革新ServiceNow体验:使用OpenAI嵌入与语义搜索来进行文档聊天
赋予用户智能文档检索功能

介绍
在不断发展的企业解决方案领域中,ServiceNow已成为一个改变态势的平台,它能够简化业务操作、赋予IT部门权力,并提升组织内用户体验。然而,随着数字时代的到来,ServiceNow内部的数据和文档数量往往令人不知所措。在正确的时间找到正确的信息已成为一个关键的挑战。
想象一个世界,在这个世界里,您可以通过自然语言对话与您的ServiceNow文档进行无缝互动,就像与可信赖的同事聊天一样。想象一种场景,ServiceNow用户可以轻松地检索相关文档、获取见解,并在不费力地搜索复杂查询或筛选文件夹的情况下做出明智决策。
这就是OpenAI Embedding和语义搜索的融合所带来的革新ServiceNow体验的地方。在本文中,我们将踏上一段旅程,探索整合OpenAI领先的嵌入技术和语义搜索能力如何释放您的ServiceNow平台的全部潜力。我们将探索向量数据的强大功能,深入研究语义搜索的复杂性,并为您提供一个全面指南,以实施这个具有颠覆性的技术。
目录
- 理解术语
- 项目路线图
- 高级实施步骤
- 开始实施指南
- ServiceNow在人工智能的未来
- 结论
了解术语
在我们继续实施之前,让我们以非专业人士易懂的方式了解一些术语。
嵌入:嵌入就像给每个单词赋予一个特殊的数字,使计算机能够更轻松地理解和处理单词。这些数字帮助计算机比较单词,找到相似之处,并更快、更准确地完成与语言相关的任务。这就像为计算机创建一种秘密语言,以更好地理解单词。
向量存储器:向量存储器就像一个特殊的容器(数据库),我们在其中保存有关单词及其相应嵌入的信息。想象每个单词都有一组独特描述它的数字。这些数字就像一个秘密代码,帮助计算机理解单词的意义以及它们之间的关系。因此,当您向计算机提问或希望它为您找到某些东西时,它可以使用这些特殊代码更快、更好地解决问题,就像宝藏地图帮助您找到隐藏的宝藏一样。
语义搜索:语义搜索就像一个超级智能的搜索引擎,它理解词语和短语的含义,而不仅仅是你键入的准确词语。就好像你向它提问,它会找到符合逻辑的事物,即使词语有些不同。例如,如果你想要关于可爱小狗的信息,它不仅会找到与“小狗”有关的背景,还会找到与可爱狗相关的背景,因为它知道它们之间的关联。就像拥有一个理解你真正意思的搜索伙伴,而不仅仅是你使用的词语,这样你就可以轻松地找到最有用的信息。
项目路线图
在我们开始之前,请看一下这个流程图。
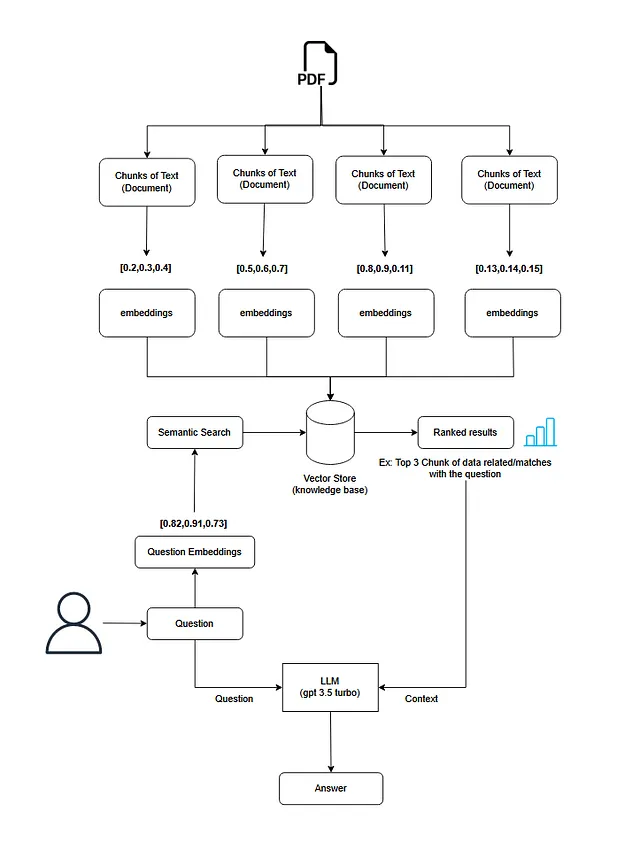
实施的高级步骤
让我们分析流程并分解成几个步骤。请注意,您可以使用任何其他工具/供应商来实现相同的期望结果,根据您的意愿。
第一步:获取文档文件
第一步是从用户那里获取文档文件。我将使用ServiceNow的虚拟代理的"文件选择器"组件。在这次实现中,我只覆盖了PDF。
第二步:从文档中检索文本
接下来,我们将从文档中提取所有的文本内容。我使用了一个第三方API服务提供商ConvertAPI来从PDF文件中提取文本。
步骤3:将文本分成较小的块
我们将把PDF文档中的大段文本分割成较小的块。这种分割是必需的,因为我们只需要与用户问题和LLM模型(如gpt-3.5 turbo)相关的上下文,并且这些模型有一些字符限制。
步骤4:创建所有块的嵌入
完成这一步骤后,我们将把所有的块嵌入到向量中。为此,我使用了OpenAI嵌入技术。OpenAI的文本嵌入非常强大且高效。
步骤5:将嵌入存储在向量数据库中
接下来,我们将把这些块及其相应的嵌入存储在一个向量数据库中。我已经使用了 Qdrant。你也可以使用 Pinecone。
步骤6:进行语义搜索并检索相似的块
现在我们将采用用户的问题,并使用相同的OpenAI文本嵌入技术进行嵌入。然后,我们将在我们的向量数据库中执行语义搜索,以检索与用户问题最相似的前3个文本块,并具有最高排名的结果。这些块的组合将成为我们的上下文。
