员工搜索与OpenAI、Flowise和LangChain

如果你读过我的之前的文章,你就会知道我在Slack中有一个名叫W'kid Smaaht(“超级聪明”)的波士顿版本的ChatGPT。我的团队都在Slack中活动,所以在那里有一个AI机器人是很有意义的。你可以自己安装W'kid Smaaht……并且如果你不是波士顿的粉丝的话,你还可以改变它的个性。
对于这个练习,我想要添加一项每个大型公司都需要的功能:通过技能搜索员工。这也似乎是了解更多检索增强生成(RAG)的好方法。
我所能想到的最简单的MVP是从我们的面向公众的网站上爬取员工简介,进行分块、存储并创建一个对话代理。我的目标是尽快实现惊艳效果,而不担心每一个细节都完美无缺。
步骤1 - 让GPT编写一些代码
为什么要编写一个屏幕抓取器,当GPT可以为我完成呢?只需要向我的AI朋友发送几条私信即可。这里是一些聊天的截图,最后附上了最终的脚本。

这个方法有效,但是它没有提取到正确的内容。

问题。向GPT投诉。
#2是一个好主意:“检查HTML结构”,所以我给了GPT一些额外的情报。
它起作用。很好。但是我只想要传记文本。请W'kid Smaaht提取特定div标签中的文本。

酷,但我只得到大约十几个文本文件。为什么?啊,这个网站有一个无限滚动功能。我该如何处理?

