft_path,
torch_dtype=torch.float16,
)
model.eval()
# generation config
generation_config = GenerationConfig(
temperature=0.1,
top_p=0.75,
top_k=40,
num_beams=4, # beam search
)
# generating reply
with torch.no_grad():
prompt = "Write me a poem about Singapore."
inputs = tokenizer(prompt, return_tensors="pt")
generation_output = model.generate(
input_ids=inputs.input_ids,
generation_config=generation_config,
return_dict_in_generate=True,
output_scores=True,
max_new_tokens=64,
)
print('\nAnswer: ', tokenizer.decode(generation_output.sequences[0]))该模型的输出与预训练模型相比,现在显示出了有希望的改进。虽然结果可能不能满足我们高度诗意的期望,但是必须考虑到我们使用的是最小的可用的7b-Llama2.0模型,并且仅在有限权重下使用Lora进行了短时间训练。尽管如此,考虑到限制条件,这个结果已经令人印象深刻。

除了对预训练的原始模型Llama 2.0进行微调外,还有另一种诱人的选择:利用“meta-llama/Llama-2–7b-chat-hf”,这是一个经过对话优化的模型,能够理解和遵循指导。从这个对话模型出发,将它作为基础是一种战略性的方法,可以根据您自己的私有数据来定制模型。
结论
结合LLama 2.0的优势和Qlora的高效性,打开了无与伦比的人工智能个性化大门。通过使用最新的开源模型在自己的数据集上进行精细调整的能力,将人工智能应用推向了新的相关性和定制化高度。Qlora的资源高效方法使精细调整民主化,即使在单个GPU上也可以无缝训练。
随着人工智能领域的发展,负责任地推动人工智能的发展变得至关重要。道德考虑、公正和包容性应成为我们在追求创新人工智能应用的道路上的指导原则。凭借LLama 2.0和Qlora,我们具备了将人工智能塑造成个性化、以人为本的体验,造福于所有人的能力。人工智能的未来确实令人兴奋,其可能性是无限的!祝您优化成功!🚀
🌟 如果您觉得这篇文章有意义,并希望随时了解我未来的文章,请考虑在Medium上关注我。我非常期待在接下来的几周与您分享更多有价值的见解和引人入胜的内容。