步骤7:将用户问题与上下文一同传送给LLM模型。
我们然后将用户的问题连同我们在前一步中检索到的上下文传递给一个LLM模型(在我们的情况下是OpenAI的gpt-3.5-turbo)。
步骤8:从LLM获取结果并向用户展示
最后,我们将会把GPT生成的结果显示给用户。
开始实施
让我们首先设置这个项目的前提条件。
- 从这里创建一个OpenAI API密钥。
- 在此处创建一个ConvertAPI账户。前往账户中的身份验证并获取API密钥。
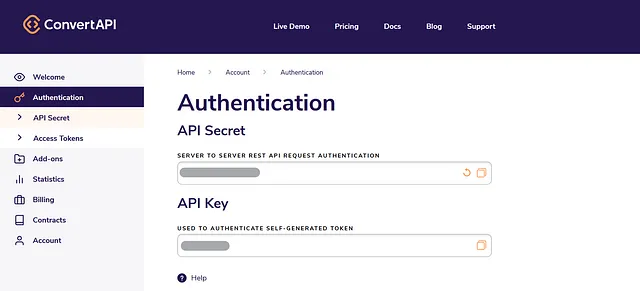
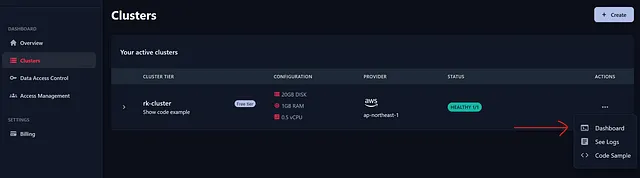
3. 在此处创建一个Qdrant账号。登录到Qdrant账户后,创建一个Cluster并生成一个用于访问的API密钥。同时复制您的Qdrant端点。
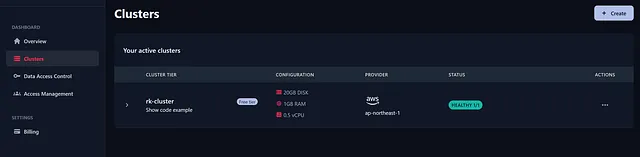
然后你需要创建一个集合,可以在其中存储点(向量)。为了创建集合,我使用了带有Qdrant的api密钥和端点的Postman。这只需要做一次。
在Postman中创建一个PUT HTTP方法,在授权下选择API密钥类型,然后将密钥输入为'api-key',值输入为>。
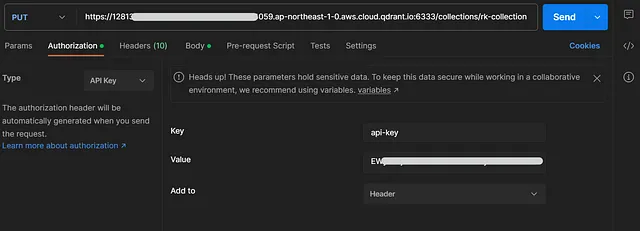
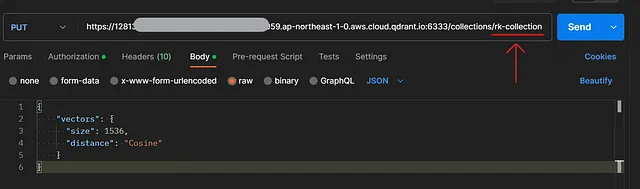
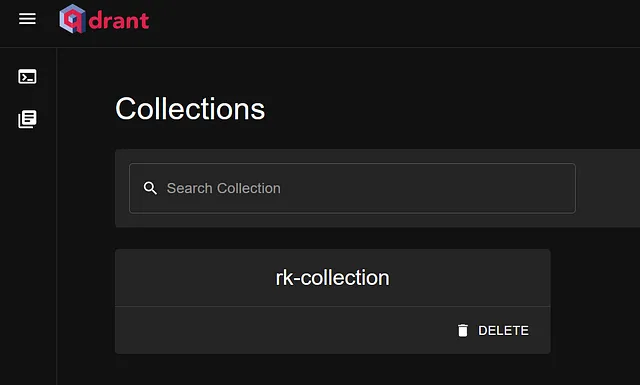
然后输入您的Qdrant终点,并将其附加到/collections/>。我将我的收藏名称保留为rk-collection。在 Body 标签下选择‘原始’,并将以下内容输入为请求体:
{
"vectors": {
"size": 1536,
"distance": "Cosine"
}
}请注意:如果您使用的是OpenAI的文本嵌入功能,尺寸应为1536。如果您使用其他平台进行文本嵌入,请您确认其尺寸。
现在点击‘发送’,它将在Qdrant中创建一个集合。您可以通过进入您的Qdrant账户和仪表板进行验证。
现在我们可以在ServiceNow中实施我们的项目了。
在ServiceNow中的实施
创建出站 REST 消息
首先,我们将在ServiceNow中创建一对Outbound REST消息。为此,我们将转到System Web Services -> Outbound -> REST Message。
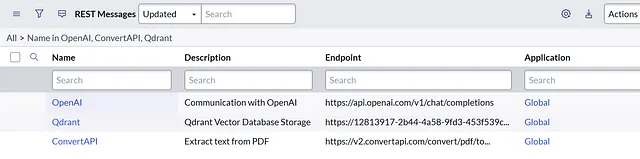
OpenAI
端点:https://api.openai.com/v1/chat/completions
在HTTP请求下,我们将有2个头部:名称:Authorization,值:Bearer >名称:Content-Type,值:application/json
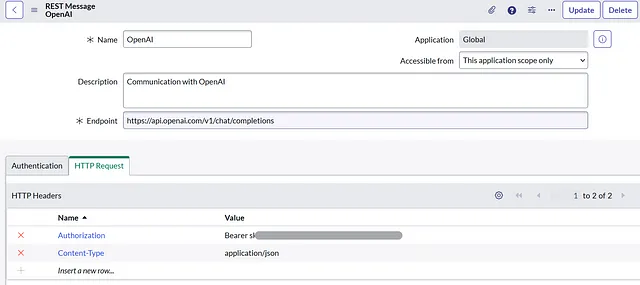
在相关列表中,我们将创建2个HTTP方法。

聊天与文件 HTTP方法:POST 端点:> 内容:
{
"model": "gpt-3.5-turbo",
"messages": [
{
"role": "system",
"content": "I am providing you context and question delimited by triple hash '###'. Please give me answer with relation to the context. Do the analysis if required"
},
{
"role": "user",
"content": "${question}"