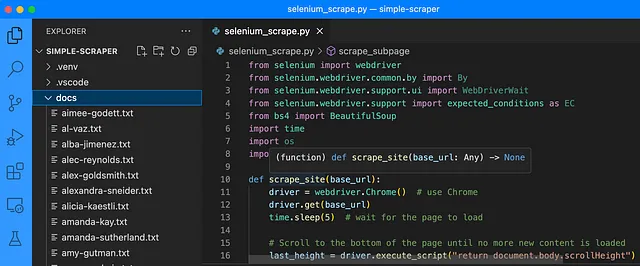
这里是代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import time
import os
import requests
def scrape_site(base_url):
driver = webdriver.Chrome() # use Chrome
driver.get(base_url)
time.sleep(5) # wait for the page to load
# Scroll to the bottom of the page until no more new content is loaded
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2) # wait for new content to load
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
soup = BeautifulSoup(driver.page_source, 'html.parser')
people_grid = soup.find('div', {'class': 'people-grid__grid people-grid__grid--big', 'id': 'people'})
for link in people_grid.find_all('a', {'class': 'people-grid__link'}):
url = link.get('href')
if url and url.startswith('http'):
scrape_subpage(url)
driver.quit()
def scrape_subpage(url):
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
text_div = soup.find('div', {'class': 'redactor redactor--dropcap'})
if text_div:
text = text_div.get_text(strip=True)
page_name = url.split('/')[-1]
name = ' '.join(word.capitalize() for word in page_name.split('-'))
with open(f'docs/{page_name}.txt', 'w') as f:
s = f"{name}. {text}"
f.write(s)
base_url = 'https://www.flagshippioneering.com/people/directory' # replace with your URL
scrape_site(base_url)我将代码保存为selenium_scrape.py,创建了一个虚拟环境,使用pip安装了所需的库,安装了chromedriver,并让它运行。代码一开始就正常工作了,为每个员工创建了一个单独的文件,其中包含从网站上获取的他们的个人简介。
步骤2 — 分块、生成嵌入和存储
下一步是将个人简介切分并加载到向量存储(数据库)中。但是我以前从未使用过向量存储,所以我不知道自己不知道的。好消息是,我们正处于即时学习的时代,学习基本内容不需要很长时间。
您可以在网上找到很多关于向量商店的教程,所以本文不会重复使用的原因。只需知道当寻找与给定搜索词在语义上相似的信息时,它们非常有用。例如,使用术语“生物学”进行查询可能会返回“分子生物学”,“生物化学”等记录。
LangChain有一篇关于向量存储的绝佳入门文章,并支持几种最流行的存储方式。我选择了Pinecone,因为我希望使用一款易于使用且免费的SaaS(而不是本地或内存存储方式)来实现MVP。
注册后,我开始创建一个索引,并立即遇到瓶颈;这需要多少个维度?结果表明,答案来自OpenAI的嵌入模型-1536个。当然还有其他考虑因素,但这已足够继续前进。
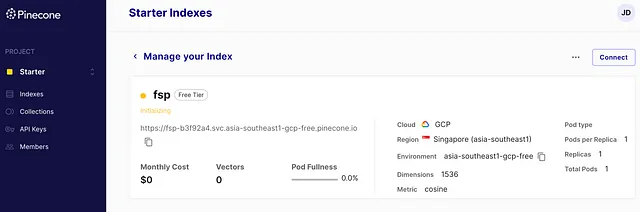
很好。我有内容和向量存储。我该如何加载数据?
输入Flowise
在搜索LangChain教程时,我偶然发现了Leon van Zyl关于Flowise的奇妙视频系列,Flowise是一个无代码工具,可以创建LLM应用程序并嵌入许多LangChain功能。通过观看视频和使用Flowise的示例,我能够在不到一个小时内创建一个Pinecone加载器和一个与我的数据交互的聊天机器人。更令人高兴的是,看到各种组件如何相互连接帮助我更好地理解LangChain。
开始只需fork Flowise,克隆该项目,并按照README进行配置就可以了。
加载器
为了加载文档,我按照Leon的教程创建了一个Flowise的“聊天流”,并在过程中进行了调整。
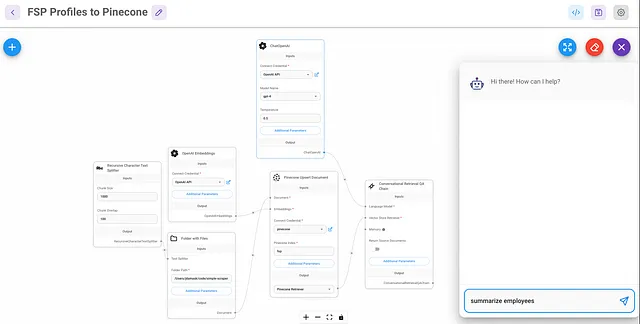
您可以看到这个概念非常简单。遍历文件夹中的文件,根据一些规则进行读取和拆分,为每个文件创建嵌入,并更新或插入数据。
在这个流程中,一次聊天触发了加载 - 这是一个奇怪的用户体验 - 但无论如何,MVP(最小可行产品)是为了快速获得可工作的东西,而不是追求优雅。大约在几分钟内处理了约300个人的简历。
步骤三 — 制作搜索应用
我们希望为员工搜索创建一个独立的流程,因为这是一个一次加载、多次查询的设计。如果将它们合并为一个流程,每个会话都会触发重新加载所有数据。
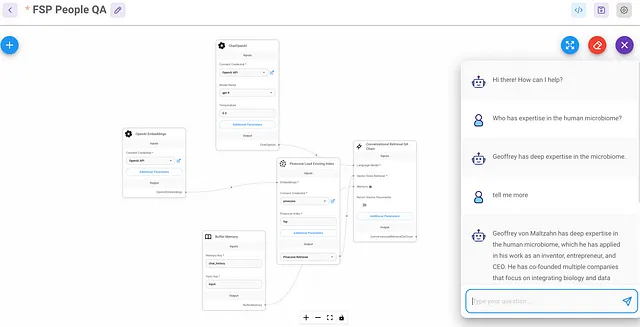
这几乎是再简单不过的了。
步骤4 — 将应用程序公开为API
现在怎么办?Flowise在我的Mac上运行,但我需要它在一个Web服务器上。理想情况下,它将是一个在同一个AWS账户中运行的docker容器,就像W'kid Smaaht一样,但是Flowise还没有提供ECS部署文件,所以我选择了一个更简单的解决方案。Render。
Leon的Flowise AI教程#5 - 部署到Render让我达到目标。在设置了免费的Render账户并配置了基本设置后,我将其连接到了我的衍生Flowise仓库,并创建了一个新的Render网络服务(Node)。
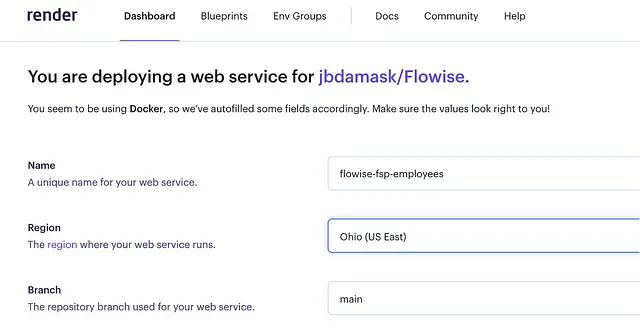
大约十分钟左右,服务已经启动。
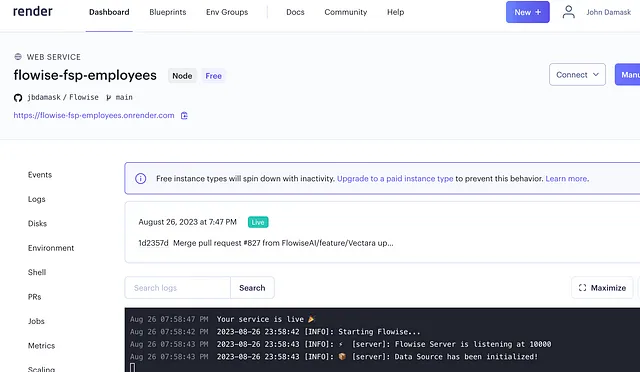
刚刚发生了什么?有很多事情。但我并不需要知道其中大部分的细节。Render创建了基础设施,安装了Flowise,并在公共URL后面进行了暴露。现在,我可以通过Render访问Flowise,就像在我的笔记本电脑上一样。
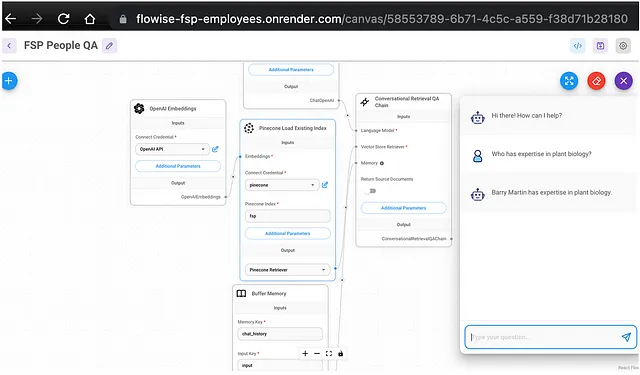
接下来,我导出了我本地版本的FSP People QA聊天流程,并将其导入到在Render上运行的Flowise中。当您导出/导入单个聊天流程时,API密钥不会复制过来,因此我在Render Flowise中重新创建了OpenAI API和Pinecone凭据,并将它们添加到了聊天流程中。
成功!
API (应用程序接口) 是一组定义了不同软件组件之间交互的规则和协议。它允许不同的应用程序之间共享数据和功能,同时确保其安全性和可靠性。API可以用于访问各种不同的服务和资源,如数据库、网络服务和操作系统功能。通过使用API,开发人员可以更轻松地构建应用程序,并促进应用程序之间的集成和互操作性。
但是我不想要一个网页界面,我想要一个API。为了做到这一点,我按照Leon关于使用Flowise终端的另一个教程进行操作。
很容易用新的密钥保护终端,并获取方便的参考Python代码添加到我的应用程序中。要查看整个函数,请查看W’kid Smaaht的17-add-flowise-fsp-emp-directory-api-calls分支中的localsrc/utils.py文件。
为了测试它,我添加了一个小的钩子,用于查找以“:fsp”开头的消息,并将输入传递给API。
所以,W'kid Smaaht更聪明吗?是的。

不错。但这并不是很有用。除非我们了解约翰和迪恩,否则我们无法获得足够信息来对我们有意义地提供帮助。如果这包括他们的个人简介页面链接会更好。
原来可以通过在聊天流程的“交谈检索 QA 链”小部件中启用“返回源文档”选项,并解析元数据来完成此操作。
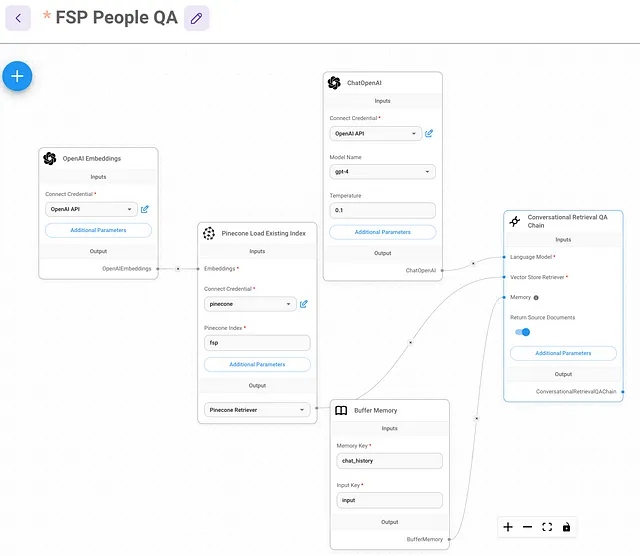
一旦启用,我在调试器中检查了对象结构,以了解哪个字段包含了源代码。但是等一下...源代码是被分块并上传到Pinecone的文件。我需要一个URL。
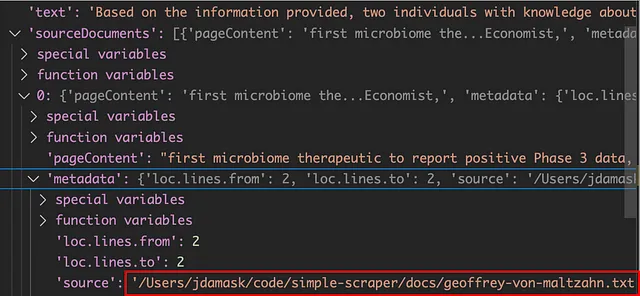
这个很容易调整。因为我们知道文件名是从页面URL获取的,所以我们可以把它转换回来。只需将 "source" 字符串分割,并将用户名附加到我的公司URL上。然后,我们可以将修改后的列表与文本响应一起传递回Slack。