}
]
}gpt_embeddingsHTTP 方法:POST端点:https://api.openai.com/v1/embeddings内容:
{
"input": ${arrayOfTexts},
"model": "text-embedding-ada-002"
}已完成OpenAI的REST信息。现在我们将为ConvertAPI创建另一个REST信息。
转换API
终点:https://v2.convertapi.com/convert/pdf/to/txt
在HTTP请求下,我们将有一个头部:名称:Content-Type,值:application/json。
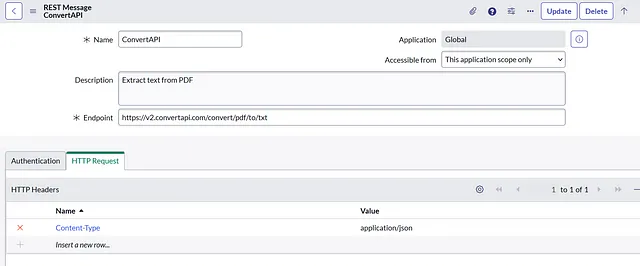
在相关列表中,我们将创建一个HTTP方法。

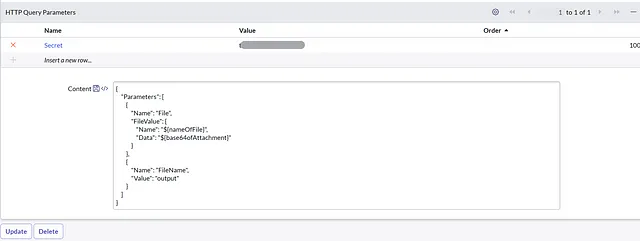
将以下英文文本翻译为简体中文,保留 HTML 结构: convert_pdf_to_text HTTP 方法:POST 端点:> HTTP 查询参数:名称:Secret,值:> 内容:
{
"Parameters": [
{
"Name": "File",
"FileValue": {
"Name": "${nameOfFile}",
"Data": "${base64ofAttachment}"
}
},
{
"Name": "FileName",
"Value": "output"
}
]
}
完成了用于ConvertAPI的REST消息。现在我们将为Qdrant创建另一个REST消息。
Qdrant四分之一
终点:>我们将在每个HTTP方法中提供终点。
在HTTP请求下,我们将有2个头部:名称: api-key,值: >名称: Content-Type,值: application/json
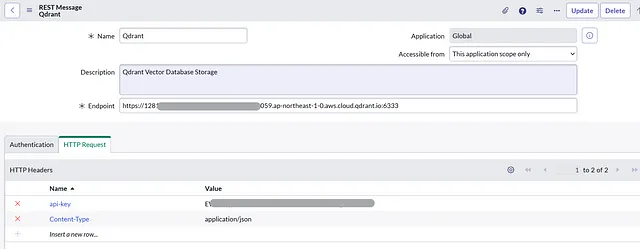
在相关列表中,我们将创建3个HTTP方法

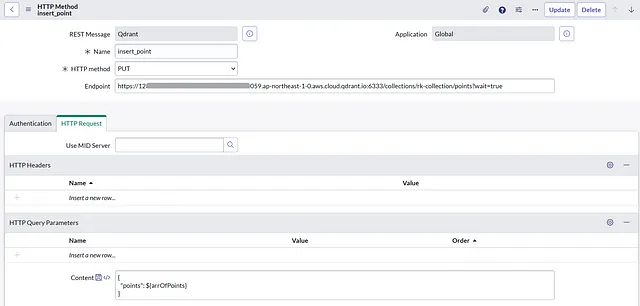
插入点HTTP方法:PUT端点:>/collections/>/points?wait=true内容:
{
"points": ${arrOfPoints}
}
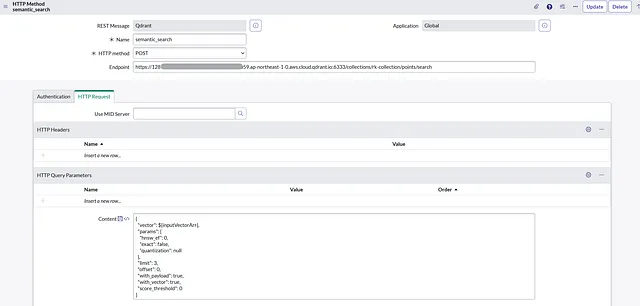
语义搜索 HTTP方法:POST 端点:>/collections/>/points/search 内容:
{
"vector": ${inputVectorArr},
"params": {
"hnsw_ef": 0,
"exact": false,
"quantization": null
},
"limit": 3,
"offset": 0,
"with_payload": true,
"with_vector": true,
"score_threshold": 0
}
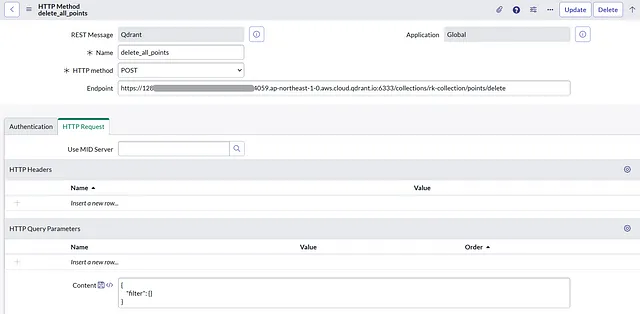
delete_all_points HTTP方法:POST 端点:>/collections/>/points/delete 内容:
{
"filter": {}
}
我们已经完成了创建所有必需的出站REST消息的工作。
创建脚本包含和所需的函数
首先,我们将在ServiceNow的sys_properties表中创建一个属性,用于存储附件的base64编码。我们这样做是为了验证同一文件不会被重复嵌入。
属性名:gpt.attachment.embededType :字符串
现在,我们将在ServiceNow中创建一个脚本包含,并在其中创建一些函数。
脚本包含名称:gptUtilsClient 可调用:已选中
首个功能: embedDocument 这个功能将在用户上传PDF后执行。它将从PDF中提取文本。将其分割成块。嵌入并存储在Qdrant集合中。
embedDocument: function(sysAttID) {
//Extract Base64 of the attachment
var attachmentIS = new GlideSysAttachmentInputStream(sysAttID);
var byteArrayOS = new Packages.java.io.ByteArrayOutputStream();
attachmentIS.writeTo(byteArrayOS);
b64attachment = GlideBase64.encode(byteArrayOS.toByteArray());
//Send Attachment to ConvertAPI and get fullText
var rawText = new fileConversionUtils().pdfToText(sysAttID);
var fullText = rawText.replaceAll(/\s+/g, ' ').trim();
//parse full_text into chunks array using my own function
var textChunks = split_in_chunks(fullText);
//Send chunks to OpenAI and get the Index and embeddings
if (gs.getProperty('gpt.attachment.embeded') != b64attachment) {
gs.setProperty('gpt.attachment.embeded', b64attachment);
var qdrantPointsArr = createPayloadForQdrant(textChunks);
//Clean the collection first
var rDelQdrant = new sn_ws.RESTMessageV2('Qdrant', 'delete_all_points');
response = rDelQdrant.execute();
//Send Chunk text and Embeddings to QdrantAPI
var rQdrant = new sn_ws.RESTMessageV2('Qdrant', 'insert_point');
rQdrant.setStringParameterNoEscape('arrOfPoints', JSON.stringify(qdrantPointsArr));
response = rQdrant.execute();
responseBody = JSON.parse(response.getBody());
if (responseBody.status == 'ok') {
return "Successfully Embeded and stored in Vector Database ! Please continue with the Chat";
} else {
return "Error on Building Points : " + JSON.stringify(responseBody);
}
}else{
return "This file is already Embeded ! Please continue with the Chat";
}
//====================================
//Functions Section
//====================================