这个更好一些,但还是有点奇怪。我更希望超链接嵌入在字符串中。但编写这个逻辑并不直接,因为有些个人简介包括了人的全名,而其他人则没有。例如,博士简·杜可能出现为“博士简·杜”,“杜博士”,“简·杜”,或仅为“简”。我该如何解决这个问题呢?嗯...
呵呵,等一下...我在想什么呢?LLM在这方面非常擅长,而LangChain使得只需要几行代码就能轻松实现。
将ChatPromptTemplate、SystemMessagePromptTemplate和HumanMessagePromptTemplate包含在以下代码中。
from langchain.prompts import ChatPromptTemplate
from langchain.prompts.chat import SystemMessagePromptTemplate, HumanMessagePromptTemplate接下来,为系统和人工聊天添加提示模板,并制作它们的聊天提示。请注意,提示指定返回按照Slack约定格式化的字符串。这是因为Slack对超链接的编码方式是独特的。
system_template = """You take a string and a python list of URLs \
and do your best to attach the URLs as hyperlinks to their \
proper locations in the string. The string return is the same as the text \
string that was provided to you, but with hyperlinks inserted into the right places. \
The string you return must have its hyperlinks formatted according to \
Slack convention.
Example:
<https://flagshippioneering.com/people/drew-dresser|Drew> and <https://flagshippioneering.com/people/sean-murphy|Sean> \
have experience with AWS
"""
# create a prompt template for a System role
system_message_prompt_template = SystemMessagePromptTemplate.from_template(
system_template)
# create a string template for a Human role with input variables
human_template = "{text} {urls}"
# create a prompt template for a Human role
human_message_prompt_template = HumanMessagePromptTemplate.from_template(human_template)
# create chat prompt template
chat_prompt_template = ChatPromptTemplate.from_messages(
[system_message_prompt_template, human_message_prompt_template])
# generate a final prompt by passing variables (`text`, `urls`)
final_prompt = chat_prompt_template.format_prompt(text=rt, urls=sl).to_messages()最后一步是再次调用OpenAI的API,让LLM重新格式化字符串。出于速度考虑,并且因为这似乎是正确的一致性,我调用的是gpt-3.5-turbo而不是gpt-4。
llm = ChatOpenAI(model_name='gpt-3.5-turbo', openai_api_key=OPENAI_API_KEY, streaming=False)
response_string = llm(final_prompt)
return response_string.content现在结果被Slackified了!
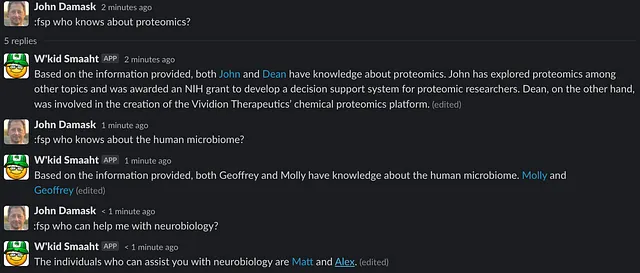
如你所见,结果并不总是完美的,但它确实是不错的,肯定比原始的URL要好些。
直到产品发布才算结束
这是另一个用于熟悉LLM申请写作的实验。工具集让这个过程变得快速而有趣,但是真正的辛勤工作现在才开始 —— 按照现在的状态,我绝不会将其投入生产使用。
我还没显示出我在向量存储和GPT中获得一致且完整结果方面遇到的问题。与传统的数据应用不同,这更像是一种艺术而不是科学,但我承认其中一部分原因是我对它们缺乏经验。
此外,来自Pinecone和LLMs的回答并不是确定性的,因此需要编写大量的条件和错误逻辑,这可能会很困难。但也许我需要调整我的思考方式,从编码问题转向写更好的提示或利用代理来为我进行推理。我们拭目以待。