//Function to Embed Text Chunks and return a Qdrant Payload
function createPayloadForQdrant(textChunks) {
var rEmbed = new sn_ws.RESTMessageV2('OpenAI', 'gpt_embeddings');
rEmbed.setStringParameterNoEscape('arrayOfTexts', JSON.stringify(textChunks));
response = rEmbed.execute();
responseBody = JSON.parse(response.getBody());
var arrayOfEmbeddings = responseBody.data;
var qdrantPointsArr = [];
//Prepare Qdrant Payload(Array of Objects)
arrayOfEmbeddings.forEach(function(embed) {
qdrantPointsArr.push({
"id": embed.index,
"vector": embed.embedding,
"payload": {
"text": textChunks[embed.index]
}
});
});
return qdrantPointsArr;
}
//Function for spliting text in small chunks
function split_in_chunks(text) {
var chunks = [];
var start = 0;
var data_size = 512;
var end = start + data_size;
var actualEnd = end;
var chunk_size;
while (end <= text.length()) {
chunk_size = 100; //its actually chunk_overlap
if (String.fromCharCode(text.charAt(end - 1)) === '.') {
chunks.push(text.substring(start, end).trim());
} else {
while (end > start && String.fromCharCode(text.charAt(end - 1)) !== '.' && chunk_size > 0) {
end--;
chunk_size--;
}
chunks.push(text.substring(start, actualEnd).trim());
}
start = end;
end = start + data_size;
actualEnd = end;
}
chunks.push(text.substring(start, text.length()).trim());
return chunks;
}
},第二个功能:chatWithDocument 这个功能将用于在我们的Qdrant数据库中进行语义搜索,并将带有上下文的问题传递给GPT。这将返回最终答案。
chatWithDocument: function(prompt){
var promptInArr = '["' + prompt + '"]';
//Embed prompt into vector using OpenAI embeddings
var rEmbed = new sn_ws.RESTMessageV2('OpenAI', 'gpt_embeddings');
rEmbed.setStringParameterNoEscape('arrayOfTexts', promptInArr);
response = rEmbed.execute();
responseBody = JSON.parse(response.getBody());
var promptEmbedVector = responseBody.data[0].embedding;
//Search for similarity in Qdrant Vector Database and get the contexts
var rSearch = new sn_ws.RESTMessageV2('Qdrant', 'semantic_search');
rSearch.setStringParameterNoEscape('inputVectorArr', JSON.stringify(promptEmbedVector));
response = rSearch.execute();
responseBody = JSON.parse(response.getBody());
var chunks = [];
var similarChunkPaylodArr = responseBody.result;
similarChunkPaylodArr.forEach(function (payload){
chunks.push(payload.payload.text);
});
var bigMergeChunkContext = "";
chunks.forEach(function (chunk){
bigMergeChunkContext += chunk + " --- ";
});
var rawPromptWithContext = "###Context: " + bigMergeChunkContext + "### " + "###Question: " + prompt + " ###" + "Answer: ";
var promptWithContext = rawPromptWithContext.replaceAll(/\s+/g, ' ').trim();
promptWithContext = promptWithContext.replaceAll("\n", " ");
promptWithContext = promptWithContext.replaceAll("\r", " ");
var r = new sn_ws.RESTMessageV2('OpenAI', 'chat_with_document');
r.setStringParameterNoEscape('question', promptWithContext);
response = r.execute();
responseBody = JSON.parse(response.getBody());
var gptReply = responseBody.choices[0].message.content;
return gptReply;
},完成使用脚本包含。
在虚拟代理中共同实现
前往虚拟代理设计师。创建一个新主题(假设为“GPT文件聊天”)。在开始后插入一个“文件选择器”组件。在文件选择器属性中将“允许用户上传”设置为“所有文件类型”。然后在文件选择器后添加一个脚本组件。
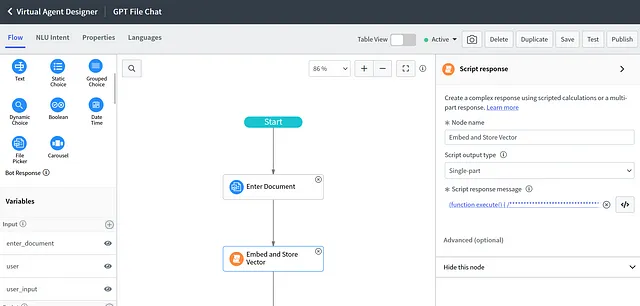
在左下角的部分,插入一个名为"用户输入"的输入变量,并插入两个名为"嵌入输出"和"GPT输出"的脚本变量。之后,我们将在机器人响应的"脚本"组件中编写脚本,在"脚本响应消息"下方。
(function execute() {
//Get the sysID of Attachement Record
var attachmentID;
var attGR = new GlideRecord('sys_attachment');
attGR.addQuery('table_name', 'sys_cs_conversation_task');
attGR.addQuery('sys_created_by', gs.getUserName());
attGR.orderByDesc('sys_created_on');
attGR.setLimit(1);
attGR.query();
if(attGR.next()){
attachmentID = attGR.getUniqueValue();
}
//Call Script include function to extract text, embed and store embeddings to Vector Database (Qdrant)
var replyFromEmbedScript = new gptUtils().embedDocument(attachmentID);
vaVars.embedOutput = replyFromEmbedScript;
})()然后添加一个机器人响应的“文本”组件,并以上一个脚本返回的结果进行回应,即脚本输出embedOutput。
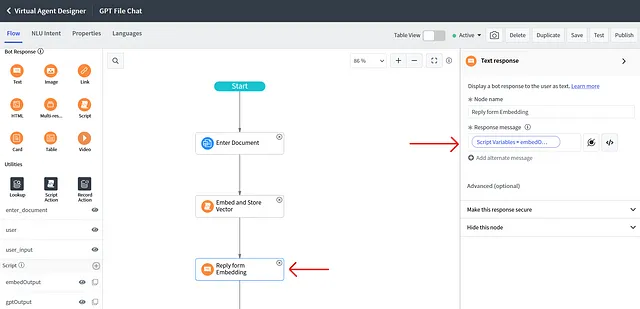
根据下面的屏幕截图添加流程逻辑。
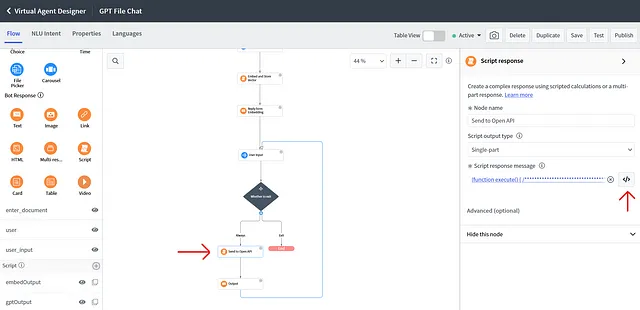
创建一个用户输入组件,然后创建一个决策实用工具组件。用户输入将从用户那里获取问题,然后决策实用工具将决定用户是否输入了除了“退出”以外的任何内容。如果是,则继续流程,否则退出聊天。如果用户输入的内容不是“退出”,则继续流程并创建另一个Bot响应“脚本”组件。在“脚本响应消息”中编写脚本,进行语义搜索并从GPT返回答案。
(function execute() {
var replyFromGPT = new gptUtils().chatWithDocument(vaInputs.user_input);
vaVars.gptOutput = replyFromGPT;
})()这里的 'user_input' 是之前创建的输入变量。它应该包含来自输入组件的用户输入。我们将 GPT 的回复存储到 'gptOutput' 脚本变量中。创建另一个机器人响应 '文本' 组件,并在响应消息中附上来自 GPT 变量(gptOutput)的回复。
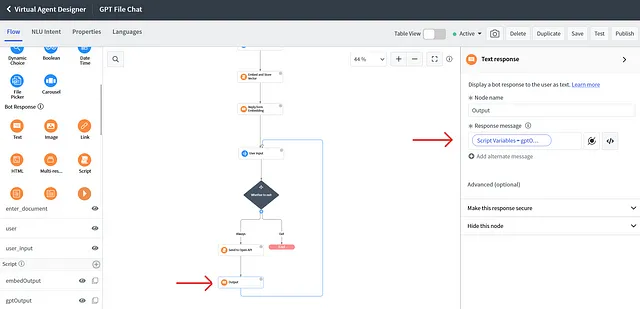
将其与用户输入连接起来,这样聊天会在回复后继续进行。
这就是全部了。恭喜!!现在你有一个在ServiceNow中的ChatGPT聊天机器人,它将根据你的文档进行分析并作出回复。
在ServiceNow中的AI未来
ServiceNow未来在AI方面,尤其是整合OpenAI的ChatGPT API,将为用户交互和工作流管理带来一次范式转变。通过利用ChatGPT的高级自然语言处理能力,ServiceNow可以提供更直观、更类似人类的交互方式,以提升用户体验和简化复杂任务。AI驱动的虚拟代理现在可以更加上下文感知地理解和回应查询,从而在各种服务流程中推动效率和生产力。凭借ChatGPT API,ServiceNow在以AI驱动的服务管理方面处于领先地位,为企业及其客户提供更智能和个性化的解决方案。
结论
在一个时间对要紧的世界里,数据量十分庞大,OpenAI嵌入和语义搜索的整合提供了一个具有改变游戏规则的解决方案。它赋予用户快速提取洞察和信息的能力,最终提高生产力、改善决策,并增强客户满意度。当我们踏上这个激动人心的革新ServiceNow体验之旅时,无限的可能性展现在我们面前,未来看起来比以往任何时候都更加光明。这个小的实施只是更多创新想法的开端。想象一下,如果您能以更先进的方式实现它,比如检测发票中的欺诈,分析报告中的图形数据并相应地处理工作。还有很多待探索的可能性 😉。